精PostgreSQL 体系结构
Posted 最帅dba工作笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了精PostgreSQL 体系结构相关的知识,希望对你有一定的参考价值。
PostgreSQL 体系结构
2018年1月的报表
这个图选的不好啊,ORACLE现在还是在业内属于领先位置。。。毕竟我也是干Oracle的。
2018年7月的报表
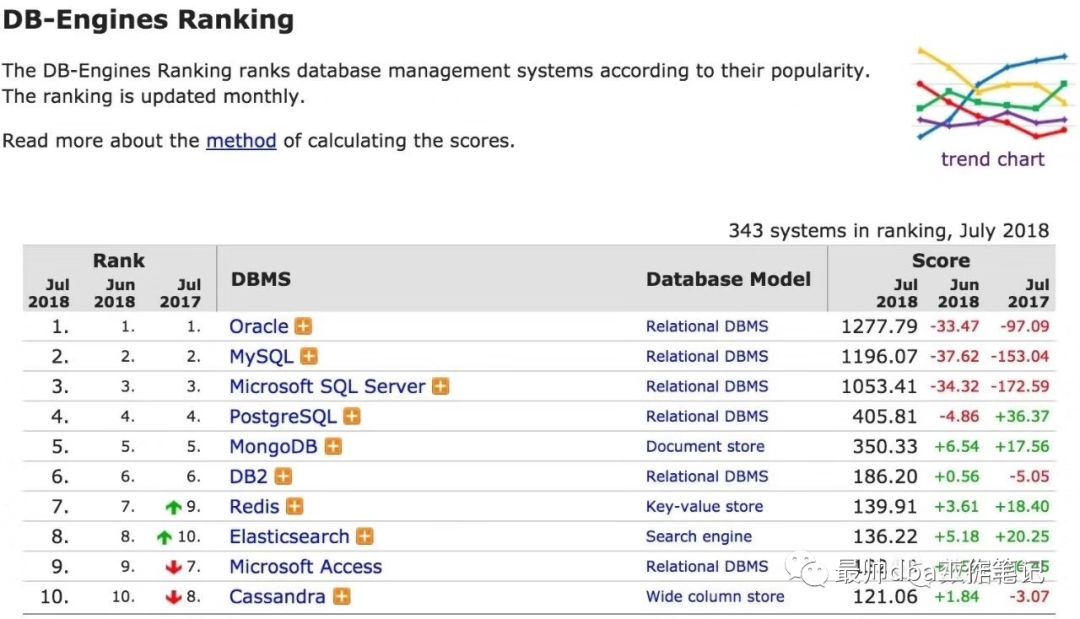
大家注意到了吧 这个不起眼的PG竟然悄悄的在以一个飞快的速度在抢占市场。。。
在给大家看一个分析,是以人们的口碑去排名,很多的人评价这款数据库是有趣!!其原因就是开源,有着丰富的接口,可以随意开发插件。哈哈哈,看来这是一款让很多的技术宅们兴奋的产品啊。
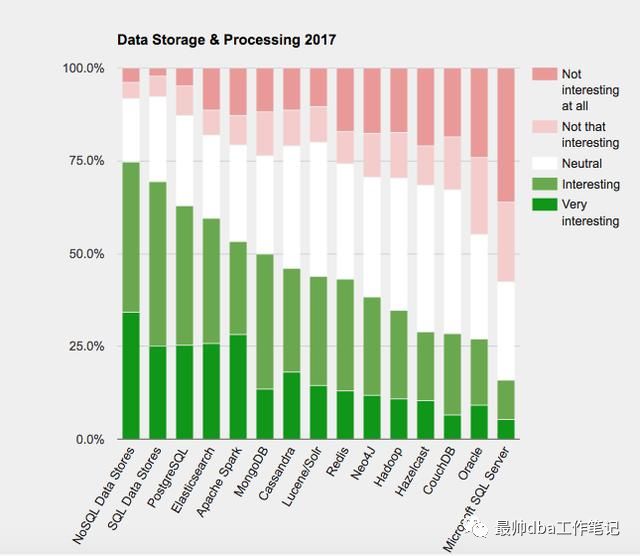
所以现在这个数据库也可能成为dba的另一个饭碗或者说是另一个技能(加薪)。
再者就是它的性能,其性能极强。或许这个才是一个企业真正关心的。。。
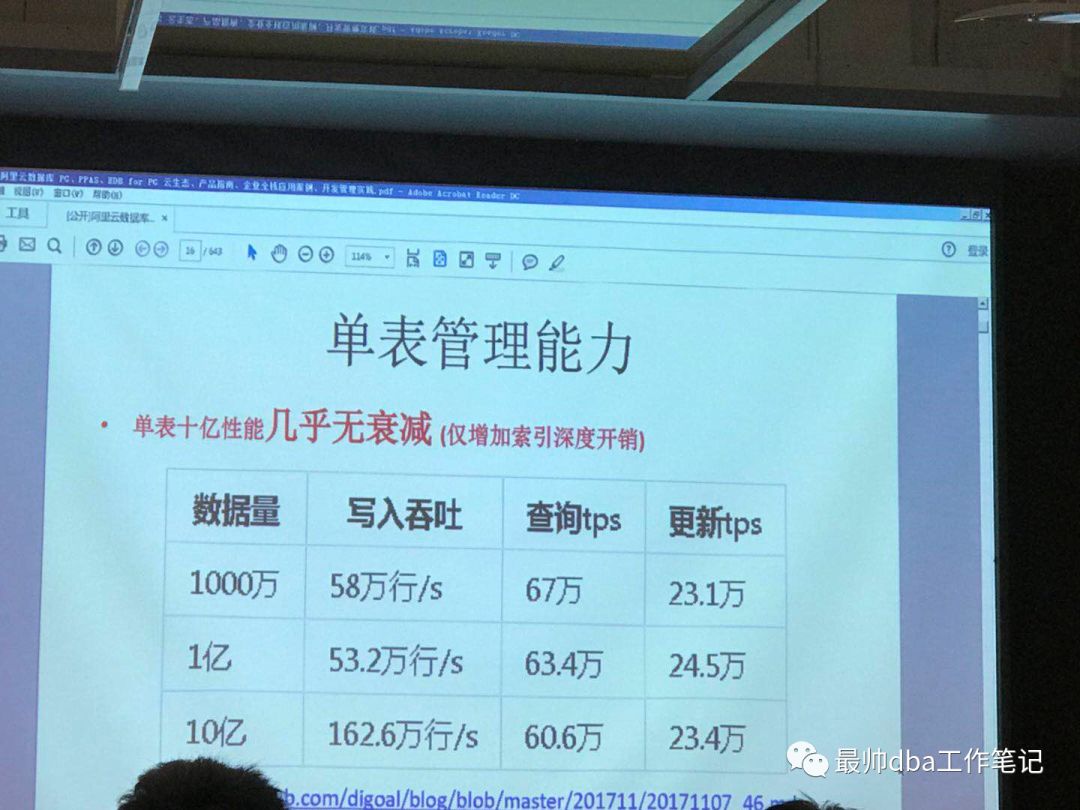
好了废话不多说,先简单的介绍一下这个数据库。
Postgresql 简称PG,是在加州伯克利分校计算机系开发的,最关键的是这个数据库免费,开源,所以有更多的可能性就是将其二次开发,自己修改。PG也支持各种平台的版本,支持标准化的SQL语句,可以自己开发添加附加功能,支持PITR,支持MVCC等等等等……。
体系结构:
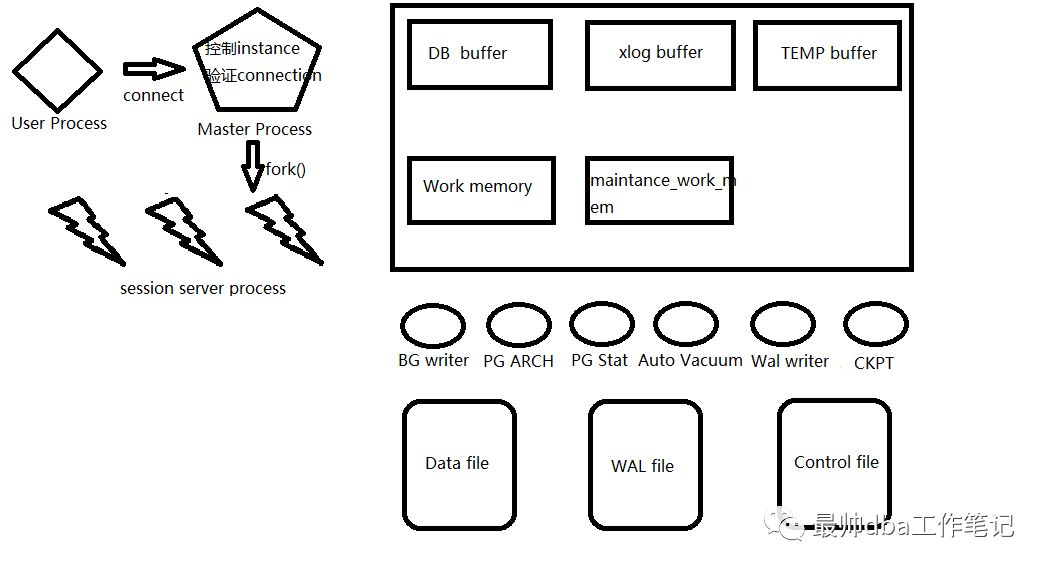
我简单的画了一个类似于Oracle的体系结构图,方便大家的理解。
PostgreSQL是一种典型的C/S的架构模式,首先它存在着典型的内存结构,后台进程,物理磁盘文件等标准。我们简单的说一下整个架构。
当用户以一个连接连到数据库服务器首先是Master Process 来进行验证,验证的是用户的密码,如果通过会向下fork()出多个连接服务进程进行连接管理。而Master Process除了验证功能之外,其还会管理整个database instance的启动和停止。
这个图是我在参加阿里云分享会当中拍到的
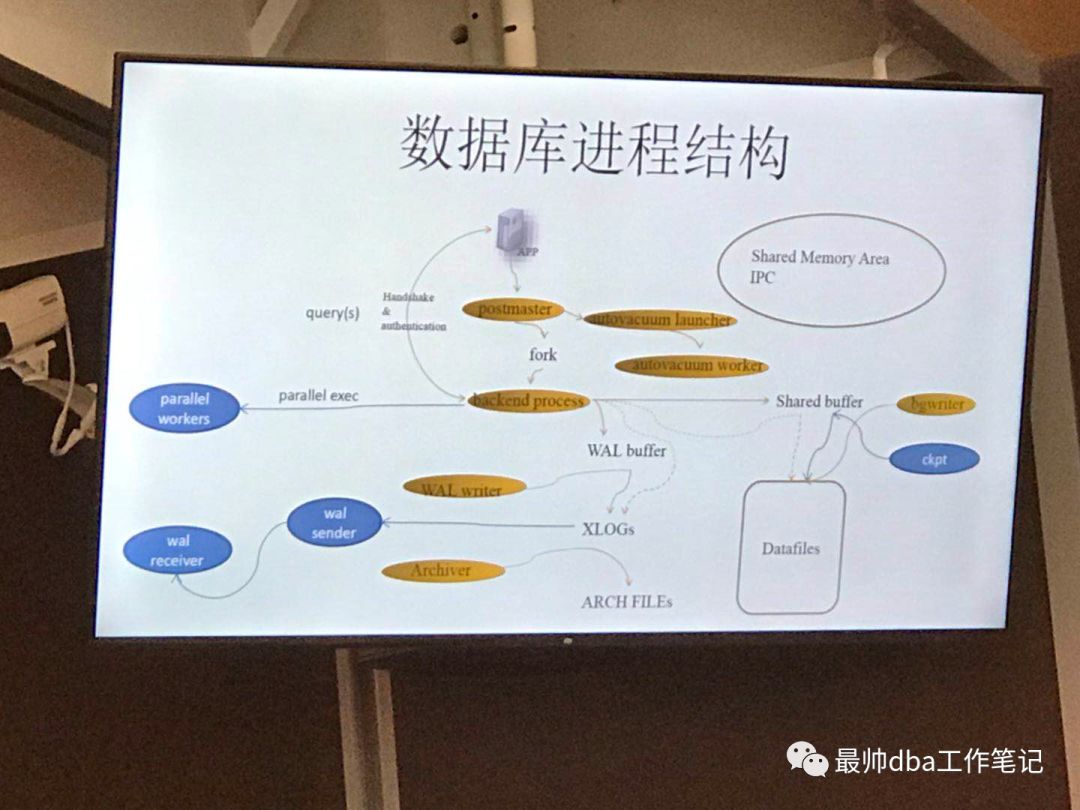
这里的wal receiver和wal sender是在集群同部的时候用到的进程,一个用于WAL日志接受,一个用于WAL日志发送。
内存部分:
PG也有自己的 mem部分,其功能和其他数据库相同,目的是为了提高事务的操作速度。这里的介绍我没有细分那些是共享的那些是非共享的,这里我在之后的学习当中会继续总结,如果有知道的朋友也麻烦跟我说一下。
DB buffer:
其作用和其他数据库类似,缓存数据页,通过BG Writer,server process将dirty page flush到disk。
xlog buffer:
还有Xlog buffer 部分,所谓的Xlog其实就是WAL日志,也就是预写日志(Write Ahead Log),这个和Oracle的redo日志的概念是一样的,所谓这里日出预写,也就是说当事务提交之后在落盘改变data file之前,要先记录日志。这个Xlog日志受wal writer进程的控制,会定期异步刷盘。
temp buffer:
这一部分是一个临时区,目的就是当session访问一个temp table 的时候会用到这里。
work_mem:
work_mem是针对排序操作和hash操作的,这里的设置一定要根据当前数据库的情况进行设置,因为如果空间不够我们知道排序工作会进入到swap交换分区里,这样的话我们速度会慢很多,而且增加io,you kown ……
maintance_work_mem:
这个部分是针对数据库的维护操作,比如说VACUUM,create index ,等操作,当有这些操作的时候会占用到这个内存区;
进程部分:
这些进程管理了我们数据库的一切常用功能,我们一一说一下:
Master Process:我们在前面说了Master Process是Pg里面最重要的一个进程,这个进程管理了数据库的启停,并且为session提供验证并且创建server process,又叫Postgres进程,从而保持session的连接。
Postgres(server process):是有Master process创建的连接进程,配合BGwriter有flush的作用。用户所有的操作从此传入,结果也从此返回。
BG writer : background writer 进程,起作用是将db buffer的dirty page flush到disk当中。当然将脏数据flush到disk的操作不仅仅是BG writer去做的,Server process也会进行flush 的操作,但是BG writer的优先级要高于Server Process。BG Writer的触发机制是受参数和CKPT影响的,参数控制的时间要短于CKPT的触发时间,这样的话相当于是在CKPT的周期之内进行了多次io,从而避免了一次io大量数据的堵塞,这个进程是在8.0版本之后才有的。
WAL writer:这里先说一下WAL writer,WAL writer 是将数据库的XLog(WAL log前面说过)buffer刷盘的。
PG ARCH:这个功能和Oracle当中的Archn归档十分的相似,我们知道Oracle当中的日志是循环写顺序写的,而PG也是如此,也是循环写顺序写。这样在循环写下一个Xlog的时候,会通过PG ARCH进程将Xlog归档。这也就意味着PG其实是支持PITR(基于时间点恢复)的。厉害了厉害了。这个和Oracle一样,是通过参数控制的。我们之后再说。
AutoVacuum process:先说下啥事vacuum,这个东西叫自动清理,清理的是啥,清理的是旧版本数据。PG支持mvcc(多版本并发控制),这个和mysql相同,就是在一个列当中增加了两个伪列,从而判断这个数据是不是我们想要的最新的数据,还是已经修改的数据,目的是为了保证事务的一致性的。比如说我们在update的时候会将一行数据表示为旧的,再把新值附上,当我们这个事务commit了。这样我们之前标记的那个update之前的数据不再需要了。还有在Postgresql当中,当delete一条数据之后,其实那条数据是被标记了,眼看的是被删除了,但是空间并没有被回收,所以我们会看到的是这个文件不停的增大,这个时候我们就要通过vacuum进程删掉,并且会自动更新统计信息。这个进程其实包括两个部分:1.vacuum launcher 2.vacuum worker ,launcher是一直收集数据库的状态,当事务的开始时间要大于参数autovacuum_freeze_max_age的时候,其会触发work去清理。
PGstat:这个进程是统计信息的收集器,将统计信息更新到了pg_statistic表当中。
CKPT:CKPT和Oracle的一样,就是直接触发日志,dbbuffer刷盘等。
SysLogger:数据库日志记录,该日志是记录数据库的报错日志,这个要区别WAL日志。大家都懂的。。。
disk:
我们先看一下存储的结构图:
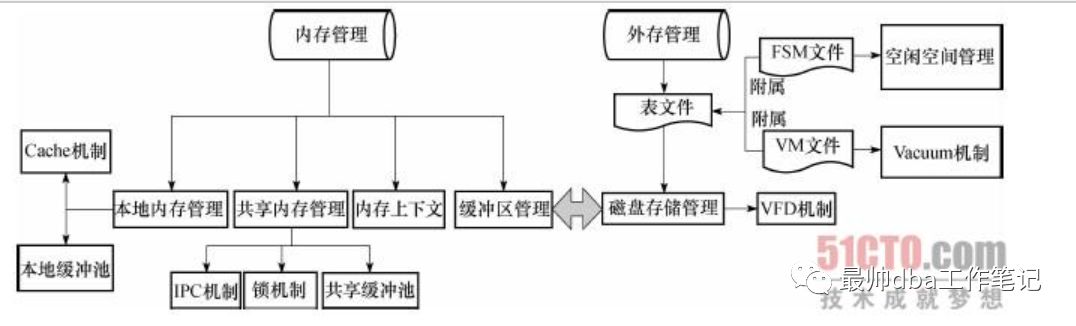
此图出自51cto
表空间:
我们看一下外存管理部分,也就是disk的部分。PG和其他数据库相同,其包含表空间这个概念,但是在PG当中其表空间的显示模式并不是像Oracle那样显示一个或者多个物理文件,PG当中的表空间文件是以一个目录的形式显示的。
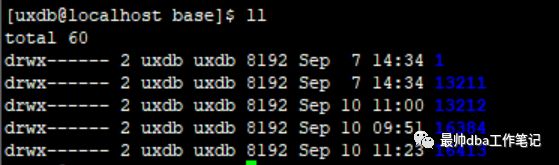
我这里的截图是我们公司的数据库,它和PG几乎一样,所以我以后的截图就按这个来截取,如果大家做实验的话,可以把这个我查询的视图的前缀UX_改成PG_即可。
在PG当中,默认的表空间文件在创建的数据库文件下的base文件下,其会以一串数字去命名,这个数字的名称是OID(这个不绝对,这个值可能时会变的)。这里简单说一下什么是OID,OID就是一个对象标识符,这个值在一个长时间运行的数据库当中有可能会是重复的,在PG当中,OID是一个隐藏列,OID在系统表当中其实就是主键。
我们想要查看一个数据库的物理文件目录的编码的话我们可以使用:
如果大家的环境是PG的话,请使用pg_Database进行查询。
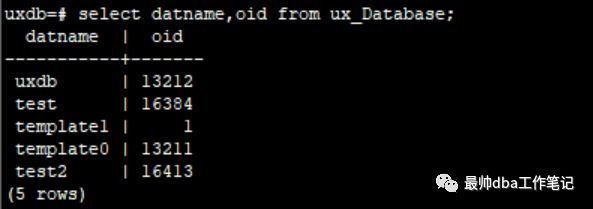
每一个目录都对应的数据库的表空间文件。
表文件:
说完表空间,再说一个特殊的是表文件,PG当中有表文件的概念,这个是区别于Oracle和Mysql的。
表文件也一样,默认创建的文件也是以当前表的OID进行命名的,但是,我们要是查询这个表的话,一定不要通过OID进行查询,因为我说过这个OID值在数据库的视图当中是会变的。我们举例查看一下。
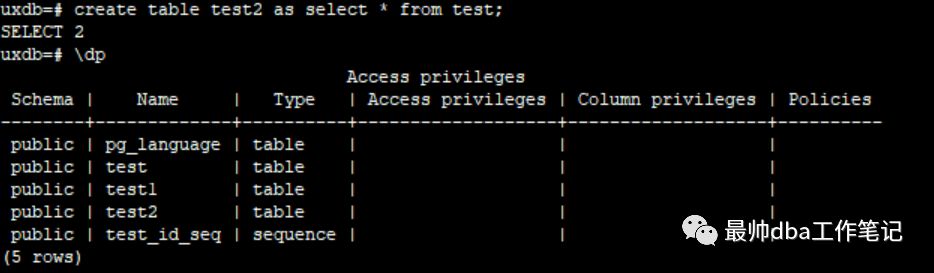

我们发现这个时候oid和filenode的值是相同的,所谓filenode值就是目前这个表在文件系统当中所记录的号码。
此时我们truncate这张表

此时我们发现,这个时候的filenode改变了,不再是之前的那个oid。所以我们在查的时候一定要注意,不光是truncate操作,当执行vacuum的时候也会有这种情况发生,这里就不多介绍了。
还有一种方法可以方便的找到一个表的表文件所在的位置:
select ux_relation_filepath('tablename');
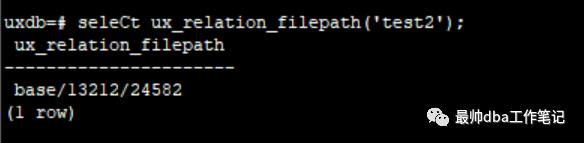
这个目录就是我们表文件的目录。
另外一种确认文件号的方法是oid2name,直接oid2name是得到数据库文件号,加参数-d databasename 是库当中的所有表信息。
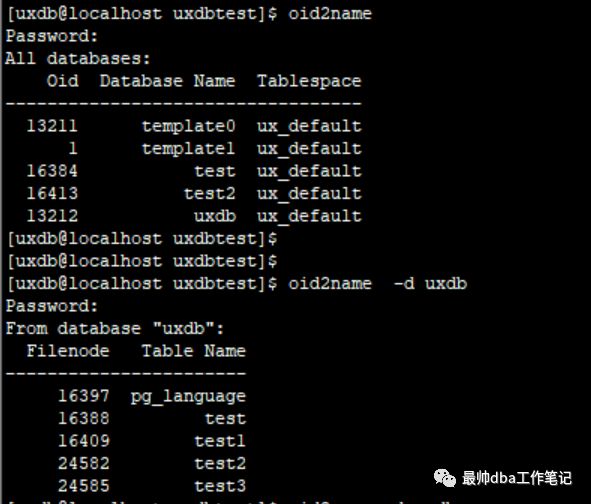
在8.4的版本之后,除了这个表目录之外,多了两个其他的文件:VM和FSM文件

VM 可见性映射表文件
FSM 空闲空间映射文件
VM文件用于加快vacuum的清理速度;FSM用于表文件空闲空间的管理。
在PG当中,每个表文件的大小根据操作系统的限制而定,FAT32的系统限制为4G,当超出过这个大小文件会自动切分多个文件进行存储。
数据页:
数据页是物理段文件的最小存储单位,默认大小8k,物理页分为三个部分:
1.Pageheader:页头,这里记录了页的一些信息,比如说lsn(这个和mysql里面的一样),校验位,等元数据信息。
2.Tuple item space: 元组数据空间,Tuple记录的是封装的事实在在的数据信息;item当中记录的是这个tuple对应的偏移量和大小,其实就是一个记录指针。
3.special space :特殊空间,用于存放索引以及索引方法相关的特殊数据。
体系结构我大致先说这么多,剩下的更深入的我会更深入的去说。
THAT'S ALL
BY CUI ~~~
以上是关于精PostgreSQL 体系结构的主要内容,如果未能解决你的问题,请参考以下文章