InnoDB RR隔离级别下INSERT SELECT两种死锁案例剖析
Posted 老叶茶馆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了InnoDB RR隔离级别下INSERT SELECT两种死锁案例剖析相关的知识,希望对你有一定的参考价值。
校稿:叶师傅(部分内容有微调)
原文:http://blog.itpub.net/7728585/viewspace-2146183/
有网友遇到了在RR隔离级别下insert A select B where B.COL=** 发生死锁的问题。分析死锁日志后,笔者模拟重现了2种可能引发死锁的场景,本文中将进行详细的描述。
几个约定
本文使用版本Percona 5.7.14修改版,能够打印出事务所有的行锁信息结构链(不包含隐含锁);
本文中的测试均在RR隔离级别下完成的,RC不存在这样的问题;
笔者对源码的理解有限,如有错误请指正;
innblock,http://pan.baidu.com/s/1qYnyVWo
bcview,http://pan.baidu.com/s/1num76RJ
感谢叶金荣老师对本文的审核,笔者也曾是一名知数堂的学生
一、基本概念
在开始正文之前我打算介绍一下一些基本概念,特别是锁模型和兼容矩阵会对本文的阅读有相当大的帮助。
1、 innodb lock模型
[LOCK_ORDINARY[next_key_lock]:] 源码定义:
#define LOCK_ORDINARY 0 /*!< this flag denotes an ordinary next-key lock in contrast to LOCK_GAP or LOCK_REC_NOT_GAP */默认是LOCK_ORDINARY,即next-keylock,锁住行及其前面的间隙。
[LOCK_GAP:] 源码定义:
#define LOCK_GAP 512 /*!< when this bit is set, it means that the lock holds only on the gap before the record; for instance, an x-lock on the gap does not give permission to modify the record on which the bit is set; locks of this type are created when records are removed from the index chain间隙锁,锁住行以前的间隙,不锁住本行。
[LOCK_REC_NOT_GAP:] 源码定义:
#define LOCK_REC_NOT_GAP 1024 /*!< this bit means that the lock is only on the index record and does NOT block inserts to the gap before the index record; this is used in the case when we retrieve a record with a unique key, and is also used in locking plain SELECTs (not part of UPDATE or DELETE) when the user has set the READ COMMITTED isolation level */行锁,锁住行而不锁住任何间隙。
[LOCK_INSERT_INTENTION:] 源码定义:
#define LOCK_INSERT_INTENTION 2048 /*!< this bit is set when we place a waiting gap type record lock request in order to let an insert of an index record to wait until there are no conflicting locks by other transactions on the gap; note that this flag remains set when the waiting lock is granted, or if the lock is inherited record */插入意向锁,如果插入的记录在某个已经锁定的间隙内为这个锁。
2、 innodb lock兼容矩阵
/* LOCK COMPATIBILITY MATRIX * IS IX S X AI * IS + + + - + * IX + + - - + * S + - + - - * X - - - - - * AI + + - - -3、infimum和supremum
一个page中总是包含这两个伪记录。 页中所有未删除(或删除但还未purged)的行逻辑上都链接到这两个伪记录之间,表现为一个逻辑链表数据结构,其中supremum伪记录的锁始终为next-key lock。
4、heap no
heap no存储在fixed_extrasize 中。 heap no 为物理存储填充的序号,页的空闲空间挂载在page free链表中(头插法),空闲heap可以重用,但是重用时heap no不变。如果一直是insert 则heap no 不断增加。heap并不是按照ROWID(主键)排序的逻辑链表顺序,而是物理填充顺序。
5、n bits
和这个page相关的锁位图的大小,每一行记录都有1 bit的位图信息与其对应,用来表示是否加锁,并且始终预留64bit。 例如我的表有9条数据,外加infimum和supremum虚拟记录,即 64+9+2 bits = 75bits,但它还必须被8整除(为了向上取整为一个字节),最后结果也就是80 bits(8 bytes)。 注意:不管是否加锁,每行都会对应1 bit。
6、lock struct
这是LOCK的内存结构体。源码中用lock_t表示,有2种
lock_table_t tab_lock;/*!< table lock */ lock_rec_t rec_lock;/*!< record lock */一般来说,innodb表上锁时都会对表级加上IX,这占用一个结构体。然后分别对二级索引和主键进行加锁,每一个BLOCK会占用这样一个结构体。
7、row lock(s)
这个信息描述了当前事务加锁的行数,它是所有lock struct结构体中排除table lock以外所有加锁记录的总和,并且包含了infimum和supremum伪记录。
8、逐步加锁
细心的朋友应该会发现在show engine innodb status 输出中,在对大量行进行加锁时,事务信息中的row lock会不断的增加。这是因为加行锁最终会调用 lock_rec_lock 逐行加锁,这也会增加了大数据量加锁的触发死锁的可能性。
二、INSERT SELECT中对SELECT表的加锁模式
RR隔离级别下的 insert A select B where B.COL=**,会对B表中满足条件的数据加锁,但RC模式下B表记录不会加任何innodb层的锁。
具体表现如下:
如果B.COL是NON-UNIQUE SECONDARY KEY,并且是非覆盖索引(执行计划中没有 using index)
B表 二级索引 对选中记录加上 LOCK_S|LOCK_ORDINARY[next-key lock],并且对下一条记录加上 LOCK_S|LOCK_GAP
B表 PRIMARY KEY 加上 LOCK_S|LOCK_REC_NOT_GAP
2. 如果B.COL是UNIQUE SECONDARY KEY,并且是非覆盖索引
B表二级索引对选中记录加上 LOCK_S|LOCK_REC_NOT_GAP
B表PRIMARY加上 LOCK_S|LOCK_REC_NOT_GAP
3. 如果B.COL没有二级索引
对整个B表上的所有记录加上 LOCK_S|LOCK_ORDINARY[next_key_lock]
三、INSERT SELECT中SELECT表的加锁测试
我们分别对几种情况进行测试,观察锁信息:
3.1、B.COL是NON-UNIQUE SECONDARY KEY,并且是非覆盖索引
测试环境准备:
mysql> create table t1( id int primary key, n1 varchar(20), n2 varchar(20), key(n1)); mysql> create table t2 like t1; mysql> insert into t1 values(1,'gao1','gao'),(2,'gao1','gao'), (3,'gao1','gao'),(4,'gao2','gao'),(5,'gao2','gao'),(6,'gao2','gao'), (7,'gao3','gao'),(8,'gao4','gao');查看执行计划:
mysql> desc select * from t1 force index(n1) where n1='gao2’\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: ref possible_keys: n1 key: n1 key_len: 23 ref: const rows: 3 filtered: 100.00 Extra: NULL执行测试SQL:
mysql> begin;insert into t2 select * from t1 force index(n1) where n1='gao2';观察B表加锁结果
B.col 上加 LOCK_S|LOCK_ORDINARY[next_key_lock]
B.PRIMARY加上LOCK_S|LOCK_REC_NOT_GAP
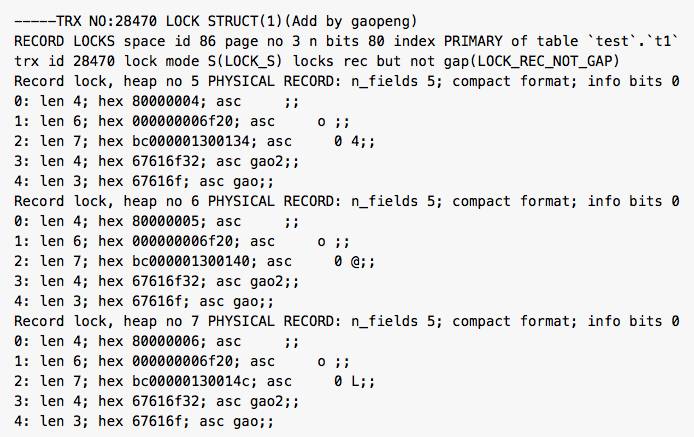
对B.二级索引下一条记录加上LOCK_S|LOCK_GAP

下图红色部分都是需要锁定的记录 
3.2、B.COL是UNIQUE SECONDARY KEY,并且是非覆盖索引
测试环境准备:
mysql> create table t1( id int primary key, n1 varchar(20), n2 varchar(20), unique key(n1)); mysql> create table t2 like t1; mysql> insert into t1 values(1,'gao1','gao'),(2,'gao2','gao'),(3,'gao3','gao'), (4,'gao4','gao'),(5,'gao5','gao'),(6,'gao6','gao'),(7,'gao7','gao'),(8,'gao8','gao');查看执行计划:
mysql> desc select * from t1 force index(n1) where n1 in ('gao2','gao3','gao4’)\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: range possible_keys: n1 key: n1 key_len: 23 ref: NULL rows: 3 filtered: 100.00 Extra: Using index condition执行测试SQL:
mysql> begin;insert into t2 select * from t1 force index(n1) where n1 in ('gao2','gao3','gao4');观察B表加锁结果
B.col 上加 LOCK_S|LOCK_REC_NOT_GAP
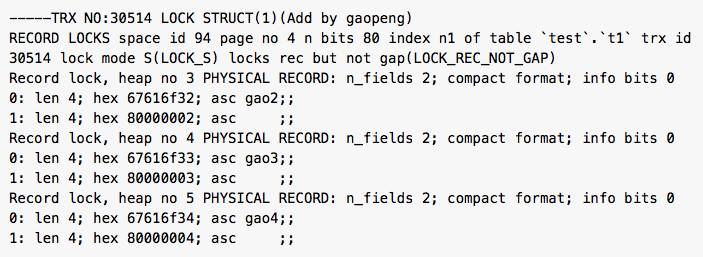
B.PRIMARY 上加 LOCK_S|LOCK_REC_NOT_GAP

下图红色部分都是需要锁定的记录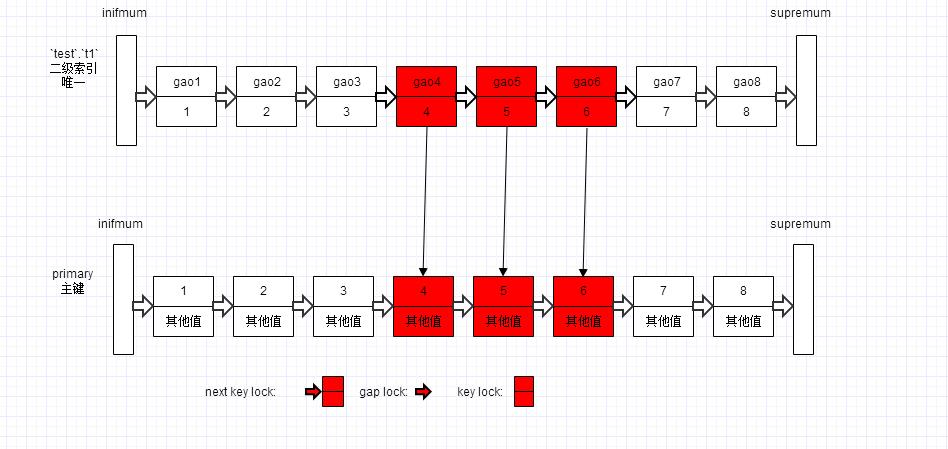
3.3、B.COL没有二级索引
测试环境准备:
mysql> create table t1( id int primary key, n1 varchar(20), n2 varchar(20)); mysql> create table t2 like t1; mysql> insert into t1 values(1,'gao1','gao'),(2,'gao2','gao'),(3,'gao3','gao'), (4,'gao4','gao'),(5,'gao5','gao'),(6,'gao6','gao'),(7,'gao7','gao'),(8,'gao8','gao');查看执行计划:
mysql> desc select * from t1 where n1 in ('gao2','gao3','gao4’)\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 partitions: NULL type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 8 filtered: 37.50 Extra: Using where执行测试SQL:
mysql> begin;insert into t2 select * from t1 where n1 in ('gao2','gao3','gao4');观察B表加锁结果
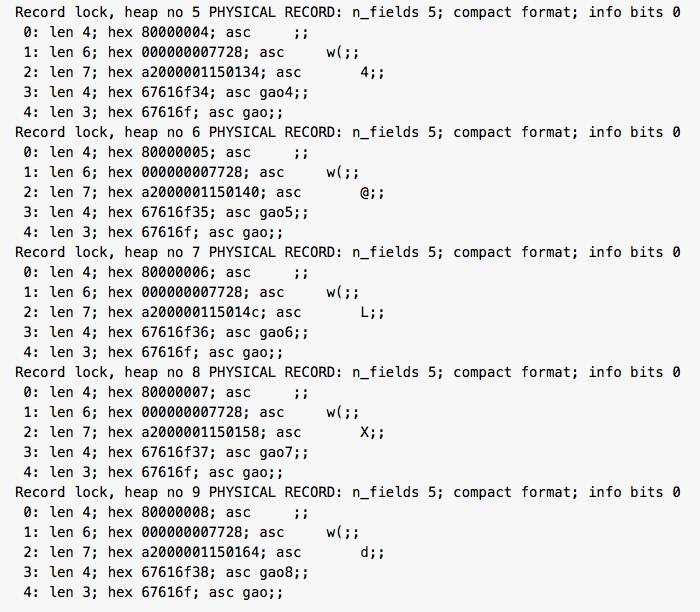
下图红色部分都是需要锁定的记录 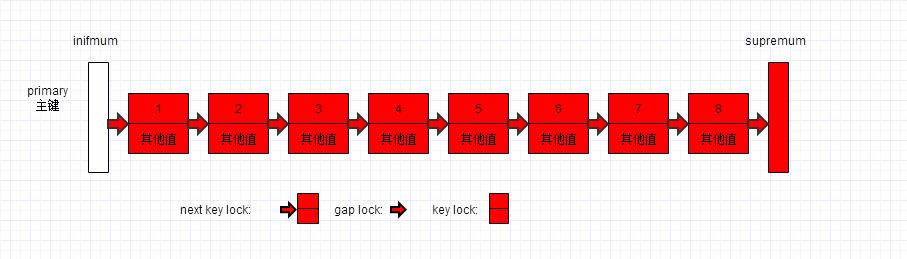
现在,我们确认在RR隔离级别下 INSERT SELECT 会对 SELECT 表中符合条件的数据加上 LOCK_S 锁。
四、INSERT SELECT由于SELECT表引起的死锁
我曾经总结过出现死锁的条件:
至少2个独立的线程(会话);
单位操作中包含多个相对独立的加锁步骤,有一定的时间差;
多个线程(会话)之间加锁对象必须有相互等待的情况发生,并且等待出现环状。
由于存在对 SELECT 符合条件的数据加上LOCK_S锁的情况,RR模式下 INSERT SELECT 出现死锁的概率无疑更高。我通过测试模拟出死锁结果,严格意义上说,这是相同的语句在高并发情况下表现为两种死锁结果。
测试环境准备:
mysql> create table b( id int primary key, name1 varchar(20), name2 varchar(20), key(name1)); mysql> DELIMITER // mysql> CREATE PROCEDURE test_i() begin declare num int; set num = 1; while num <= 3000 do insert into b values(num,concat('gao',num),'gaopeng'); set num=num+1; end while; end// mysql> call test_i()// create table a like b//模拟下面两个并发事务:
| TX1 | TX2 |
|---|---|
| begin; | - |
| update b set name2='test' where id=2999; | - |
| - | insert into a select * from b where id in (996,997,998,999,2995,2996,2997,2998,2999); |
| update b set name2='test' where id=999; | - |
但是在高并发下,相同的并发语句却表现出不同的死锁情况。
见下面详细过程分析。
4.1、场景一
TX1:执行update将表b主键id=2999的记录加上LOCK_X
TX2:执行insert...select语句b表上的记录(996,997,998,999,2995,2996,2997,2998,2999)会申请加上LOCK_S, 但是id=2999已经加上LOCK_X,显然不能获得只能等待.
TX1:执行update需要获得表b主键id=999的LOCK_X显然这个记录已经被TX2加锁LOCK_S,只能等待,触发死锁检测
如下图红色记录为不能获得锁的记录:
4.2、场景二
这种情况比较极端只能在高并发上出现
TX1:执行update将表b主键id=2999的记录加上LOCK_X
TX2:执行insert...select语句b表上的记录(996,997,998,999,2995,2996,2997,2998,2999)会申请加上LOCK_S,因为上锁是有一个逐步加锁的过程,假设此时加锁到2997前那么TX2并不会等待
TX1:执行update需要获得表b主键id=999的LOCK_X显然这个记录已经被TX2加锁LOCK_S,只能等待
TX2:继续加锁LOCK_S 2997、2998、2999 发现2999已经被TX1加锁LOCK_X,只能等待,触发死锁检测
如下图红色记录为不能获得锁的记录: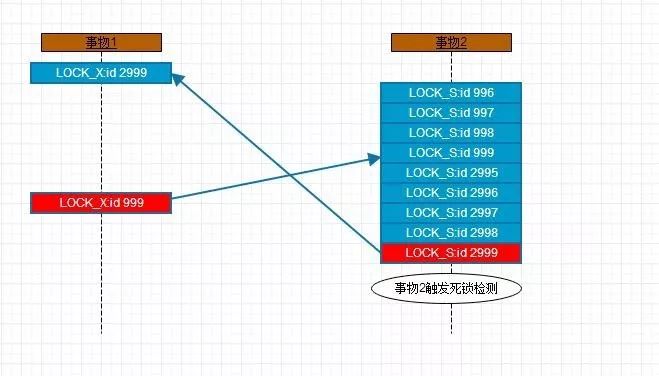
五、源码修改和参数增加
场景二需要在特定的高并发下才会出现,因为在 高并发场景下,很难认为控制 INSERT SELECT (逐行加锁的)过程,没办法让它在特定条件下停止,好让我们对其进行观察。
因此,为了能够模拟出这种情况,笔者对innodb增加了4个参数用于设置加锁断点(加锁过程中临时sleep下):
mysql> show variables like '%gaopeng%'; +---------------------------+-------+ | Variable_name | Value | +---------------------------+-------+ | innodb_gaopeng_sl_heap_no | 0 | | innodb_gaopeng_sl_ind_id | 0 | | innodb_gaopeng_sl_page_no | 0 | | innodb_gaopeng_sl_time | 0 | +---------------------------+-------+这几个参数默认情况都是0,即不启用。它们的作用如下:
innodb_gaopeng_sl_heap_no:记录所在的heap no
innodb_gaopeng_sl_ind_id:记录所在的index_id
innodb_gaopeng_sl_page_no:记录所在的page_no
innodb_gaopeng_sl_time:睡眠多少秒 有了index_id、page_no、heap no 就能唯一限定某条记录了,并且睡眠等待时间也可以人为指定的。
并且在源码 lock_rec_lock 开头增加如下代码: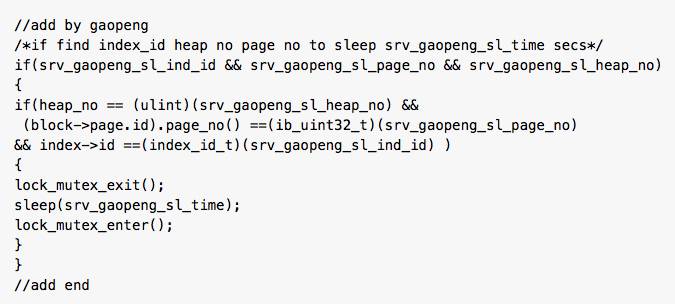
这样一旦判定为符合条件的记录,本条记录加锁前便会睡眠指定时长。如果我们设定在LOCK_S:id=2997之前睡眠30秒,那么场景二必定发生如下图所示加锁过程: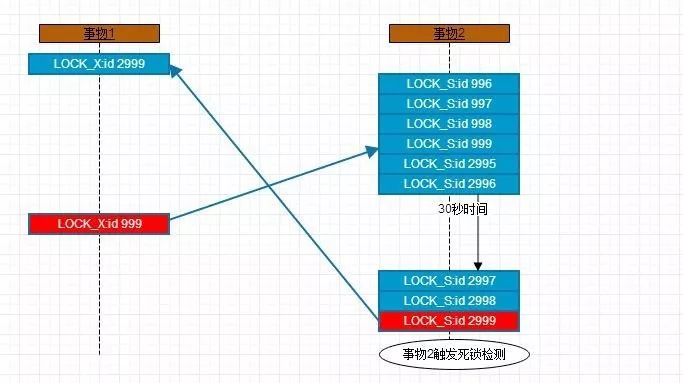
六、实际测试
6.1、场景一
| TX1 | TX2 |
|---|---|
| begin; | |
| update b set name2='test' where id=2999;对id:2999加LOCK_X锁 | |
| insert into a select * from b where id in (996,997,998,999,2995,2996,2997,2998,2999);对id:996,997,998,999,2995,2996,2997,2998加LOCK_S锁,但是对id:2999加LOCK_S锁时发现已经加LOCK_X锁,需等待 | |
| update b set name2='test' where id=999;对id:999加LOCK_X锁,但是发现已经加LOCK_S锁,需等待,触发死锁检测 | |
| TX1触发死锁,TX1在权重判定下回滚 |
死锁报错语句:
mysql> update b set name2='test' where id=999; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction死锁日志: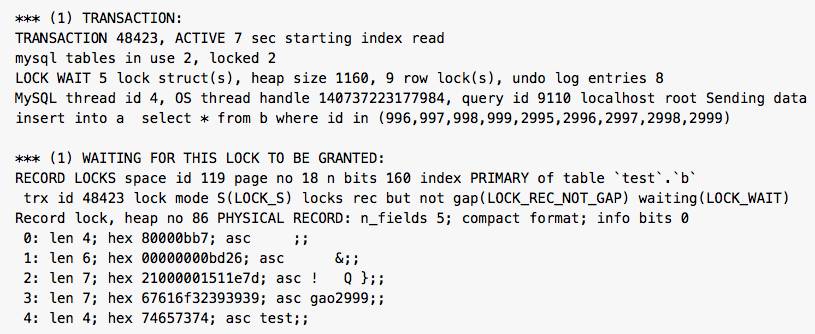

死锁信息提取如下:
6.1、场景二
我们设定在下面的语句加断点:
mysql> insert into a select * from b
where id in (996,997,998,999,2995,2996,2997,2998,2999)对B表记录加锁时在id = 2997加锁前停顿30秒,那么我就需要找到B表主键2997的index_id、page_no、heap_no三个信息,这里使用到我的innblock工具
因为初始化时是顺序插入数据,那么 id = 2997必定到page 18中。 扫描page 18: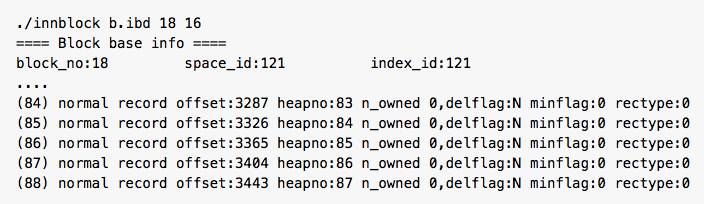
我们按照插入顺序推断出heap_no 84就是id=2997的记录。我们使用另外一个工具bcview进行验证:
./bcview b.ibd 16 3326 4 current block:00000018--Offset:03326--cnt bytes:04--data is:80000bb5当然16进制 0Xbb5 的值就是 2997。
因此设置参数为:
innodb_gaopeng_sl_heap_no=84; innodb_gaopeng_sl_ind_id=121; innodb_gaopeng_sl_page_no=18; innodb_gaopeng_sl_time=30; mysql> show variables like '%gaopeng%'; +---------------------------+-------+ | Variable_name | Value | +---------------------------+-------+ | innodb_gaopeng_sl_heap_no | 84 | | innodb_gaopeng_sl_ind_id | 121 | | innodb_gaopeng_sl_page_no | 18 | | innodb_gaopeng_sl_time | 30 | +---------------------------+-------+那么 场景二 的执行顺序如下:
| TX1 | TX2 |
|---|---|
| begin; | |
| update b set name2='test' where id=2999; 对id:2999加LOCK_X锁 | |
| insert into a select * from b where id in (996,997,998,999,2995,2996,2997,2998,2999);对id:在加锁到996,997,998,999,2995,2996加LOCK_S锁,在对id:2997加锁前睡眠30秒,为下面的update语句腾出时间) | |
| update b set name2='test' where id=999;对id:999加LOCK_X锁等待但发现已经加LOCK_S锁,需等待 | |
| 醒来后继续对2997、2998、2999加LOCK_S锁,但是发现id:2999已经加LOCK_X锁,需等待,触发死锁检测 | |
| TX1权重回滚 |
死锁报错语句:
mysql> update b set name2='test' where id=999; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction死锁日志: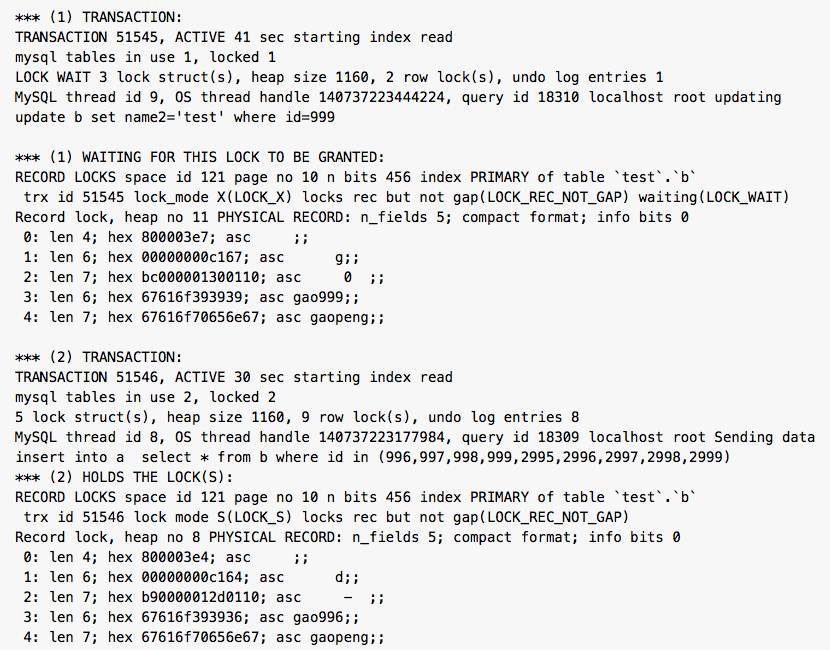
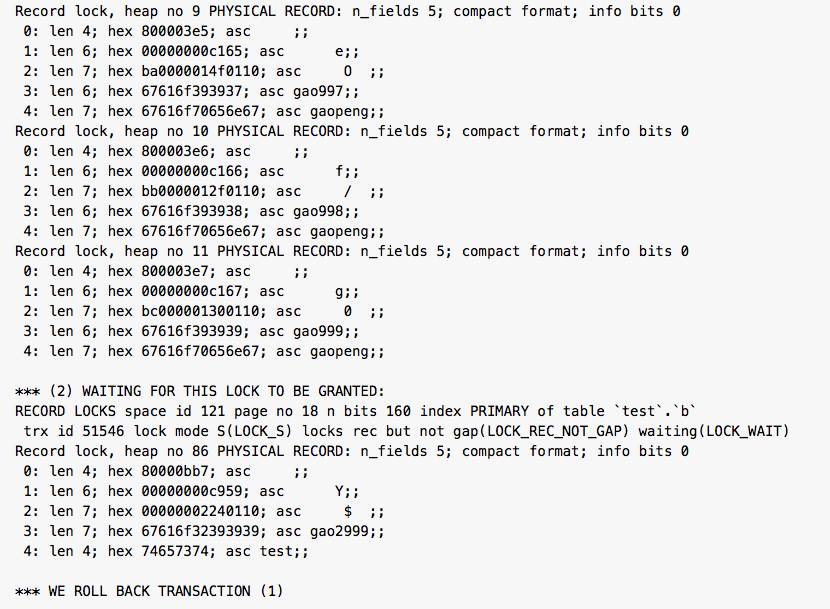
死锁信息提取如下:
通过死锁日志明显能看出同样的语句报出来的死锁信息却不一样,确认在高并发下相同语句,两种死锁场景都是可能发生的。
七、总结
分析死锁一般要从死锁日志中获取如下信息
1、加锁发生在主键还是辅助索引;
2、加锁的模式是什么;
3、是单行还是多行加锁;
4、触发死锁事务最后的语句;
5、死锁信息中事务顺序是怎么样的;
在重现死锁过程的时候,必须要做到和线上死锁信息完全匹配,这个死锁场景才算测试成功了。从本次的例子我们就发现,同样的语句产生的死锁信息却不一样,我们当然就要按照不同的场景去考虑。 本文中的 场景二 比较复杂,一般只是在高并发先出现,测试也相对麻烦。本文通过修改源码的方式进行测试的,否则很难重现。
最后,找到死锁原因后就需要采取必要的措施,比如本文中的例子需要考虑几个方案:
对INSERT SELECT中SELECT表的修改是否及时提交;
INSERT SELECT是否可以用其他方式代替,因为这种语句在自增锁上也存在一定风险;
是否考虑使用RC隔离级别,在RC隔离级别下不存在对SELECT表记录加锁的情况。
最后再强调一点,对于出现LOCK_S这样的锁最好深入分析,因为这种锁并不多见。
对本文有任何疑问可扫码添加原文作者微信
以上是关于InnoDB RR隔离级别下INSERT SELECT两种死锁案例剖析的主要内容,如果未能解决你的问题,请参考以下文章