AI初探图形验证码识别
Posted 新大陆软件评测中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI初探图形验证码识别相关的知识,希望对你有一定的参考价值。
No.1
前言
图形验证码在各种应用和系统中是非常常见的功能,诞生之初主要是为了防止恶意破解密码、刷票、论坛灌水等异常操作,是个好东西。但在实施自动化测试、生产系统的业务探测等一些系统保障活动时却是个不小的麻烦,所以在这些特定场景中,强烈需要能够自动识别它。
传统的图形验证码识别,如Tesseract OCR、OpenCV等方法,都需要对验证码进行分割,且遇到字符连接、重叠的情况下,识别率极低。其实,这也是正常的,因为图形验证码英文为:Captcha,全称是Completely Automated Public Turing Test to Tell Computers and Humans Apart (全自动区分计算机和人类的图灵测试)。一个高大上的名字,但也总觉得哪里不对——图灵测试!!!,看来用传统方案应该是行不通了,尝试用当下红得发紫的AI方案看看能不能解决,本方案中我们选用CNN(卷积神经网络)进行尝试。
No.2
准备
首先,请某APP图形验证码功能的开发小哥帮忙生成21000个验证码,其中15000个作为训练集,5000个作为测试集,另外1000个作为训练完成后的验证集。(其实验证码集还可以再多一些的,那样训练效果更好。但因本次只是个demo,再加之本人的显卡比较弱,为了减少计算量,就没敢要太多)。
然后,我们来看看这批图形验证码有什么特点。本次要识别的验证码还是比较简单的,如下图所示。验证码是彩色的,其中的字符共4位,由大写字母、小写字母、数字,再加上一些噪点和干扰线组合而成:




另外,验证码中有不少字符重叠的情况,所以不便于分割处理,需要进行整体识别。
再来看验证码的文件名,如下图:

文件名就是图形验证码中的字符,也就是验证码的标签。这样就方便多了,可以省去CNN训练过程进行人工标记的操作。
No.3
实现
3.1
预处理
3.1.1 验证码图片处理
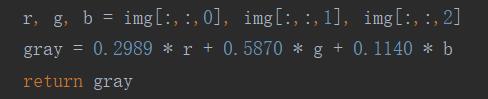
验证码图片是否是彩色的,对识别其实没有什么影响,反而还增加了计算量,所以可以将彩色的验图片转为灰度图片后再进一步处理。图片灰度化的方式如下:
首先将图片数组化:

然后就可以将图片灰度化了:
还有一种更快的方式,是用numpy来处理,如:

处理后的效果如下:


灰度化后
可以看到,虽然图片失去了色彩,但是丝毫不影响我们去识别其中的字符。
顺便说一下,有些方案中还会进行降噪处理,比如将灰度化后的验证码图片二值化,然后使用8邻域降噪,这样处理的目的是为了去除一些噪点。但本方案不进行降噪,主要原因是降噪过程有可能造成一些图片丢失重要的信息,因为相同的降噪参数不会可能满足所有的图片,甚至可能导致图片严重失真,无法辨别。更重要的是,我们做了的比较,在本方案中,不降进行噪处理,最后的识别效果并不比经过降噪处理的差。
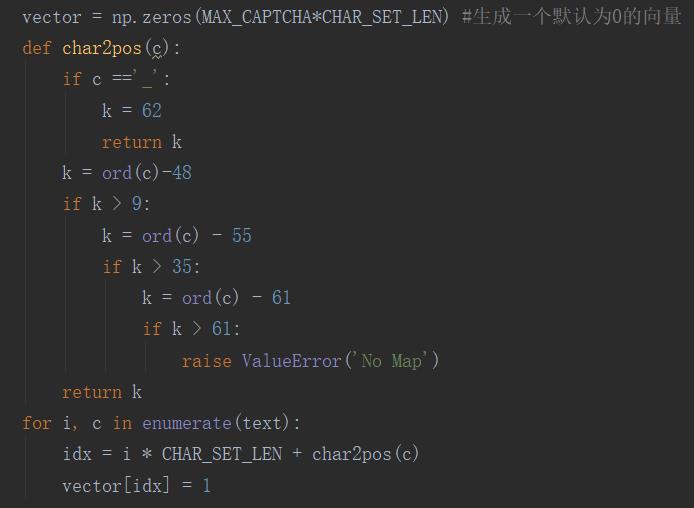
3.1.2 验证码标签文本转向量
张量是现代深度学习的基础,所以,在本方案中,不论是图片还是文本,我们都需要转化为张量来进行计算。
(PS:一维张量,也叫向量;二维张量,也叫矩阵;还有三维张量;四维张量......)
再回头看看我们需要识别的验证码,它是由0~1的数字,A~Z的大写字母,a~z的小写字母组成,所以验证码使用到的字符集共包含62个字符,如下所示:
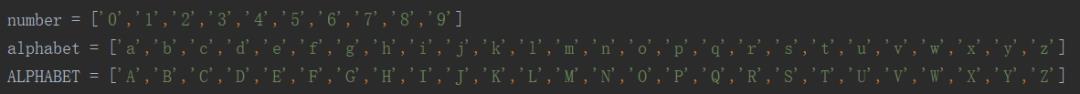
然后验证码共4位,每个位置的可能性如下:
第一个位置62种可能,第二个位置62种可能,第三个位置62种可能,第四个位置62种可能。
为了比较输出结果和真实值的正确性,可以先对每个位置进行one_hot编码。比如:以
['0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z','A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z']为特征,对验证码标签进行编码,假设验证码为“kh2W”,则编码后为:
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
这样,就能将验证码标签文本转为向量(我们暂且称之为“标签向量”)。部分代码如下:
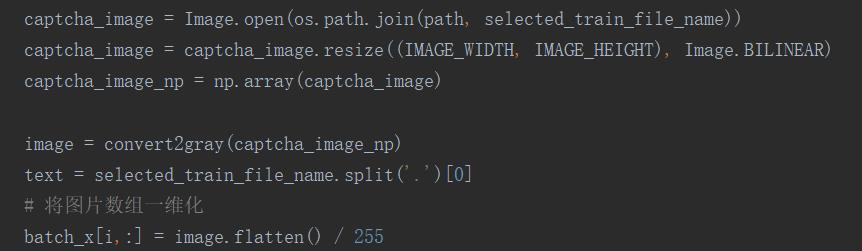
3.1.3 验证码图片转向量
文本转化为向量了,图片也需要转化为向量。
首先使用numpy将验证码图片转化为一个二维张量,而后将图片矩阵一维化,即转为向量。部分代码如下:
3.2
建模
本方案是基于CNN的,所以先要建立一个CNN模型。
3.2.1 CNN结构
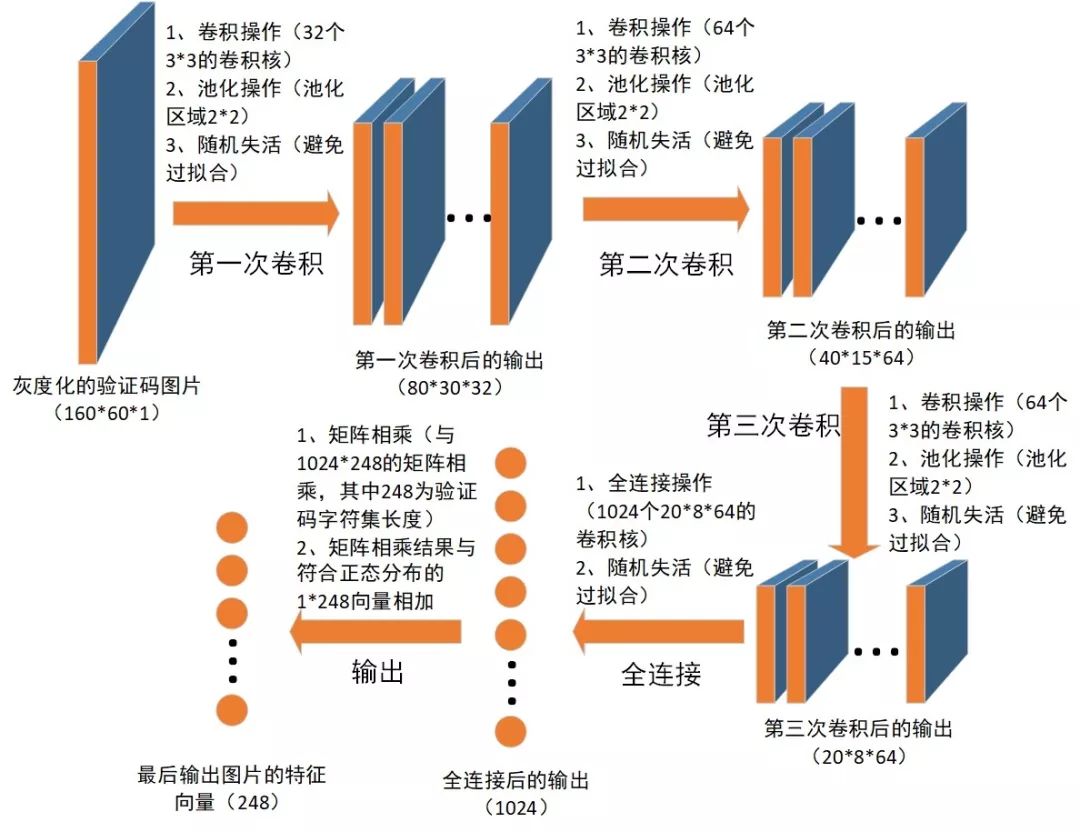
从上图可以看出,经过卷积后,最后将输出图片特征的一维张量(向量)。
3.2.2 采用Tensorflow框架建立CNN
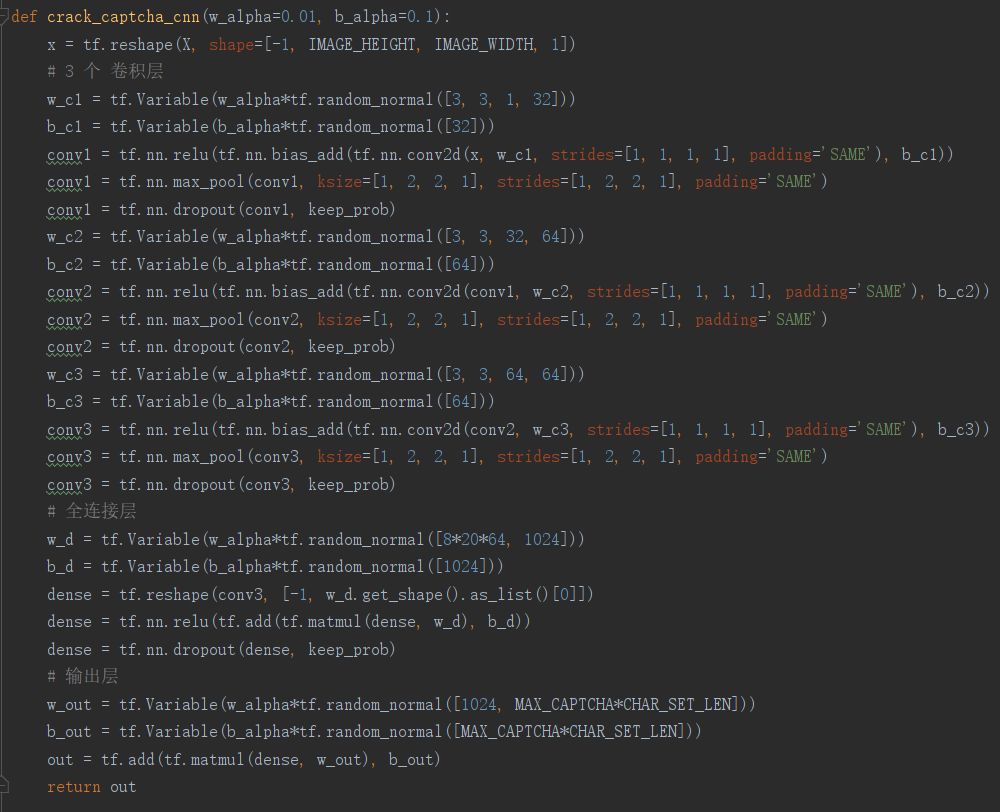
CNN代码如下:
3.2.3 模型衡量
有了模型,就需要衡量、评估模型的好坏。
3.2.3.1 衡量损失
先说2个概念:损失函数和交叉熵。
损失函数:损失函数是用来衡量模型的性能的,通过预测值和真实值之间的一些计算,得出的一个值,这个值在模型拟合的时候是为了告诉模型是否还有可以继续优化的空间(目的就是希望损失函数是拟合过的模型中最小的)。
交叉熵:主要用于度量两个概率分布间的差异性信息,在神经网络中可作为损失函数,如:p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
言归正传,图片经过上述CNN处理后的结果为一个[248]的向量,我们暂且称之为“图片向量”,然后需要将图片向量与标签向量进行进行交叉熵损失计算,得出损失大小,帮助提高四个位置的概率,使得4组中每组62个目标值中为1的位置对应的预测概率值越来越大,在预测的四组当中概率值最大的,即是得出图片中每组的字母位置。

3.2.3.2 计算准确率
将图片向量和标签向量转为[?,4,64]的张量,在每个验证码的第三个维度去进行比较,看看4个标签的目标值位置与预测概率位置是否相等,4个全相等,这个样本才预测正确。
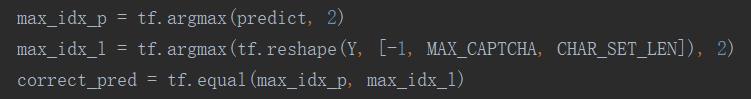
3.3
训练
一个神经网络的训练,就是让权重的值调整到最佳,损失函数最小化,以使得整个网络的预测效果最好。所以,在CNN模型建立完后,我们还需要对其进行训练。
我们在训练过程中,每批次采用 64 个训练样本,每50次迭代,就使用测试集计算一次准确率,如果准确率大于95%,则保存模型,完成训练。
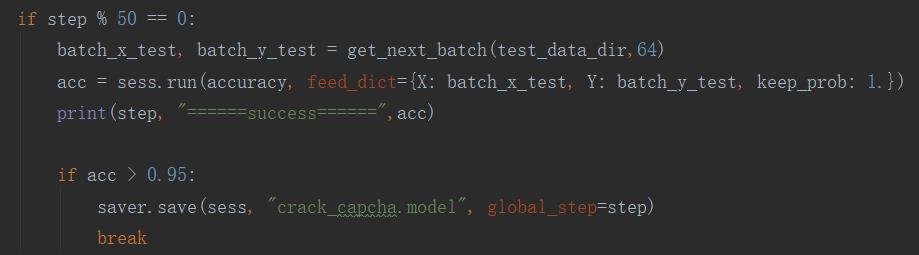
训练过程:
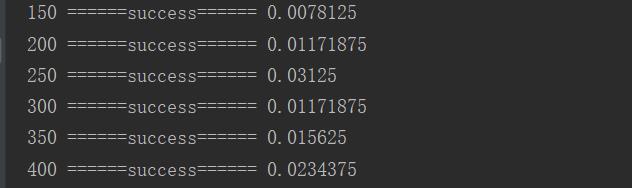
......以上省略具体训练过程。
最终经过了4200次迭代,准确率达到了95%。
No.4
模型验证
完成了训练,基本上算大功告成了。迫不及待的验证一下经过训练后的模型效果如何。
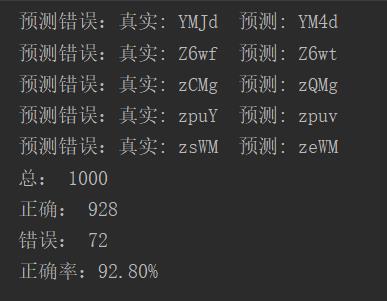
我们使用预先保留的验证集进行验证,从下图可以看出,1000张验证码中,有928张预测正确,72张预测错误,最终正确率92.8%。(预测,在本方案中即是识别)
我们挑几个预测错误的验证码看看是怎么个情况:
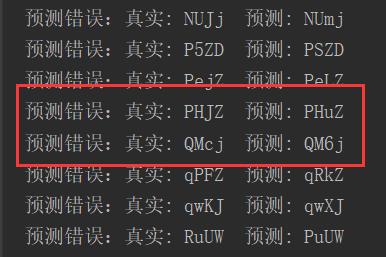

预测为“PHuZ”

预测为“QM6j”
从上面2张图看来,主要还是在遇到字符连接、重叠等情况的时候,预测效果较差。
但从整体看来,92.8%的正确率,效果还是可以接受的,毕竟有些验证码就算人工去识别,也不一定能正确识别,所以上述结果基本符合我们的要求。
以上就是一个初学者的简单图形验证码AI识别方案demo的思路和部分实现,如有错误之处,还请各位看官不吝指正。
END
新大陆软件评测中心
邮箱:nlsetc@newland.com.cn
专业测试,成就卓越
以上是关于AI初探图形验证码识别的主要内容,如果未能解决你的问题,请参考以下文章