用“活着的”CNN 进行验证码识别
Posted 创宇前端
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用“活着的”CNN 进行验证码识别相关的知识,希望对你有一定的参考价值。
1. 验证码
验证码( CAPTCHA )是一种区分用户是计算机或人的公共全自动程序。在 CAPTCHA 测试中,作为服务器的计算机会自动生成一个问题由用户来解答。这个问题可以由计算机生成并评判,但是必须只有人类才能解答。由于计算机无法解答 CAPTCHA 的问题,所以回答出问题的用户就可以被认为是人类。
2. CNN 验证码识别
传统的方法是通过两个不相关的步骤来进行文字识别:1)将图片中的文字的位置进行定位,然后通过“小框”来切分,将图片中的文字剪切下来 2)再进行识别。但是在现今的验证码识别中,当要识别的图片中的文字变成手写体互相重叠,这种“切分”法就难以排上用场。因此卷积神经网络(CNN)就被用来识别这些无从下手的手写体。这种CNN 是通过一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成来对图像识别。CNN 训练模型需要大量的人工标注的图片来训练,但是本文方法就是自主产生随机的字符并产生相应的图片来在运行过程中调整参数。
本文关注具有 4 个字符的的验证码图片。每个字符在输出层被表现为 62 个神经元。我们可以假设一个映射函数
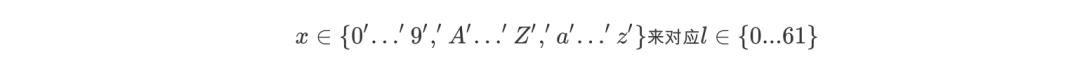
即:
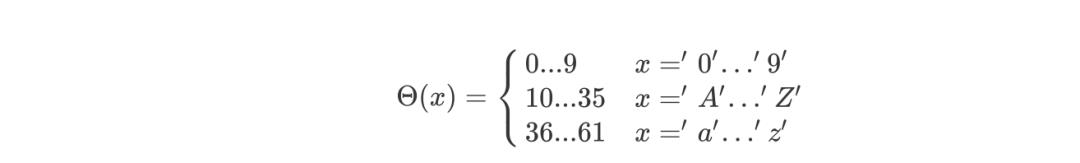
将前 62 个神经元分配给序列中的第一个字符,第二批 62 个神经元分配给序列中的第二个字符。因此,对于字符xi
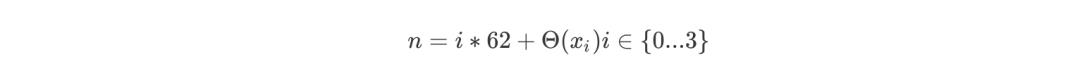
所对应的神经元的索引为
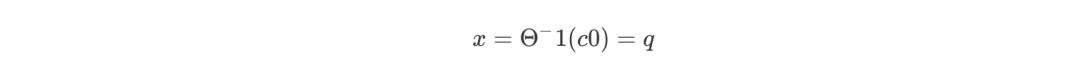
输出层一共有 4*62=128 个。如果第一个预测字符的索引为 c0=52,因此可以反推预测的字符为
3. 验证码生成实现步骤
3.1. 验证码中的字符
number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
ALPHABET = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U',
'V', 'W', 'X', 'Y', 'Z']
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
'v', 'w', 'x', 'y', 'z']
gen_char_set = number + ALPHABET # 用于生成验证码的数据集
3.2. 生成验证码中的字符
# char_set=number + alphabet + ALPHABET,
char_set=gen_char_set,
# char_set=number,
captcha_size=4):
"""
生成随机字符串,4位
:param char_set:
:param captcha_size:
:return:
"""
captcha_text = []
for i in range(captcha_size):
c = random.choice(char_set)
captcha_text.append(c)
return captcha_text
3.3. 按照字符生成对应的验证码
def gen_captcha_text_and_image():
"""
生成字符对应的验证码
:return:
"""
image = ImageCaptcha()
captcha_text = random_captcha_text()
captcha_text = ''.join(captcha_text)
captcha = image.generate(captcha_text)
captcha_image = Image.open(captcha)
captcha_image = np.array(captcha_image)
return captcha_text, captcha_image
4. 训练
传统的方法是通过两个不相关的步骤来进行文字识别:1)将图片中的文字的位置进行定位,然后通过“小框”来切分,将图片中的文字剪切下来
2)再进行识别。但是在现今的验证码识别中,当要识别的图片中的文字变成手写体互相重叠
,这种“切分”法就难以排上用场。因此卷积神经网络(CNN)就被用来识别这些无从下手的手写体。这种CNN是通过一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成来对图像识别。CNN 训练模型需要大量的人工标注的图片来训练,但是本文方法就是自主产生随机的字符并产生相应的图片来在运行过程中调整参数。
def crack_captcha_cnn(w_alpha=0.01, b_alpha=0.1):
"""1
定义CNN
cnn在图像大小是2的倍数时性能最高, 如果你用的图像大小不是2的倍数,可以在图像边缘补无用像素。
np.pad(image,((2,3),(2,2)), 'constant', constant_values=(255,)) # 在图像上补2行,下补3行,左补2行,右补2行
"""
x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1])
# w_c1_alpha = np.sqrt(2.0/(IMAGE_HEIGHT*IMAGE_WIDTH)) #
# w_c2_alpha = np.sqrt(2.0/(3*3*32))
# w_c3_alpha = np.sqrt(2.0/(3*3*64))
# w_d1_alpha = np.sqrt(2.0/(8*32*64))
# out_alpha = np.sqrt(2.0/1024)
# 3 conv layer
w_c1 = tf.Variable(w_alpha * tf.random_normal([3, 3, 1, 32]))
b_c1 = tf.Variable(b_alpha * tf.random_normal([32]))
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv1 = tf.nn.dropout(conv1, keep_prob)
w_c2 = tf.Variable(w_alpha * tf.random_normal([3, 3, 32, 64]))
b_c2 = tf.Variable(b_alpha * tf.random_normal([64]))
conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2))
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv2 = tf.nn.dropout(conv2, keep_prob)
w_c3 = tf.Variable(w_alpha * tf.random_normal([3, 3, 64, 64]))
b_c3 = tf.Variable(b_alpha * tf.random_normal([64]))
conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3))
conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv3 = tf.nn.dropout(conv3, keep_prob)
# Fully connected layer
w_d = tf.Variable(w_alpha * tf.random_normal([8 * 20 * 64, 1024]))
b_d = tf.Variable(b_alpha * tf.random_normal([1024]))
dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]])
dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d))
dense = tf.nn.dropout(dense, keep_prob)
w_out = tf.Variable(w_alpha * tf.random_normal([1024, MAX_CAPTCHA * CHAR_SET_LEN]))
b_out = tf.Variable(b_alpha * tf.random_normal([MAX_CAPTCHA * CHAR_SET_LEN]))
out = tf.add(tf.matmul(dense, w_out), b_out) # 36*4
# out = tf.reshape(out, (CHAR_SET_LEN, MAX_CAPTCHA)) # 重新变成4,36的形状
# out = tf.nn.softmax(out)
return out

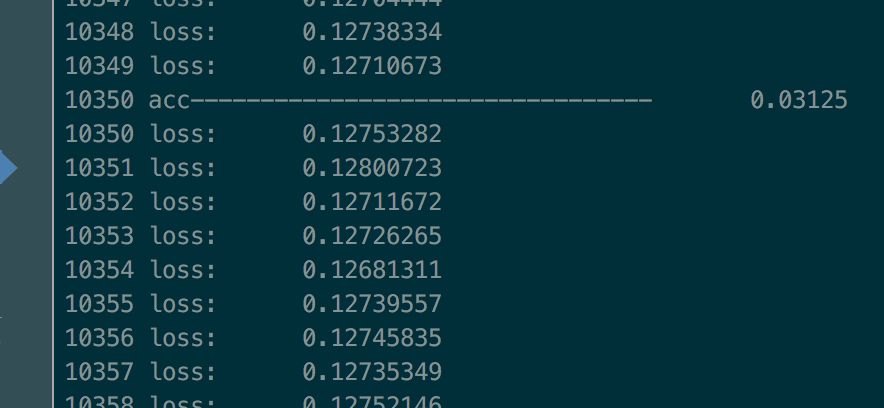
由于时间和设备的限制,我在验证码生成字符串中删去了英文字母只剩下了数字进行训练。要不然可以算到地老天荒也还是3%的准确率。下图是gen_char_set = number + ALPHABET的训练1万多步的结果的训练截图:
5. 总结
本文采用了“活着的 CNN”进行验证码识别,可以免去大量进行人工标注的步骤,对工作效率有不小的提升。
文 / JoeCDC
数学爱好者
编 / 荧声
感谢您的阅读
欢迎关注、点赞、留言讨论、分享转发支持我们
经常错过推送?
以上是关于用“活着的”CNN 进行验证码识别的主要内容,如果未能解决你的问题,请参考以下文章