记一次死锁的徒手debug
Posted Jacob的咖啡屋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次死锁的徒手debug相关的知识,希望对你有一定的参考价值。
我特么花了两天时间找到这个bug
Construct
两个生产者消费者模型, 架构如图
file_path_worker_do筛选出符合条件的任务丢入_wait_parse_Queue多进程
parse_xml_worker处理这些任务, 产生的结果丢入_parsed_to_push_Queuepush_es_worker持续监控_parsed_to_push_Queue, 每当到达_push_batch_size个任务时, 建立一个新线程,线程用于 向 ES 服务器提交入库请求, 得到 ES 端反馈后结束
Phenomenon
当逻辑上处理完任务后, 主进程处于挂起状态, 无法正常退出,
程序处于如下状态:

Annotate
第一个 13782 为 Reactor 进程, 负责模块架构的构建
file_path_worker_do正常终止其余为
parse_xml_worker进程组. 测试机有6核, 可知有一个正常终止, 图里后5个为, SL+,状态,即sleeping and lockpush_es_worker进程也是正常终止
Infer-1
probably
parse_xml_worker 死锁导致, 怀疑 multiprocessing. Queue 等待 goods 进入, 而挂起
verify
parse_xml_worker 中给 Queue.get() 加超时参数, 如果无限期挂起, 必然会出发 Empty 异常
result
试验测试, 没有发生异常, 说明 Queue 正常
Infer-2
probably
代码没有运行完?
verify
在 parse_xml_worker 代码结尾输出 log

result
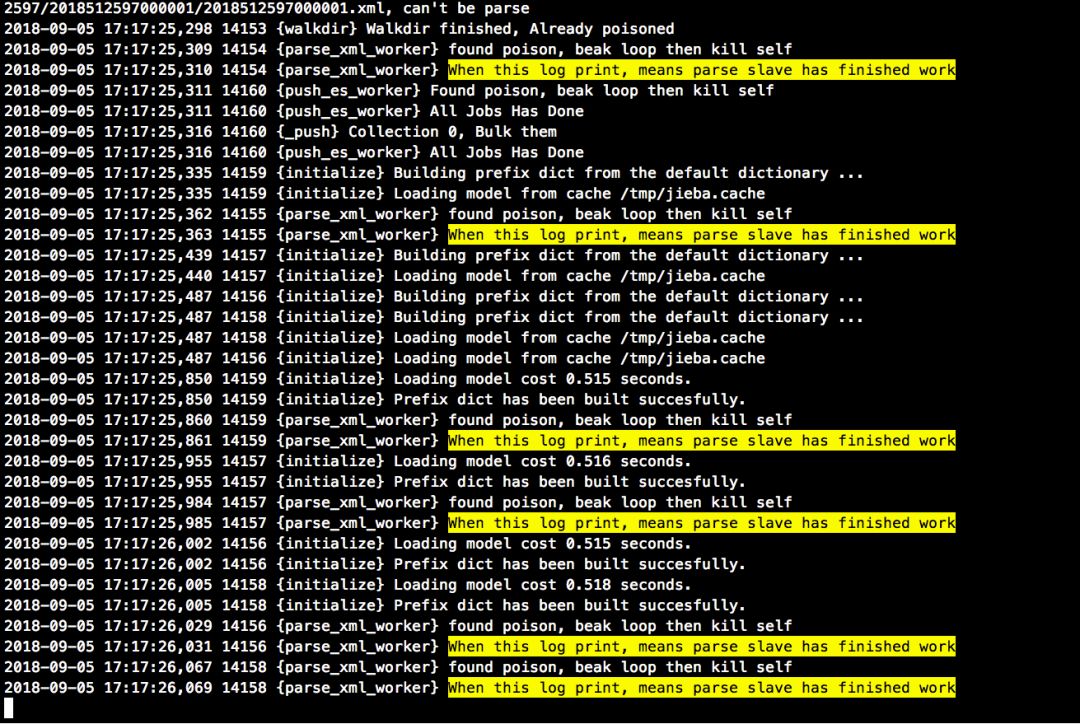
首先, 一共 6 条对应输出, 说明 6 个进程都在逻辑上的运行到 code 末尾,
再次验证
Queue入队出队正常, 没有因为Queue而休眠
Infer-3
probably
ps 进程状态指示进程处于 SL+ 状态...
Manual ps:
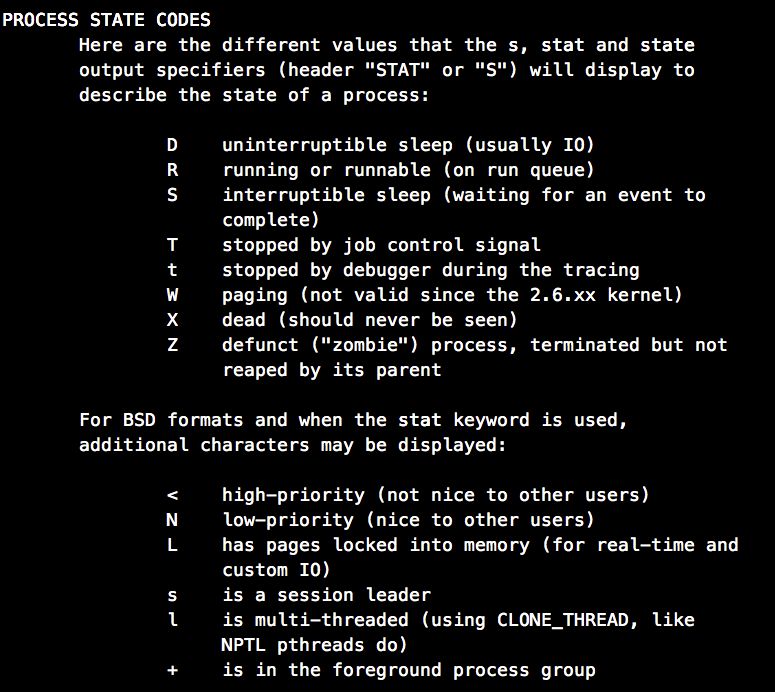
S -- 等待事件结束
L -- 有内存页被锁在内存
一个合理的推论是, 代码运行完了, 准备销毁进程, 但是有资源被锁定, 所以等待资源回收, 而资源迟迟不能被回收, 所以.....
梳理了一下, 涉及到资源操作的, 只有队列和文件操作.,难道是文件描述符?
verify
神器 lsof, 因为业务逻辑处理的是一些以 xml 结尾的文件, 所以直接找
result

还是没有, 再次推翻
没办法, 只能一句一句排除了
此处经过 1.5 个工时, 学习了
pdb
gdb
gdb 与 python3.6 不兼容
编译 gdb8.1
so on....
又是踩了无数坑,
最后定位到与 push_es_worker有关
Infer-infinity
下面是 push_es_worker 实现, 剥离业务逻辑后:
def `push_es_worker`(self):
while True:
wait_to_push = list()
while (len(wait_to_push) < self._push_batch_size):
transed_json = self.`_parsed_to_push_Queue`.get()
if isinstance(transed_json, Poison):
poison = transed_json
'''Time to Die'''
logging.info("Found poison, beak loop then kill self")
logging.info("All Jobs Has Done")
self.`_parsed_to_push_Queue`.put(poison)
break
else:
wait_to_push.append(transed_json)
首先是个死循环, 从队列中取值
判断是否为毒丸, 是的话就退出,不是就消耗
为了确定是否为 push_es_worker 导致,
将原来的 push_es_worker剥离, 用纯粹的 consumer 代替.
def consumer(self):
time.sleep(5)
while True:
self.`_parsed_to_push_Queue`.get(timeout=5)
发现此处会出现 get 超时,
但是此时所有进程正常结束,
由于 push_es_worker 与 parse_xml_worker 是同级别的进程,
理论上讲, push_es_worker 出现 Empty 异常不会影响挂起的 push_es_worker 退出..
同时, 放慢 consumer 发现有趣的现象,
def consumer(self):
while True:
time.sleep(5)
p = self.`_parsed_to_push_Queue`.get(timeout=5)
logging.info(f"acquire one goods: {type(p)}")
logging.info(f"sleep 5s")
此次运行结果:
进程是一个一个释放的, 说明consumer 每消耗一个, 就会导致
parse_xml_worker唤醒并终止
probably:
至此, 可以断定是 Queue 底层实现, 当一个进程将 goods 放入队列后, 该进程并未和 Queue 完全脱离关系, 只有被消费掉才能算是可以终止, 印证了ps 时, 显示的 lock 状态, 由于 goods 未被消费掉, 导致内存页被锁定
verify
查官方文档 https://docs.python.org/3/library/multiprocessing.html
坑-1
Note When an object is put on a queue, the object is pickled and a background thread later flushes the pickled data to an underlying pipe. This has some consequences which are a little surprising, but should not cause any practical difficulties – if they really bother you then you can instead use a queue created with a manager.
After putting an object on an empty queue there may be an infinitesimal delay before the queue’s empty() method returns False and get_nowait() can return without raising queue.Empty. If multiple processes are enqueuing objects, it is possible for the objects to be received at the other end out-of-order. However, objects enqueued by the same process will always be in the expected order with respect to each other.
当进程将 goods put 进 Queue 时, 并不是直接放进去, 而是先 pickle 然后等待一个线程将其真正写进 pipe 中
坑-2
由 坑-1 导致的 坑2..
As mentioned above, if a child process has put items on a queue (and it has not used JoinableQueue.canceljointhread), then that process will not terminate until all buffered items have been flushed to the pipe.
This means that if you try joining that process you may get a deadlock unless you are sure that all items which have been put on the queue have been consumed. Similarly, if the child process is non-daemonic then the parent process may hang on exit when it tries to join all its non-daemonic children.
进程准备销毁时, 由于并未将所有资源放入 pipe 中, 会导致进程挂起, 导致死锁, 直到消费者消费掉
而 push_es_worker的逻辑是, 发现毒丸,马上终止自己, 导致没有消费者消费 parse_xml_worker 产生的资源, 也就无法唤醒 parse_xml_worker, 所以造成死锁
真特码的坑
Solution:
文档中有一句:
Note that a
Queuecreated using a manager does not have this issue. See Programming guidelines.
使用 manager 管理资源可以避免该问题, 但是我发现这是采用 sever 架构, 感觉我没必要,
既然只要保证 goods 被完全消耗掉, 那我就不在 push_es_worker 判断毒丸了, 而是死循环 get 队列
Terminal:
死锁解决,
然而, 两天过去了.
Queue 这个坑, 这辈子都不会忘了.
另外还有个问题:
TODO:
为什么那边
push_es_worker没有消耗 goods, 底层的 thread 就不把 pikled goods 放入underlying pipe 呢?建立Queue的时候明明是设定了 1000 的 maxsize 的啊...
待我有空,看看源码再解决这个问题
以上是关于记一次死锁的徒手debug的主要内容,如果未能解决你的问题,请参考以下文章