不用找了,PostgreSQL 12 GA的新特性都在这里!
Posted 数据和云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不用找了,PostgreSQL 12 GA的新特性都在这里!相关的知识,希望对你有一定的参考价值。
2019数据技术嘉年华于11月16日在京落下了帷幕。大会历时两天,来自全国各地上千名学术精英、数据库领袖人物、数据库专家、技术爱好者在这里汇聚一堂,围绕“开源 • 智能 • 云数据 - 自主驱动发展 创新引领未来”的大会主题,共享"开源自研,云和数据,智能运维,智能业务,数据前沿,用户实践"六大主题盛宴。
近期,小编为大家精心准备了“2019数据技术嘉年华——云和恩墨大咖系列”分享。在此次嘉年华大会上,云和恩墨专家聚焦行业热点,分析典型案例,探索数据价值,共论智能未来。
让我们跟随云和恩墨专家团来一同回顾嘉年华的精彩瞬间,领略他们眼中的数据之美吧~
2019数据技术嘉年华 刘伟先生现场演讲图
本期,我们请到云和恩墨软件开发部研究院研究员 刘伟 先生,其主要研究方向为开源数据库,分布式数据库,擅长自动化运维以及数据库内核研究。
本次嘉年华他带来题为:
PostgreSQL 12 GA的新特性详解
主题分享。下面,让我们一同来学习刘伟笔下的满满干货吧!
PostgreSQL 12终于在2019年10月3日正式宣布 GA 版本的发布。目前来看,这个版本必将是一个承上启下,为未来更强的功能奠定基础的版本了。
整体来看,这次迭代主要有三个方面的内容,它们分别是,SQL的执行优化;配置的优化;以及最重要的:存储引擎接口的独立。
比如在遇到索引数据损坏、索引膨胀、索引的创建选项变更、无效索引重建等情况,在之前版本中,重建索引需要在表上加全局只读锁,阻止其他会话的写入。而在现在,则通过一个细分的多步事务操作,避免了这个问题,具体如下:
2. 在临时索引上开始插入数据,这里需要注意的是,如果是重建表上的所有索引,那么这里也会同时创建对应数量的临时索引。
3. 当前一步插入数据完成,再插入创建索引期间产生的新的数据。
4. 所有数据都插入完毕后,使用临时缩影替换掉原先的索引。
在数据库的使用中,难免会遇到需要的数据库表的某一列或者某几列使用函数生成的数据。这种时候,如果每次都是实时地进行运算,那么这个计算代价比较大,尤其是表非常大的时候。
生成列的出现就是为了解决这个问题。每当数据插入数据库表的时候,对于生成列来说,就会生成其对应的数据,而不需要用户的明确输入,当然实际上用户也无法输入。
但是目前这个功能的实现也不是万能的,它存在很多的限制。下面我列出其中一些:
第三个重要的变更:
优化器层面的处理,即CTE的inline优化。
CTE
,实际上指的就是with语法指定的在主SQL语句前面的查询,通常会作为临时表提供给主查询结构使用。
在之前的实现形态中,执行时候会首先查询出来CTE内的数据作为临时表,然后去对执行主查询对应的操作,而在PostgreSQL 12中,这里进行了名为inline的优化:
如果ctw表达式指定的表,在主查询中制备使用了一次,那么,数据库会直接使用子查询,而非预先查询的方式来执行之后的查询与处理,这里与c等编程语言的inline意味类似。
通过子查询进行进一步的优化,可以很大程度地提升性能。
这个特性也可以人工控制,对于一些不满足条件的CTE也进行inline处理(MATERIALIZED),或者对满足条件的情况下,依然不使用inline方式处理(NOT MATERIALIZED)。
第四个重要的变更:
缓存执行计划,目前虽然未见得有多么重要,但在未来,可能会有很大作用的一个功能。
众所周知,Oracle是缓存执行计划的,而类似mysql,PostgreSQL这些开源数据库,都是SQL语句每次现场解析来处理的。而现在,PostgreSQL 12中,首先做到了执行计划的缓存———虽然这个功能影响范围目前十分有限:
目前只有明确使用了prepare语句,创建了临时过程,或者干脆就是存储过程PL/pgSQL,否则无法使用到缓存的执行计划,远远达不到像Oracle那样,普通SQL语句都可以缓存执行计划。
但是,可以展望的未来,就势必会有这么一个优化。而这,也将是后续PG的迭代版本需要去做到的事情。
第五个重要的变更:
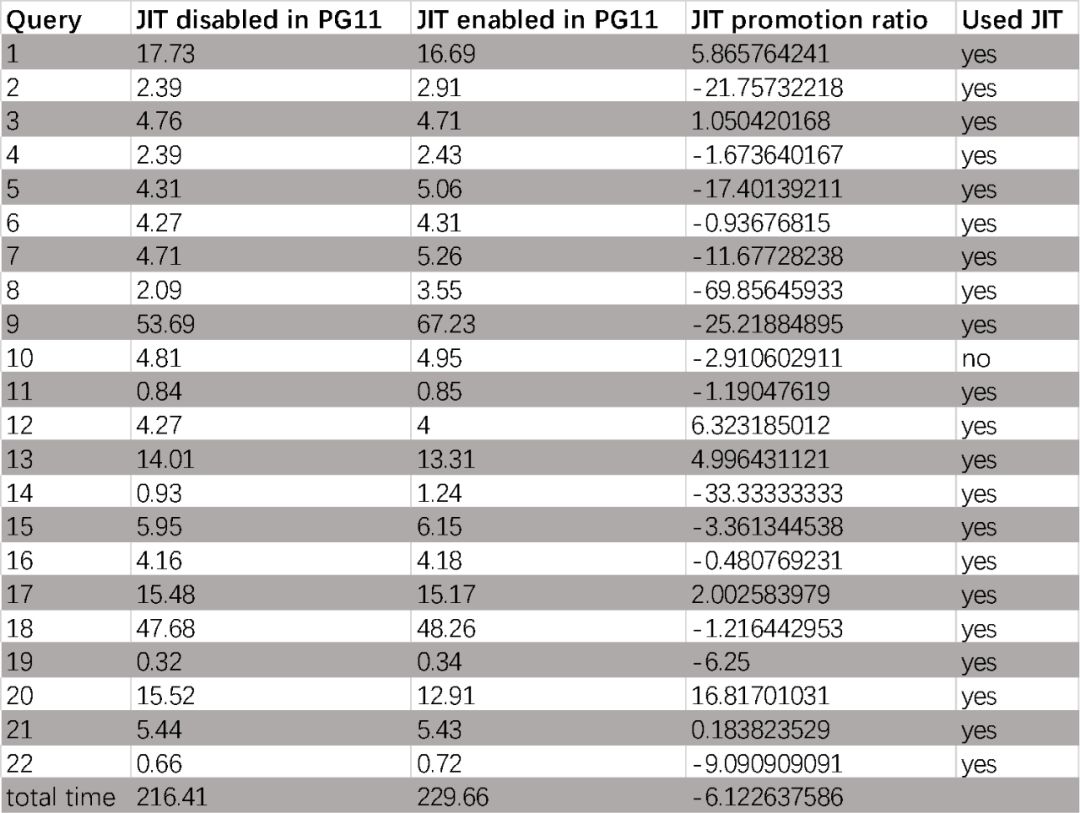
实际上是配置的变更,但其主题影响的是SQL执行,因此在这里简单说一下,就是JIT在PostgreSQL 12中,默认是打开的状态。
关于
JIT
,在这里简单描述一下:把SQL语句中的简单计算,直接编译为机器汇编码执行,效率远高于需要从SQL转C调用的普通SQL执行效率,除了需要在SQL解析阶段稍微多一点CPU之外,没有其他坏处,而打开这个特性,获得的好处是巨大的,参考图来自德哥的博客:
除了SQL优化这个开发人员最关心的话题之外,对于运维来说,PG 12这个版本也做到很多的变化。
第一个,是新增了两个管理用的视图,以及一个新的函数:
- pg_stat_progress_create_index 查看当前正在创建的索引进度
已经执行的数据块数量
已经执行的行数量
使用/等待锁的情况
- pg_stat_progress_cluster 查看当前vacuum full/cluster进度
- pg_ls_archive_statusdir() 列出归档状态文件夹内容
这个变化让DBA可以对数据库中发生的重度行为有更详细的了解,以下定更好的决策。
第二个,是我认为绝对值得大书一笔,在PG历史上留下精彩篇章的变更:
“干掉”recovery.conf文件,配置项目合并入postgresql.conf配置文件。
这个文件几乎伴随着PG的出现就已经存在了,在PG 9.0版本之前漫长的年代,这个文件负责了redo(WAL/XLOG)的回放配置,因此叫做recovery.conf。在9.0之后,流复制出现,于是理所当然地,流复制的配置,也被放到这个文件里面了。而后,实际上这个文件更多地扮演者流复制配置而非数据恢复的角色。但是,与数据恢复仅仅需要离线操作不同,流复制在很多时候,是需要有在线变更手段的,而recovery.conf不支持reload,就成了一个需要解决的麻烦事了。
在PostgreSQL开始,这个文件原先的项目合并到postgresql.conf之后,为了避免配置冲突,PG自己新增了一个强行的限制:如果检查到数据目录有recovery.conf这个文件,则不允许数据库启动。
这个合并,不仅仅是个单纯的合并,也牵扯到很多相关参数的改名以及默认值变更:
archive_cleanup_command
promote_trigger_file
recovery_end_command
recovery_min_apply_delay
相信未来的后续版本,PG主从切换之后,standby不需要重启就可以变更主库,也不是一件不可能的事情了。
这些设置当然可以极大程度地减小vacuum对数据库的影响,但对PG的未来来说,更好地解决这个问题的方式,当然是新的存储引擎。
就实际来说,MySQL早些年的MyISAM,实现质量并不好,不支持事务,表级别的读写锁。但因为存储引擎独立接口,MySQL等到了InnoDB,InnoDB实现了全套事务存储引擎,且现在已完全取代了MyISAM的地位。
而PG本身就实现了事务存储引擎,这个独立存储引擎的需求虽然很多年前早已规划,但实际上拆分出来正经去做,才是这个迭代的事情。
目前,PG单独处理了数据存储,索引存储的接口,第三方可以直接实现对应的接口和数据结构,就可以让PG利用到新增的存储引擎。
在社区里,已经有两个非常重要的存储引擎产生--虽然距离生成环境尚且还有一段距离,但这两个存储引擎都解决了PG本身存在多年的痼疾,未来可期。
两个非常重要的存储引擎,就是EDB的zheap(开发中),以及Greenplum团队共享的zedstore(开发中)存储引擎。
PostgreSQL的存储实现中,其中dirty的一部分,vacuum,在实际生产环境中,成了一个每个运维都必须面对的问题。在zheap中,通过引入undo日志,zheap试图同时解决vacuum问题,以及32位事务id导致的vacuum freeze(事务ID回卷)问题。
在zheap中,并没有对heap(后文以此代称“pg”原生存储引擎)的索引,执行计划等进行处理,而只是单纯处理了其数据存储部分,也就是把undo从数据文件剥离出来成为undo日志。
目前其实现是:undo日志一直向前写(类似WAL日志),单独的purge进程从undo日志最老的日志开始回收,数据变更会保留在undo日志的数据指针,方便需要查询“老”数据的情况。这么一来,就可以避免数据文件的膨胀,以及vacuum的全表扫描的代价了。
而zedstore则代表了不同的方向:
OLAP。
greenplum所处理的,就是MPP数据仓库,而在数据仓库来说,通常扫描一个表特定几列的情况,会远多于需要同时扫所有列的情况,因此zedstore设计目的,就是一个列存数据库。
zedstore的实现中,每个条目,都有一个名为tid的虚拟主键,表的某一列或者某几列,就保存在使用tid作为主键的B树索引中。通过支持tid到多列的索引,也相当于实现了“行列混合存储”。
zedstore另外一个重要的实现,就是压缩。zedstore数据存储的时候,是只压缩数据,不压缩数据块元数据的,这么搞虽然牺牲了一定比例的压缩比(考虑到数据块头的大小,未必有多大代价)。但得到的好处就是显而易见了:数据块以压缩的形态存储在共享池中,由用户会话解压缩各自所需的数据--作为对比的MySQL InnoDB压缩,就是整个数据块级别的压缩,于是共享池里面,就得同时保存数据块的压缩与未压缩版本,平白消耗了宝贵的内存。
注:本文PPT可直接点击文章底部左下角“阅读原文”下载哦~
PPT下载链接:https://www.modb.pro/doc/1314
小编提醒:关于《2019数据技术嘉年华PPT》共有两个获取途径:
1. 在“数据和云”公众号后台回复:2019dtc,即可下载!
2. 在“墨天轮”上,已按13个会场整理了目前所有已经开放的PPT,大家可以选择感兴趣的主题下载,详情:
https://www.modb.pro/db/11553,复制到网页中打开。
扩展阅读
![不用找了,PostgreSQL 12 GA的新特性都在这里!]() DBASK 掌上知识库,及时资讯,随问随答!
DBASK 掌上知识库,及时资讯,随问随答! ![不用找了,PostgreSQL 12 GA的新特性都在这里!]() Mini Program
Mini Program
数据和云
ID:OraNews
如有收获,请划至底部,点击“在看”,谢谢!
help,30万+下载的完整菜单栏
2019DTCC,数据库大会PPT
2018DTCC , 数据库大会PPT
2018DTC,2018 DTC 大会 PPT
ENMOBK,《Oracle性能优化与诊断案例》
DBALIFE,“DBA 的一天”海报
DBA04,DBA 手记4 电子书
122ARCH,Oracle 12.2体系结构图
2018OOW,Oracle OpenWorld 资料
云和恩墨BethuneX 企业版,集监控、巡检、安全于一身,你的专属数据库实时监控和智能巡检平台,漂亮的不像实力派,你值得拥有!
云和恩墨zData一体机现已发布超融合版本和精简版,支持各种简化场景部署,零数据丢失备份一体机ZDBM也已发布,欢迎关注。
以上是关于不用找了,PostgreSQL 12 GA的新特性都在这里!的主要内容,如果未能解决你的问题,请参考以下文章
PostgreSQL 14 Beta1 版本的新特性PDF
PostgreSQL 14 Beta1 版本的新特性PDF
Hadoop3.0的新特性
最稳定可靠,PostgreSQL 12.1版本正式发布!
ES2021(ES12)新特性解读
MySQL 5.7.9 GA稳定版新特性解读