分布式锁原理初探
Posted 58无线技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式锁原理初探相关的知识,希望对你有一定的参考价值。
另外还有Lock,需要显式的调用锁定和解锁。这两种锁的作用范围是一个jvm进程,也就是我们的一个系统中;
在分布式系统中,一个集群内的不同主机或者不同集群同时访问共享的资源,会出现竞态条件(两个或多个线程竞争同一资源时,如果对资源的访问顺序敏感就称为竞态条件),使用传统的锁就没有办法处理,此时就需要使用分布式锁来解决。
分布式锁主要就是解决分布式系统中共享资源的竞态条件问题。
1.作为锁所要具备的最基本的功能其一是获取锁,其二是释放锁;
synchronized关键字在jvm中使用了字节码指令monitorenter和monitorexitlock来获取和释放对象锁,这两个字节码指令隐式的调用了lock和unlock操作。锁的获取和释放无需我们关心,jvm进程挂掉资源回收;
java提供的Lock需要我们显示的调用锁定和解锁。底层使用cas算法,控制原子变量的状态,来标记锁的获取与释放,
同样jvm进程挂掉资源进行回收;
分布式锁同样也需要提供获取和释放锁的功能。
2.处理死锁
3.重入性
4.锁的性能等
加锁:在需要使用的地方执行该key的incr操作,如果返回值是1,则获取锁
解锁:在finally块中将key做decr操作
设置过期时间:如果进程挂掉,导致锁没有释放,自动过期删除
优点:操作简单易行
缺点:
1.设置过期时间正确
获取锁的客户端进程在执行过程中挂掉,没有走finally块减一,那其他进程只能等redis的ttl自动删除;
该过期时间设置的长短难以把控,如果我们的请求因为其他原因阻塞了没有处理完,但已经到了redis的过期时间,其他进程可以获得锁进行处理,结果。。。
2.设置过期时间不正确
设置key的自增和设置过期时间不是原子操作,假如前者设置成功了,而过期时间因为各种原因没有设置成功,一旦该锁的计数出现错误,那么所有进程都无法获取到锁,结果。
总结上面方式所存在的问题:
1.操作非原子性
2.网络中断、命令发送失败
3.死锁
4.互斥
拿最简单的互斥锁来说
synchronized内置锁是作用于对象,java中每个对象是唯一存在的,
每个对象的对象头中包含获取该对象锁的线程ID,那就保证了线程对该对象锁的唯一性。
ReentrantLock内含Sync对象,其继承自同步器对象,同步器对象继承自 AbstractOwnableSynchronizer,该对象可以设置获取该锁的独占线程。
从上面两种锁可以看出,锁的标识要与线程保持唯一性的关系
不例外的分布式锁也该如此,需要明确当前锁被哪个线程占有,也就是要维护锁与线程的关系。
2.如何防止死锁的产生
对于synchronized产生的死锁,似乎我们无能为力,即死锁状态无法解除;
一个线程已经获得了对象锁,其他线程访问共享对象的时就必须无限期等待,不能中断那些获取锁的线程。
因此我们编码时让线程按照相同的顺序获得一组锁进行预防。
而Lock提供了更加灵活的方法,如果当前锁可用则返回true,否则返回false,并且可以设置获取锁的超时 时间,超时退出,防止死锁。
对于分布式的锁第一要设置锁的超时时间,让锁能及时释放掉。
其次还要设置客户端请求锁的超时时间,以防止通信过程出现问题,客户端线程一直等待锁响应。
3.保证互斥性和重入性
哪一个线程可以获得锁(独占锁)?哪些线程可以获取锁(共享锁)?线程之间互斥锁与共享锁是如何保证的?
我们先来看下传统锁是如何来处理的
synchronized是互斥锁,只需维护互斥关系,对象唯一,锁唯一;
重入性也是维护计数器,累加;
Lock既有互斥锁也有共享锁
其互斥特性是利用int变量state来判断,当然state是用volatile修饰。
判断state是否为0,如果为0,设置当前线程为独占锁拥有者,并将state加1;
重入特性实现也比较简单,state一直累加即可。
redis如何保证互斥性
使用过期时间,如果当前应用的线程获取锁的过期时间是null,设置锁的过期时间,并返回null,当然该操作是原子操作(如何保证原子性,请看下文);
如果在该锁过期时间内,其他线程获取的过期时间不为空,也就没有获得锁。
重入性:使用hset,设定当前锁的value值,如果重复获取锁,则累加;释放锁递减。
4.如何保证原子性
上面的实现方式中,存在的原子性的问题。那如何来保证操作的原子性?
貌似通过我们的java程序保证是无济于事的;
redis在2.6版本以后,可以使用lua语言编写脚本传到redis服务端执行,
将我们之前多次与服务端交互才能完成的功能放到一次脚本中处理,那我们所担心的原子性问题迎刃而解,还可以减少网络传输。
5.未获取锁的线程如何处理
得到锁的线程如愿以偿的去执行临界区内代码了,那未得到锁的线程去哪里了?
有两种方式:
非阻塞:未获取到锁的线程一直循环看锁的持有者是否释放锁。
优点:处理相对简单 缺点:占用cpu资源,容易产生死锁
阻塞:未获得锁,将线程本身进行阻塞。
优点:对线程统一管理调度 缺点:逻辑相对复杂
Lock把未得到锁的线程封装成Node节点,放入其构造的虚拟双向队列中,该队列是FIFO队列,
并进行阻塞操作,等待东山再起,将队列符合条件的线程调用park()方法挂起阻塞。
当获取锁的线程释放锁时,会调用unpark()唤醒队列中第一个阻塞节点,使程序在阻塞处继续执行,
让队列head节点的下一个节点持有的线程获得锁,并且将该节点设为head节点。过程见下图:
也是采用阻塞的方式处理线程。
那分布式redis锁该如何处理未获得到锁的线程呢?
采用非阻塞方式,没得到锁的线程,不断的轮询来获取锁,很明显这样的方式会增加额外的无用功,
会增加redis服务端节点的压力。
如何进行优化?
一个应用里面可能会有多个线程竞争该锁,可以控制应用里线程对锁的申请频率
1.让线程sleep一段时间再请求锁,那sleep多长时间呢,时间不好把控。
2.单个应用进程里可以使用信号量来限制,那就需要对信号量进行增减操作,来控制一定数量的线程。没有信号量的线程阻塞,直到某个线程释放锁后信号量加1,线程获得信号量后来竞争锁。那就需要监听线程释放锁的操作,如何监听呢?可以使用redis的pub/sub方式,异步处理,增加吞吐量;
首先线程订阅某个锁的topic,如果获取不到锁,就发起sub操作,并阻塞当前线程,一旦有线程释放锁,pub消息给订阅的客户端,客户端进行信号量的处理,使阻塞的线程获取许可来竞争锁。对于某个锁有哪些线程需要,也就转移到redis服务端记录。
具体过程如下图:
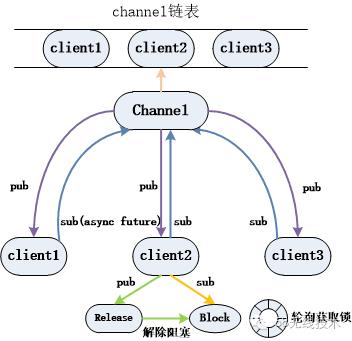
redis分布式锁处理过程
以上是关于分布式锁原理初探的主要内容,如果未能解决你的问题,请参考以下文章