验证码识别,这是一个爬虫开发人员绕不开的痛
Posted 码农小师妹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了验证码识别,这是一个爬虫开发人员绕不开的痛相关的知识,希望对你有一定的参考价值。
Tango,目前就职在一家对日开发的的IT服务公司。 不是科班出身的我,出于对编程的热爱,自学了软件开发。 从此深深陷入在代码的世界而无法自拔。 编辑:王老湿
情景演示
当我们访问 http://example.python-scraping.com/user/register 这个网站时,你会看到如下的画面:
红框中的内容就是验证码了。我们通过爬虫获取一下这个页面的内容
import requests
from lxml.html import fromstring
def parse_form(html):
tree = fromstring(html)
data = {}
for e in tree.cssselect('form input'):
if e.get('name'):
data[e.get('name')] = e.get('value')
return data
url = "http://example.python-scraping.com/user/register"
session = requests.session()
html = session.get(url)
form = parse_form(html.content) # 获取页面的表单
print(form)

需要安装一个cssselect库。pip install cssselect
这些表单内容我们都很好处理,如果要处理验证码,我们首先需要将它加载出来。
在Python中处理图像我们通常使用Pillow包,安装方法:pip install Pillow
我们通过如下代码来返回Image对象。
from io import BytesIO
from PIL import Image
import base64
def get_img(html):
tree = fromstring(html)
img_data = tree.cssselect('div#recaptcha img')[0].get('src')
img_data = img_data.partition(',')[-1]
binary_img_data = base64.b64decode(img_data)
img = Image.open(BytesIO(binary_img_data))
return img
完整代码如下:
import requests
from lxml.html import fromstring
from io import BytesIO
from PIL import Image
import base64
def parse_form(html):
tree = fromstring(html)
data = {}
for e in tree.cssselect('form input'):
if e.get('name'):
data[e.get('name')] = e.get('value')
return data
def get_img(html):
tree = fromstring(html)
img_data = tree.cssselect('div#recaptcha img')[0].get('src')
img_data = img_data.partition(',')[-1]
binary_img_data = base64.b64decode(img_data)
img = Image.open(BytesIO(binary_img_data))
return img
url = "http://example.python-scraping.com/user/register"
session = requests.session()
html = session.get(url)
form = parse_form(html.content) # 获取页面的表单
img = get_img(html.content) # 获取图片信息
print(img)
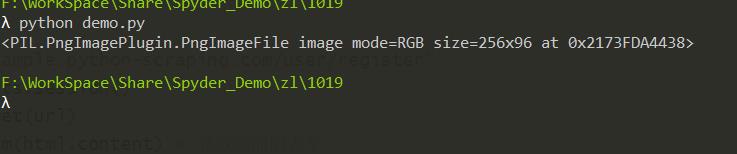
我们为了能从图片中识别出字符,接下来需要用到光学字符识别(OCR)技术。
Tesseract的使用
安装方法:pip install pytesseract
根据自己的系统下载对应的版本,我这边以Windows系统为例。
这时运行基本会报错:
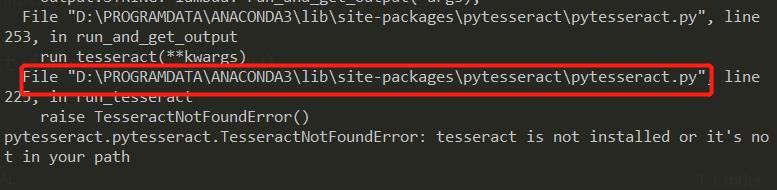
我们还需要修改一下源码,就是红框中的py文件。
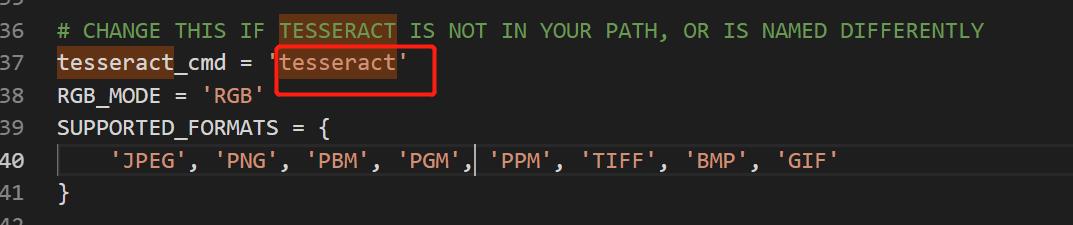
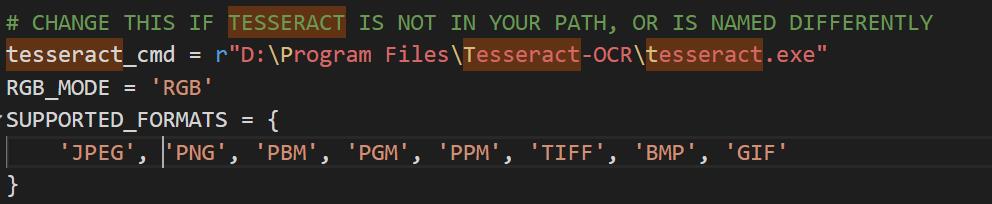
我们把红框中的内容换成我们软件的安装路经,以下是我的安装路径:
import pytesseract
str_info = pytesseract.image_to_string(img)
print(str_info)
通常我们如果直接去识别这个图片,很大可能会返回空字符串。这是因为这里面有背景噪音也就是干扰元素。
我们观察我们的验证码的文本颜色为黑色的,所以我们可以将图片中黑色部分分离出来,这个过程通常称为阈值化。
img.save('temp.png?raw=true')
new_img = img.convert('L') # 转化灰度图
new_img.save('temp2.png?raw=true')
bw = new_img.point(lambda x: 0 if x < 1 else 255,'1')
bw.save('temp3.png?raw=true')
运行后我们可以看到如下的图片,在我们脚本的同级目录下:
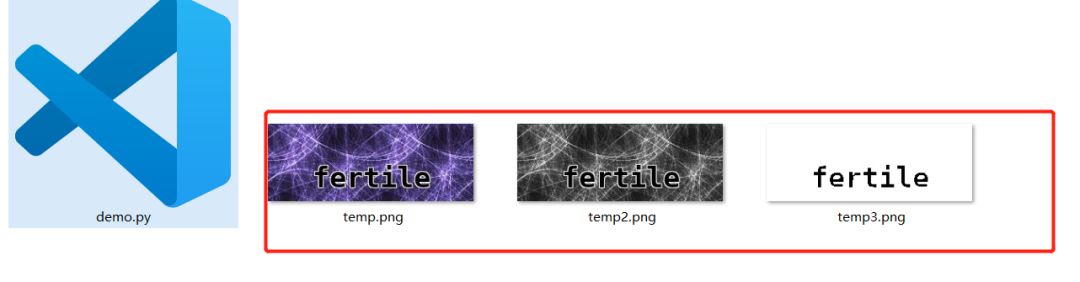
这样我们处理后的图片噪音就少了很多,再通过我们的pytesseract库来进行识别,这样的成功率会比较高。
完整代码:
import requests
from lxml.html import fromstring
from io import BytesIO
from PIL import Image
import base64
import pytesseract
def parse_form(html):
tree = fromstring(html)
data = {}
for e in tree.cssselect('form input'):
if e.get('name'):
data[e.get('name')] = e.get('value')
return data
def get_img(html):
tree = fromstring(html)
img_data = tree.cssselect('div#recaptcha img')[0].get('src')
img_data = img_data.partition(',')[-1]
binary_img_data = base64.b64decode(img_data)
img = Image.open(BytesIO(binary_img_data))
return img
url = "http://example.python-scraping.com/user/register"
session = requests.session()
html = session.get(url)
form = parse_form(html.content) # 获取页面的表单
img = get_img(html.content)
print(img)
img.save('temp.png?raw=true')
new_img = img.convert('L') # 转化灰度图
new_img.save('temp2.png?raw=true')
bw = new_img.point(lambda x: 0 if x < 1 else 255,'1')
bw.save('temp3.png?raw=true')
str_info = pytesseract.image_to_string(bw)
print(str_info)
运行效果:
我们可以看到图片上的内容被识别出来了。
问题
对于这样简单的验证码,即使成功率达不到100%也没关系,只要多请求几次还是可以成功的,但是要注意频率,要不然很容易被封IP。
除了这种简单的验证码之外,还有很多复杂的验证码,这时候我不建议大家花费太多精力在破解验证码上面。我们可以借助第三方工具或者打码平台甚至人工干预来绕过验证码。
好了,这期的内容就是这些,欢迎大家在留言区讨论。
点下「在看」,给文章盖个戳吧! 以上是关于验证码识别,这是一个爬虫开发人员绕不开的痛的主要内容,如果未能解决你的问题,请参考以下文章