详解锁,分布式锁的几种实现方式
Posted 繁荣Aaron
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解锁,分布式锁的几种实现方式相关的知识,希望对你有一定的参考价值。
1.什么是锁?
多线程的锁、数据库的锁、分布式的锁,三种锁机制。
在单进程的系统中,当存在多个线程可以同时改变某个变量(可变共享变量)时,就需要对变量或代码块做同步,使其在修改这种变量时能够线性执行消除并发修改变量。
而同步的本质是通过锁来实现的。为了实现多个线程在一个时刻同一个代码块只能有一个线程可执行,那么需要在某个地方做个标记,这个标记必须每个线程都能看到,当标记不存在时可以设置该标记,其余后续线程发现已经有标记了则等待拥有标记的线程结束同步代码块取消标记后再去尝试设置标记。这个标记可以理解为锁。
除了利用内存数据做锁其实任何互斥的都能做锁(只考虑互斥情况),如流水表中流水号与时间结合做幂等校验可以看作是一个不会释放的锁,或者使用某个文件是否存在作为锁等。只需要满足在对标记进行修改能保证原子性和内存可见性即可。
总结:一是在多线程中,维护线程的安全和维护线程的可见性;二是在在数据库中,保存数据的一致性。
2.什么是分布式锁?
当在分布式模型下,数据只有一份(或有限制),此时需要利用锁的技术控制某一时刻修改数据的进程数。
——概念
多线程锁
在单机环境中,为了保持在使用多线程的时候,确保线程的安全性,我们一般会使用Java API 中java.util.concurrent.* 包下面的API进行代码的编写。
如果在不同的场景使用不同的API呢?对于Java来说,是面向对象的,无非就是在class(类),变量,method(方法)三个地方(一是类上(class);二是方法上;三是全局变量。)
对于Class来说,最著名的是Spring依赖注入Bean实例,使用的是单例设计模式,确保了在多线程创建class的时候,线程是安全的。
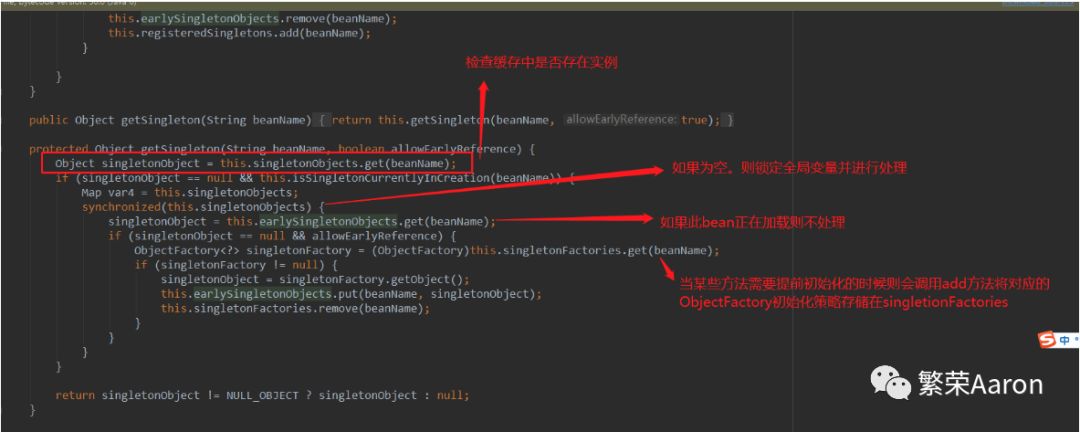
而对于method来说,有两个关键字,一是synchronized,另一个是lock。对于synchronized来说,一般是加在函数名称之前加上synchronized,或者在方法体上加上。
synchronized(Object o){//do something}
而对于lock来说,lock是重入锁,只能在方法体内部加上,格式如下:
Lock reentrantLock = new ReentrantLock();reentrantLock.lock();//处理事务reentrantLock.unlock();
其实对于上面的三条语句(代码)来说,并不是最好的。我们还可以设置锁(是否公平,锁的时间)相关属性,同时把reentrantLock.unlock();在finally里面,也就是说,在捕获异常的时候,不管执行如何,最终都会释放这个锁的,代码如下:
Lock reentrantLock = new ReentrantLock();try {//设置时间reentrantLock.tryLock(2, TimeUnit.SECONDS);//do something}catch (Exception e){e.printStackTrace();}finally {reentrantLock.unlock();}
补充知识点:
什么是重入锁?
重入锁
(1)重进入:
1.定义:重进入是指任意线程在获取到锁之后,再次获取该锁而不会被该锁所阻塞。关联一个线程持有者+计数器,重入意味着锁操作的颗粒度为“线程”。
2.需要解决两个问题:
线程再次获取锁:锁需要识别获取锁的现场是否为当前占据锁的线程,如果是,则再次成功获取;
锁的最终释放:线程重复n次获取锁,随后在第n次释放该锁后,其他线程能够获取该锁。要求对锁对于获取进行次数的自增,计数器对当前锁被重复获取的次数进行统计,当锁被释放的时候,计数器自减,当计数器值为0时,表示锁成功释放。
3.重入锁实现重入性:每个锁关联一个线程持有者和计数器,当计数器为0时表示该锁没有被任何线程持有,那么任何线程都可能获得该锁而调用相应的方法;当某一线程请求成功后,JVM会记下锁的持有线程,并且将计数器置为1;此时其它线程请求该锁,则必须等待;而该持有锁的线程如果再次请求这个锁,就可以再次拿到这个锁,同时计数器会递增;当线程退出同步代码块时,计数器会递减,如果计数器为0,则释放该锁
最后对于全局变量来说,需要使用关键字volatile。相信看过spring源码的都知道,缓存。不知道有没有发现,使用了volatile关键字进行修饰。
总结:
主要是synchronized和lock的区别,两个都可以用在方法体上。两个都是重入锁,synchronized可重入性,指的是同一线程在调用自己类中其他synchronized方法/块或调用父类的synchronized方法/块都不会阻碍该线程的执行,就是说同一线程对同一个对象锁是可重入的,而且同一个线程可以获取同一把锁多次,也就是可以多次重入。而lock最大的区别是:可中断响应、锁申请等待限时、公平锁等功能。另外可以结合Condition来使用。也就是说lock功能更强大。从Jdk 1.5 开始之后,由于对synchronized进行了优化,synchronized和lock的效率是差不多的。
注意:上面的锁,在单机服务器是很好使用的,假如获取订单号(唯一),是可以确保的。但是如果把该项目部署到多台服务器上去,该锁只能在该服务器上锁住,也就是对于分布式是没有的,获取订单号是确保不了唯一的。

数据库中的锁
我们能使用数据库中的锁?主要原因我认为是利用到了数据库中的事务,数据库中的事务具有以下特性:原子性/一致性/隔离性/持久性。一个事务只会有一个结果:要么成功,要么失败。所以我们可以利用其特点,在某一个时间点进行更新等等操作。当发起一个请求,相当于创建了一个连接,同时也创建了一个会话或多个会话。同一个连接上的不同会话之间不会相互影响,两个会话之间影响,体现在锁和锁存,即对相同的资源操作或请求,它们的处理一般是按队列来处理的,前面的没有处理好,后面的就要等待。接下来使用数据库的锁,就很容易理解了。
1.基于乐观锁
乐观锁只是在更新数据那一刻锁表,其他时间不锁表,所以相对于悲观锁,效率更高。我所理解的乐观锁其实有两种实现的方式。
第一种通过版本号实现:
update table_xxx set name=#name#,version=version+1 where version=#version# 第二种通过条件限制实现:
这个方式使用的最多,我所在的项目对于减轻库存等金额字段是使用这个方式进行乐观锁的控制,update tablexxx set avaiamount=avaiamount-#subAmount# where avaiamount >= #subAmount#
注意where条件,不要用表达式进行,要求:quality-#subQuality# >= ,这个情景适合不用版本号,只更新是做数据安全校验,适合库存模型,扣份额和回滚份额,性能更高 。
注意:乐观锁的更新操作,最好用主键或者唯一索引来更新,这样是行锁,否则更新时会锁表,上面两个sql改成下面的两个更好(后面会更新mysql相关系列文章):
update tablexxx set name=#name#,version=version+1 where id=#id# and version=#version#update tablexxx set avaiamount=avaiamount-#subAmount# where id=#id# and avai_amount- >= #subAmount#
2.基于悲观锁
悲观锁使用也是非常简单,只需要在select 语句最后面加上关键字for update,例如:
获取数据的时候加锁获取 :
select * from table_xxx where id='xxx' for update; 注意:id字段一定是主键或者唯一索引,不然是锁表,会死人的。 悲观锁使用时一般伴随事务一起使用,数据锁定时间可能会很长,根据实际情况选用。
3.基于数据库表
这种方案在实际的项目中,我没有使用过,但是目前对于生成唯一ID,我们使用数据表这种方案。先说说,利用数据库做分布式锁,然后在分析一下其利害关系。
思路是:
要实现分布式锁,最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。当我们要锁住某个方法或资源时,我们就在该表中增加一条记录,想要释放锁的时候就删除这条记录;如果不删除,可以增加一个状态的字段,不同的操作,由不同的状态决定,这个方式相当于版本号(乐观锁)。
a.建立一个lockTable表,然后添加表字段(id,method_name,desc,create_time,update_time),特别主要的是需要对method_name字段做唯一性约束,这个很重要。
b.想要锁住某个方法时,执行以下sql:
insert into lockTable(method_name,desc,create_time,update_time) values ('xxx_method_name','XXXX_test','2019XX','2019XXX');影响的行数为1,如果有存在方法,则返回的不是1。因为我们对method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
当方法执行完毕之后,想要释放锁的话,需要执行以下Sql:
delete from lockTable where method_name ='xxx_method_name';返回影响的行数为1,如果已经删除了,返回影响的函数为0.
总结:
1.以上锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
2.以上锁都没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁,特别是第三个基于数据库表,如果失败,需要手动删除数据。同时基于数据库表的只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
3.以上锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
解决思路:
1.数据库是单点?搞两个数据库,数据之前双向同步。一旦挂掉快速切换到备库上。
2.没有失效时间?只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。或者在数据库中做个触发器。
3.对于基于数据库表来说,非阻塞的?搞一个while循环,直到insert成功再返回成功。
4.非重入的?在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。
分布式锁
在单机环境中,Java中其实提供了很多并发处理相关的API,但是这些API在分布式场景中就无能为力了。也就是说单纯的Java Api并不能提供分布式锁的能力。所以针对分布式锁的实现目前有多种方案,一是基于缓存,而缓存我们以Redis为例;第二个是基于ZK。相对于数据库来说,上面两个效率高,速度快一点。
1.基于Redis分布式锁
网上大部分资料,一般都是以setnx() 和 expire() 两个命令为基础的,进行分布式锁控制。其实这个方式是存在问题的,因为这两个命令不是原子操作,可能存在的情况如下:
setnx()命令设置key和value成功,但是执行到expire()命令的时候,发生了服务器进程之间突然挂掉了,可能是因为机器掉电或者是被人为杀掉的,就会导致 expire() 得不到执行,进而造成死锁。
正确的打开方式:
第一种命令的方式:
需要在Redis 2.6.12 版本之后,还是利用set()命令,该命令有设置时间的参数,也就是说该命令直接结合了expire()命令。
set aaron:test:lock true ex 10 nx参数解析:
EX second :设置键的过期时间为 second 秒。 SET key value EX second 效果等同于 SETEX key second value 。
PX millisecond :设置键的过期时间为 millisecond 毫秒。 SET key value PX millisecond 效果等同于 PSETEX key millisecond value 。
NX :只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key value 。
XX :只在键已经存在时,才对键进行设置操作。
释放锁很简单,直接删除 key:
del aaron:test:lock第二种Java代码方式:
获取锁:
调用:
Long time = System.currentTimeMillis() + RedisConstant.LOCK_TIME_OUT_TEN;if (!redisLockUtil.tryLock(key, time)) {throw new Exception(...);}
具体工具类:
public boolean tryLock(String key, long value) {while (value > System.currentTimeMillis()) {// 第一步:如果设置成功,代表加锁成功if (stringRedisTemplate.opsForValue().setIfAbsent(key, String.valueOf(value))) {return true;}// 第二步:获取上一个线程A的锁的值 BC的值为valueString currentValue = stringRedisTemplate.opsForValue().get(key);// 第三步:如果锁过期if (!StringUtils.isEmpty(currentValue) && Long.valueOf(currentValue) < System.currentTimeMillis()) {// 第四步:获取上一个锁的值并设置新的值, BC有先后关系。String oldValue = stringRedisTemplate.opsForValue().getAndSet(key, String.valueOf(value));// 第五步:判断if (!StringUtils.isEmpty(oldValue) && oldValue.equals(currentValue)) {return true;}}try {Thread.sleep(300);} catch (InterruptedException e) {e.printStackTrace();}}return false;}
释放锁:
public Boolean unlock(String key, long value) {// 执行lua脚本,确保原子性String script = "if redis.call('get', KEYS[1]) == ARGV[1] then redis.call('del',KEYS[1]) return true else return false end";DefaultRedisScript<Boolean> redisScript = new DefaultRedisScript<>(script, Boolean.class);return stringRedisTemplate.execute(redisScript, Collections.singletonList(key), String.valueOf(value));}
总结:
1.超时问题。Redis的分布式锁不能解决超时问题,如果在加锁和释放锁之间的逻辑执行的太长,以至于超出了锁的超时限制,就会出现问题。因为这时候第一个线程持有的锁过期了,临界区的逻辑还没有执行完,这个时候第二个线程就提前重新持有了这把锁,导致临界区代码不能得到严格的串行执行。为了避免这个问题,Redis 分布式锁不要用于较长时间的任务。如果真的偶尔出现了,数据出现的小波错乱可能需要人工介入解决。
我的建议最好是测试一下该需要执行的程序最大运行时间,然后把这个运行时间设置到超时时间里面去。
2.可重入性
上面的Java代码是不支持可重入性的,Redis 分布式锁如果要支持可重入,需要对客户端的 set 方法进行包装,使用线程的 Threadlocal 变量存储当前持有锁的计数。不过这个实现起来有点麻烦,不推荐使用。
2.基于ZK分布式锁
基于zookeeper临时有序节点可以实现的分布式锁,大致思想即为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
看下Zookeeper能不能解决前面提到的问题:
锁无法释放?
使用Zookeeper可以有效的解决锁无法释放的问题,因为在创建锁的时候,客户端会在ZK中创建一个临时节点,一旦客户端获取到锁之后突然挂掉(Session连接断开),那么这个临时节点就会自动删除掉。其他客户端就可以再次获得锁。
非阻塞锁?
使用Zookeeper可以实现阻塞的锁,客户端可以通过在ZK中创建顺序节点,并且在节点上绑定监听器,一旦节点有变化,Zookeeper会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是,那么自己就获取到锁,便可以执行业务逻辑了。
不可重入?
使用Zookeeper也可以有效的解决不可重入的问题,客户端在创建节点的时候,把当前客户端的主机信息和线程信息直接写入到节点中,下次想要获取锁的时候和当前最小的节点中的数据比对一下就可以了。如果和自己的信息一样,那么自己直接获取到锁,如果不一样就再创建一个临时的顺序节点,参与排队。
单点问题?
使用Zookeeper可以有效的解决单点问题,ZK是集群部署的,只要集群中有半数以上的机器存活,就可以对外提供服务。
具体实现,参看之前zk相关的文章:
( https://mp.weixin.qq.com/s/W1wM5UNUFRAJZA02RLvIvw )。
参考资料:
MySQL中的连接、实例、会话、数据库、线程之间的关系,雅思敏.
2.Redis 命令参考(http://doc.redisfans.com/index.html).
3.zookeeper知识点讲解(三)--API使用、分布式锁和简单的服务注册与发现.
秀米XIUMI
以上是关于详解锁,分布式锁的几种实现方式的主要内容,如果未能解决你的问题,请参考以下文章