分布式锁的实现与探索
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式锁的实现与探索相关的知识,希望对你有一定的参考价值。

源宝导读:大型的信息化系统对数据准确性的要求很高,所以经常会使用事务、锁、队列等技术,保障高并发下的数据一致性问题。本文将讨论在分布式部署模式下,如何利用锁机制保证业务数据准确的技术探索与实践。
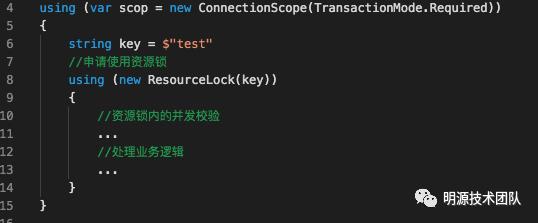
分布式场景下的数据一致性问一直是一个非常重要的话题,在很多场景中,我们需要使用各种技术方案来保证数据的一致性,比如分布式事务、分布式存储、分布式锁等。有些业务场景中,我们需要保证一个方法在同一时间内只能被一个线程执行,来解决一些譬如商品超卖,我们ERP中的一房多卖、财务票据号跳票重复等问题。在单机环境中,各种语言其实提供了较多并发处理相关的特性,比如.Net中的lock、Monitor、Mutex等,但是这些特性在分布式场景中就有问题了。针对分布式锁的实现,目前比较常用的有这样几种:数据库实现、缓存实现(redis,memcached)、Zookeeper实现、以及etcd等。
基于数据库唯一约束
应该是分布式锁最简单的方式之一,创建一张锁表,通过数据库的唯一约束,当我们需要锁住某个场景时,插入一条数据,插入成功则获锁成功可以执行后续操作,操作完成后删除记录来释放锁资源。我们老系统即提供了此种类型的锁来处理各类锁场景。
数据库约束实现的锁问题:
强依赖数据库,单点无高可用,数据库宕掉则业务不可用。
并发支撑不够,单点的数据库成为瓶颈。
非阻塞的,没有获得锁的无法排队直接失败。
非重入的,同一线程无法再次获取已经得到的锁。
没有失效时间,如果解锁失败则业务受阻。
利用数据库特性实现
利用SQL Server提供的应用锁来实现锁定,使用sp_getapplock加锁,sp_releaseappLock释放锁,随事务提交或回滚:
相对于数据库唯一约束实现来说,更加简便,好控制,不占用数据库空间,而且支持阻塞特性实现排队等待,且业务失败自动释放(回滚),目前ERP使用此方案来实现锁控制,开箱即用,不依赖其他服务。
相比于数据库实现,基于缓存的锁实现性能更好,可以支撑更高的并发,同时缓存的集群部署可以保证高可用。
MemCached
利用Memcached的原子命令add操作,只有add成功才表示获取到锁。由于MemCached采用LUR置换策略,可能导致并未过期的锁信息被删除,且无持久化。
Redis
同样利用其原子操作,来处理锁定场景,官方也提供了Relock的dotnet实现。

RedLock算法提出通过N/2 + 1(半数以上实例)获取到锁并且获取时间小于锁过期时间则认为获取到锁,来解决Master-Slave模式下主从同步失败导致的锁安全问题,但实际上还是可能由于某一节点未落盘宕机或则时钟不同步导致多客户端获锁成功的问题,本身AP,想完全CP就比较别扭了,这也是RedLock被质疑的地方。
同时通过retry机制实现阻塞(间隔一段时间,重试获锁过程),不过重试间隔不好把握,这一点java的实现Redisson提供了另外的方式,在申请锁失败后,阻塞线程,通过订阅解锁消息来释放阻塞并重试获锁过程,同时也可以利用watch dog来实现锁延时。
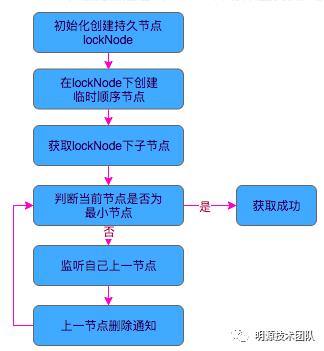
可以通过其有序临时节点+监听节点删除来实现分布式锁,通过仅监听上一个节点的删除事件避免羊群效应,具体流程如下图:
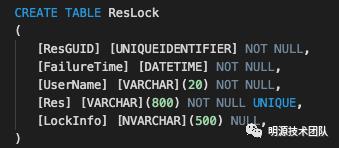
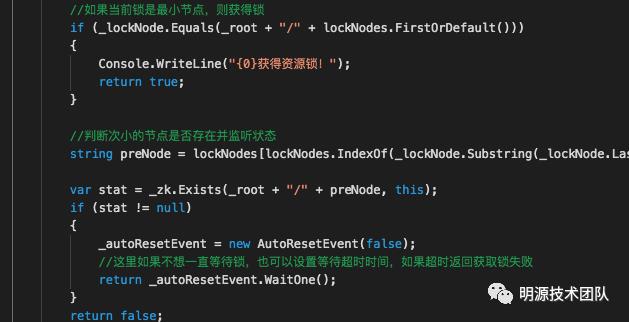
可基于Zookeeper的客户端,按照上述流程实现:
也可以使用ZookeeperNet.Recipes提供的锁:
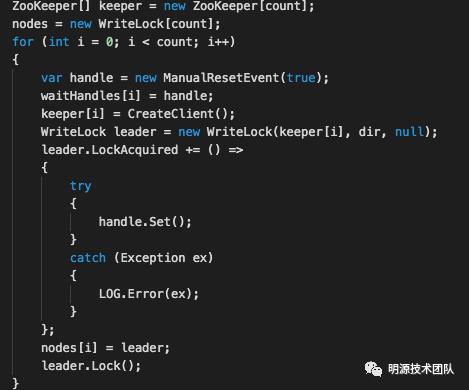
相比于redis,性能弱于redis,但健壮性更好(更能保障数据一致)。
五、利用etcd实现分布式锁
etcd可能没有ZK那么被大众熟知,但说它为K8s提供状态配置存储就明白了。

和ZK功能相似,使用Raft保证数据一致性,相较于zookeeper,ecd使用GO编写更加轻便,其效率也更高,在etcd v3版本中已提供了lock的封装。
官方推荐的dotnet的客户端如下:
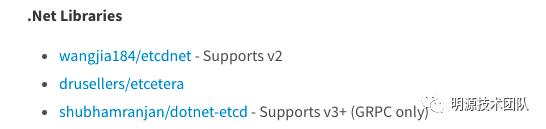
dotnet-etcd使用google的gRPC框架封装了客户端各操作,包括V3提供的锁:
六、总结
没有完美的技术,只有合适的选择,就如CAP原则最多只能同时满足两种特性一样,复杂性、高可用、高性能等方面很难同时满足,选择适合当前业务要求的即可。怕的是没有意识到并发情况会产生数据不一致的问题,导致的超卖现象以及跳号重复等问题的产生,之前处理过比较多的反馈,希望通过此篇文章让大家意识到分布式环境下可能出现的数据不一致的问题,并选择合适的方案来解决。
------ END ------
作者简介
王同学: 架构师,目前负责售楼产品的相关架构规划和设计工作。
也许您还想看
以上是关于分布式锁的实现与探索的主要内容,如果未能解决你的问题,请参考以下文章