中文项目:快速识别验证码,CNN也能为爬虫保驾护航
Posted 机器学习研究组订阅号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文项目:快速识别验证码,CNN也能为爬虫保驾护航相关的知识,希望对你有一定的参考价值。
随着卷积网络的推广,现在有各种各样的快捷应用,例如识别验证码和数学公式等。本文介绍了一个便捷的验证码识别项目,读者可以借助它快速训练模型与识别验证码。
本项目使用卷积神经网络识别字符型图片验证码,其基于 TensorFlow 框架。它封装了非常通用的校验、训练、验证、识别和调用 API,极大地减低了识别字符型验证码花费的时间和精力。
1 项目介绍
1.1 关于验证码识别
验证码识别大多是爬虫会遇到的问题,也可以作为图像识别的入门案例。这里介绍一下使用传统的图像处理和机器学习算法,它们都涉及多种技术:
图像处理
前处理(灰度化、二值化)
图像分割
裁剪(去边框)
图像滤波、降噪
去背景
颜色分离
旋转
机器学习
KNN
SVM
使用这类方法对使用者的要求较高,且由于图片的变化类型较多,处理的方法不够通用,经常花费很多时间去调整处理步骤和相关算法。
而使用卷积神经网络,只需要通过简单的前处理,就可以实现大部分静态字符型验证码的端到端识别,效果很好、通用性很高。
这里列出目前常用的验证码生成库:

1.2 目录结构
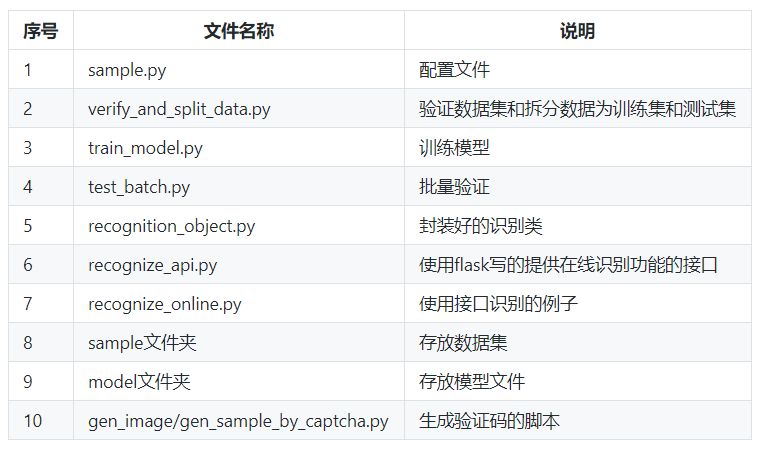
1.3 依赖项
tensorflow
flask
requests
PIL
matplotlib
pip3 install tensorflow flask requests PIL matplotlib
1.4 模型结构
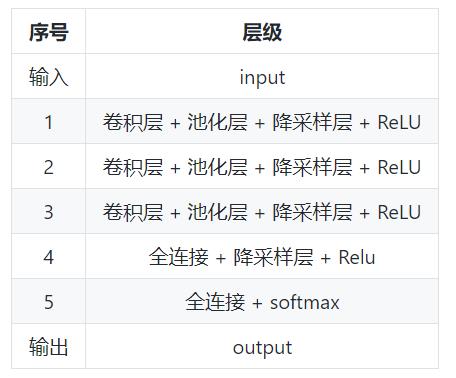
2 如何使用
2.1 数据集
原始数据集可以存放在./sample/origin 目录中,为了便于处理,图片最好以 2e8j_17322d3d4226f0b5c5a71d797d2ba7f7.jpg 格式命名(标签_序列号. 后缀)。
2.2 配置文件
创建一个新项目前,需要自行修改相关配置文件:
图片文件夹
sample_conf.origin_image_dir = "./sample/origin/" # 原始文件
sample_conf.train_image_dir = "./sample/train/" # 训练集
sample_conf.test_image_dir = "./sample/test/" # 测试集
sample_conf.api_image_dir = "./sample/api/" # api接收的图片储存路径
sample_conf.online_image_dir = "./sample/online/" # 从验证码url获取的图片的储存路径
# 模型文件夹
sample_conf.model_save_dir = "./model/" # 训练好的模型储存路径
# 图片相关参数
sample_conf.image_width = 80 # 图片宽度
sample_conf.image_height = 40 # 图片高度
sample_conf.max_captcha = 4 # 验证码字符个数
sample_conf.image_suffix = "jpg" # 图片文件后缀
# 验证码字符相关参数
# 验证码识别结果类别
sample_conf.char_set = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i',
'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
# 验证码远程链接
sample_conf.remote_url = "https://www.xxxxx.com/getImg"
具体配置的作用会在使用相关脚本的过程中提到。
2.3 验证和拆分数据集
执行下面的文件会校验原始图片集的尺寸和测试图片是否能打开,并按照 19:1 的比例拆分出训练集和测试集。所以需要分别创建和指定三个文件夹:origin,train,test 用于存放相关文件。
也可以修改为不同的目录,但是最好修改为绝对路径。文件夹创建好之后,执行以下命令即可:
python3 verify_and_split_data.py
2.4 训练模型
创建好训练集和测试集之后,就可以开始训练模型了,这里不具体介绍 tensorflow 安装相关问题,读者可查看官网。确保图片相关参数和目录设置正确后,执行以下命令开始训练:
python3 train_model.py
也可以调用类开始训练或执行一次简单的识别演示:
from train_model import TrainModel
from sample import sample_conf
# 导入配置
train_image_dir = sample_conf["train_image_dir"]
char_set = sample_conf["char_set"]
model_save_dir = sample_conf["model_save_dir"]
tm = TrainModel(train_image_dir, char_set, model_save_dir)
tm.train_cnn() # 执行训练
tm.recognize_captcha() # 识别演示
2.5 批量验证
使用测试集的图片进行验证,输出准确率。
python3 test_batch.py
也可以调用类进行验证:
from test_batch import TestBatch
from sample import sample_conf
# 导入配置
test_image_dir = sample_conf["test_image_dir"]
model_save_dir = sample_conf["model_save_dir"]
char_set = sample_conf["char_set"]
total = 100 # 验证的图片总量
tb = TestBatch(test_image_dir, char_set, model_save_dir, total)
tb.test_batch() # 开始验证
2.6 启动 WebServer
项目已经封装好加载模型和识别图片的类,启动 web server 后调用接口就可以使用识别服务。启动 web server:
python3 recognize_api.py
接口 url 为 http://127.0.0.1:6000/b
2.7 调用接口
使用 requests 调用接口:
url = "http://127.0.0.1:6000/b"
files = {'image_file': (image_file_name, open('captcha.jpg', 'rb'), 'application')}
r = requests.post(url=url, files=files)
返回的结果是一个 json:
{
'time': '1542017705.9152594',
'value': 'jsp1',
}
文件 recognize_online.py 是使用接口在线识别的例子。
想要了解更多资讯,请扫描下方二维码,关注机器学习研究会
以上是关于中文项目:快速识别验证码,CNN也能为爬虫保驾护航的主要内容,如果未能解决你的问题,请参考以下文章