三种使用分布式锁方案
Posted 猿人课堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三种使用分布式锁方案相关的知识,希望对你有一定的参考价值。
一、背景:单体架构中使用同步访问解决多线程并发问题,分布式中需要有其他方案。
二、分布式锁的考量:
1.可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器-上的一个线程执行。
2.这把锁要是一把可重入锁(避免死锁)
3.这把锁最好是一把阻塞锁(根据业务需求考虑要不要这条)
4.这把锁最好是一把公平锁(根据业务需求考虑要不要这条)
5.有高可用的获取锁和释放锁功能
保证了只有锁的持有者才能来解锁,否则任何竞争者都能解锁
6.获取锁和释放锁的性能要好
7.如果做的好一点,需要有监控的平台。
三、分布式锁的三种实现方式
1.基于数据库实现排他锁:利用version字段和for update操作获取锁。
优点:易于理解
问题:
(1)锁没有失效时间,解锁失败时(宕机等原因),其他线程获取不到锁。
解决:做一个定时任务实现自动释放锁。
(2)锁属于非阻塞,因为获取锁的是insert操作,一旦获取失败就报错,没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
解决:搞一个while循环,直到insert成功再返回成功。
(3)不是可重入锁。
解决:加入锁的机器字段,实现同一机器可重复加锁。
另外在解锁时,必须是锁的持有者来解锁,其他竞争者无法解锁
(4)由于是数据库,对性能要求高的应用不合适用此实现。
解决:数据库本身特性决定。
(5)在 mysql 数据库中采用主键冲突防重,在大并发情况下有可能会造成锁表现象。
解决:比较好的办法是在程序中生产主键进行防重
(6)这把锁是非公平锁,所有等待锁的线程凭运气去争夺锁
解决:再建一张中间表,将等待锁的线程全记录下来,并根据创建时间排序,只有最先创建的允许获取锁。
(7)考虑到数据库单点故障,需要实现数据库的高可用。
注意:InnoDB 引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁
另外存在问题:
(1)行级锁并不一定靠谱:虽然我们对方法字段名使用了唯一索引,并且显示使用 for update 来使用行级锁。
但是,MySQL 会对查询进行优化,即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的,
如果MySQL 认为全表扫效率更高,比如对一些很小的表,它就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。这种情况是致命的。
(2)我们要使用排他锁来进行分布式锁的 lock,那么一个排他锁长时间不提交,就会占用数据库连接。
一旦类似的连接变得多了,就可能把数据库连接池撑爆
2.基于redis实现(单机版):需要自己实现 一定要用 SET key value NX PX milliseconds 命令,而不要使用setnx 加expire
优点:性能高、超时失效比数据库简单。
开源实现:Redis官方提出一种算法,叫Redlock,认为这种实现比普通的单实例实现更安全。
RedLock有多种语言的实现包,其中Java版本:Redisson。
缺点:
(1)失效时间无法把控。可能设置过短或者过长的情况.如果设置过短,其他线程可能会获取到锁,无法保证情况。过长时其他线程获取不到锁。
解决:Redisson的思路:客户端起一个后台线程,快到期时自动续期,如果宕机了,后台线程也没有了。
(2)如果采用 Master-Slave 模式,如果 Master 节点故障了,发生主从切换,主从切换的一瞬间,可能出现锁丢失的问题。
解决:Redisson ,但存在争议的,不过应该问题不大。
3.基于zookeeper实现(推荐):可靠性好,使用最广泛。实现:Curator
4.基于etcd的实现:优于zookeeper实现,如果项目中应用了etcd,那么使用etcd。
5.Spring Integration 实现了分布式锁:
Gemfire
JDBC
Redis
Zookeeper
基于数据库实现排他锁
方案1
获取锁
INSERT INTO method_lock (method_name, desc) VALUES ('methodName', 'desc');
对method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功。
方案2
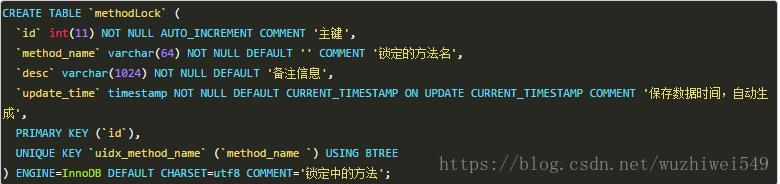
CREATE TABLE `method_lock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`method_name` varchar(64) NOT NULL COMMENT '锁定的方法名',
`state` tinyint NOT NULL COMMENT '1:未分配;2:已分配',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON
UPDATE CURRENT_TIMESTAMP,
`version` int NOT NULL COMMENT '版本号',
`PRIMARY KEY (`id`),
UNIQUE KEY `uidx_method_name` (`method_name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='锁定中的方法';
先获取锁的信息
select id, method_name, state,version from method_lock
where state=1 and method_name='methodName';
占有锁
update t_resoure set state=2, version=2, update_time=now() where
method_name='methodName' and state=1 and version=2;
如果没有更新影响到一行数据,则说明这个资源已经被别人占位了。
缺点:
1、这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
2、这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
3、这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
4、这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
解决方案:
1、数据库是单点?搞两个数据库,数据之前双向同步。一旦挂掉快速切换到备库上。
2、没有失效时间?只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。
3、非阻塞的?搞一个while循环,直到insert成功再返回成功。
4、非重入的?在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。
基于redis实现
获取锁:
SET resource_name my_random_value NX PX 30000
解锁方式一:不可用。
if( (GET user_id) == "XXX" ){ //获取到自己锁后,进行取值判断且判断为真。此时,这把锁恰好失效。
DEL user_id
}
由于GET取值判断和DEL删除并非原子操作,当程序判通过该锁的值判断发现这把锁是自己加上的,准备DEL。
此时该锁恰好失效,而另外一个请求恰好获得key值为user_id的锁。
此时程序执行了了DEL user_id,删除了别人加的锁,尴尬!
解锁方式二(推荐):为了保证查询和删除的原子性操作,需要引入lua脚本支持。
if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else
return 0
end
使用zookeeper实现分布式锁
zookeeper分布式锁应用了临时顺序节点
获取锁
首先,在Zookeeper当中创建一个持久节点ParentLock。当第一个客户端想要获得锁时,需要在ParentLock这个节点下面创建一个临时顺序节点 Lock1。
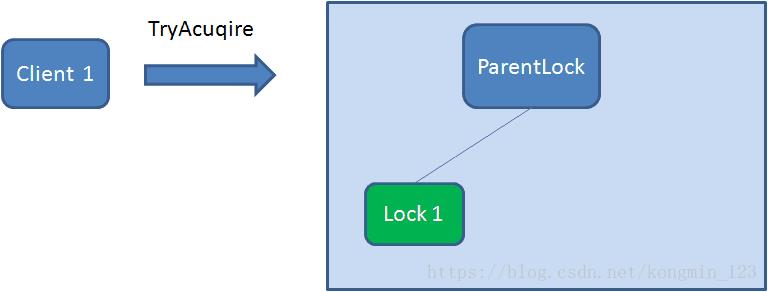
之后,Client1查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock1是不是顺序最靠前的一个。如果是第一个节点,则成功获得锁。
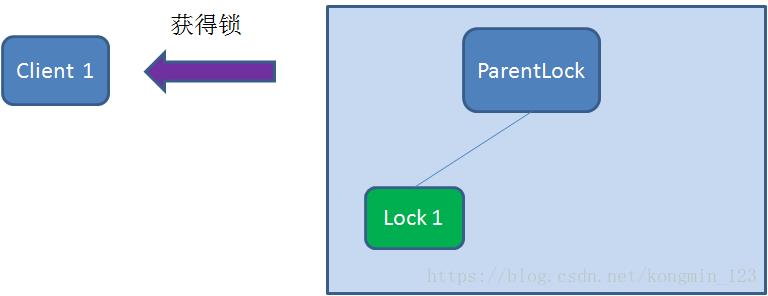
这时候,如果再有一个客户端 Client2 前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock2。
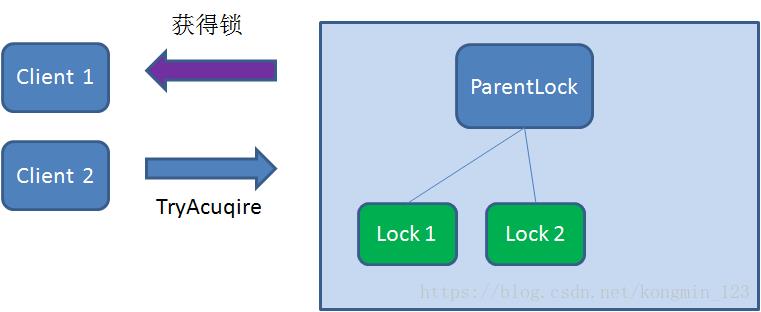
Client2查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock2是不是顺序最靠前的一个,结果发现节点Lock2并不是最小的。
于是,Client2向排序仅比它靠前的节点Lock1注册Watcher,用于监听Lock1节点是否存在。这意味着Client2抢锁失败,进入了等待状态。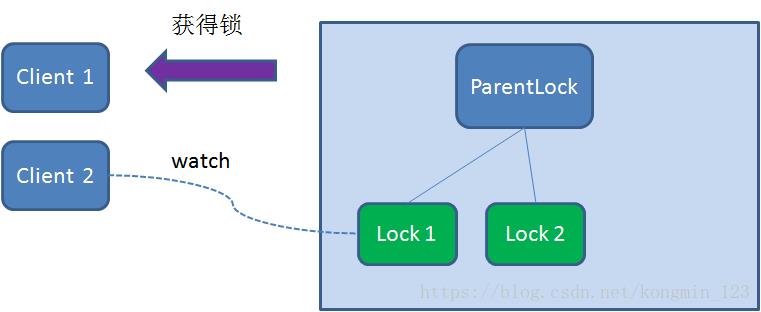
这时候,如果又有一个客户端Client3前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock3。
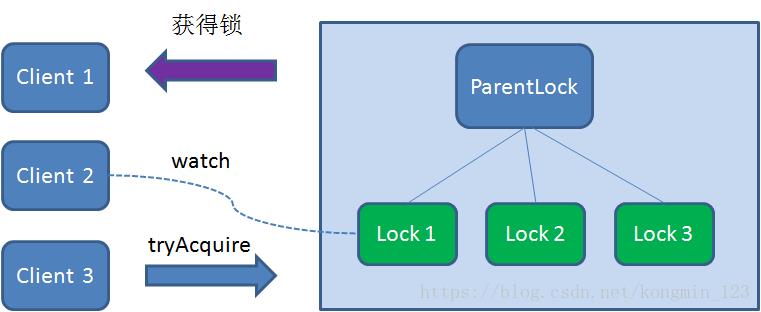
Client3查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock3是不是顺序最靠前的一个,结果同样发现节点Lock3并不是最小的。
于是,Client3向排序仅比它靠前的节点Lock2注册Watcher,用于监听Lock2节点是否存在。这意味着Client3同样抢锁失败,进入了等待状态。
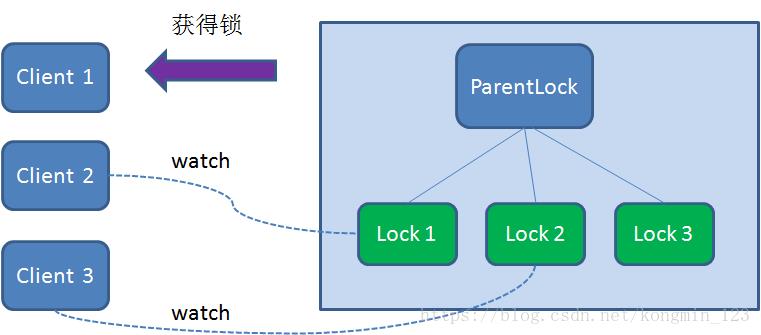
这样一来,Client1得到了锁,Client2监听了Lock1,Client3监听了Lock2。这恰恰形成了一个等待队列,很像是Java当中ReentrantLock所依赖的AQS(AbstractQueuedSynchronizer)。
获得锁的过程大致就是这样,那么Zookeeper如何释放锁呢?
释放锁的过程很简单,只需要释放对应的子节点就好。
释放锁
释放锁分为两种情况:
1.任务完成,客户端显示释放
当任务完成时,Client1会显示调用删除节点Lock1的指令。
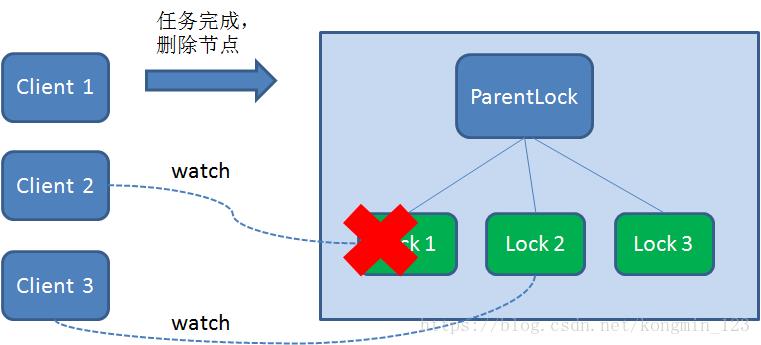
2.任务执行过程中,客户端崩溃
获得锁的Client1在任务执行过程中,如果Duang的一声崩溃,则会断开与Zookeeper服务端的链接。根据临时节点的特性,相关联的节点Lock1会随之自动删除。
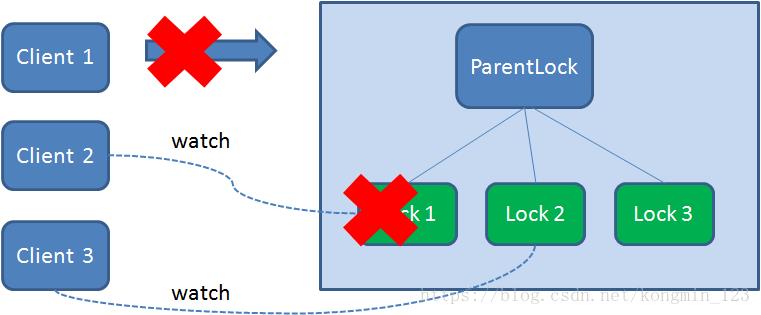
由于Client2一直监听着Lock1的存在状态,当Lock1节点被删除,Client2会立刻收到通知。这时候Client2会再次查询ParentLock下面的所有节点,确认自己创建的节点Lock2是不是目前最小的节点。如果是最小,则Client2顺理成章获得了锁。
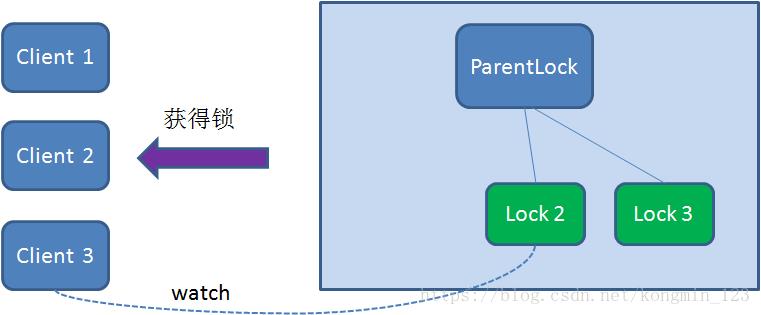
同理,如果Client2也因为任务完成或者节点崩溃而删除了节点Lock2,那么Client3就会接到通知。
最终,Client3成功得到了锁。
以上是关于三种使用分布式锁方案的主要内容,如果未能解决你的问题,请参考以下文章
Java分布式锁三种实现方案——方案三:基于Zookeeper的分布式锁,利用节点名称的唯一性来实现独占锁
分布式——补充的一些东西(就业相关的)秒杀的设计方案分布式id生成方案分布式锁分布式锁的三种实现方式(基于数据库RedisZookeeper)