向量空间验证码识别
Posted 拇指编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了向量空间验证码识别相关的知识,希望对你有一定的参考价值。
平时在登录账号的时,有时会进行验证码输入的操作。这步操作是为了防止非人类行为,就是防止机器人或者爬虫之类非人类角色的登录,避免服务器资源的浪费。
今天要说的验证码识别不是什么很高级的操作,没有用到常用的机器学习算法或者很深奥的深度学习神经网络算法来实现。就是简单的相似度对比操作,一个简单而又不错的想法来实现图片验证码的识别。

对于这张验证码,首先还是老样子先进行二值化处理将这个彩色图片变成黑白照片,然后把里面字母和数字切割成一张张图标,之后再提取每张图标中像素点的数值并存储为一个向量,类似<1,2,3,4>这样的值。然后在拿去和训练集(做好标签的验证码图标)去对比的计算相似度,就是计算两个向量的夹角cos值,而cos值越大说明夹角越小,两者越相似,最后选取值最大的对应的图标名做为识别出来的结果。
二值化
在进行二值化操作时,需要设定界限值,就是把那些颜色置黑那些置白。上面验证码图片中除了必要的红色还有其他杂色,因此需要统计一下图片中各类颜色点的数目。
from PIL import Imageim = Image.open('0q1d10.gif')im.convert('P') # 将图片转换为8位像素模式imList = im.histogram()values = {}for i in range(256):values[i] = imList[i]for j,k in sorted(values.items(), key=lambda x:x[1],reverse=True)[:10]:print(j,k)
通过上面代码可以得到图片中最多的10种颜色,其中220与227是我们需要的红色和灰色,由此我们就找到了界限值。然后就可以开始我们的二值化操作啦 !!
!!
from PIL import Imageim = Image.open('0q1d10.gif')im.convert('P') # 将图片转换为8位像素模式im2 = Image.new('P', im.size, 255)temp = {}# 构造黑白二值图片for x in range(im.size[1]):for y in range(im.size[0]):pix = im.getpixel((y,x))temp[pix] = pix# 220和227是需要的红色和灰色if pix==220 or pix==227:im2.putpixel((y,x),0)im2.show()
图片切割
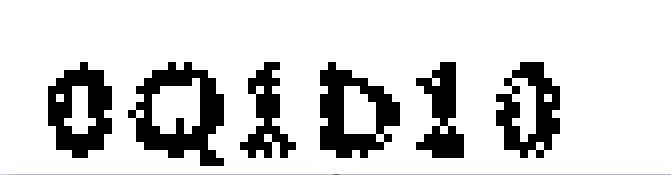
验证码此时已经二值化(像素点值只有0或255),我们需要把0、Q、1、b、1、0这6个字符切割出来单独去和训练集中数据进行对比。切割思路就是从左向右走,两层for循环即可,先列再行的遍历方式。
# 获取每个字符开始和结束的列序号inletter = Falsefoundletter = Falsestart = end = 0letters = []for y in range(im2.size[0]):for x in range(im2.size[1]):pix = im2.getpixel((y,x))if pix != 255:inletter = Trueif foundletter == False and inletter == True:foundletter = Truestart = yif foundletter == True and inletter == False:foundletter = Falseend = yletters.append((start, end))inletter = False#print(letters)
代码思路:向右走首先碰到0的最左端的黑色像素,然后插个小旗子标记开始位置,之后接着向右边走,走到刚好过了0的最右端黑色像素的白色像素点插上另一个小旗子标记结束位置。方法相同接着遇到Q、1、D、1、0这后面5个字符并且插好小旗子记录列标的位置。切割的时候就开始列标的左上端和结束列标的右下端两个点开始切割。
im = im.crop((letter[0],0,letter[1],im2.size[1]))

这里有个疑问就是为什么字符头顶和脚底的白色区域切割掉。因为这样方便,代码可以少些一点呀。 ,开玩笑。不过却是可以少些,如果要去除的话需要写三层循环来操作(写出来又要死不少脑细胞),这也是这个项目的缺点。缺点就是只能针对某一个应用的验证码去进行识别,要是添加其他应用的验证码会因为尺寸问题似的在相似度计算时误差很大。暂时先不考虑这个问题。
,开玩笑。不过却是可以少些,如果要去除的话需要写三层循环来操作(写出来又要死不少脑细胞),这也是这个项目的缺点。缺点就是只能针对某一个应用的验证码去进行识别,要是添加其他应用的验证码会因为尺寸问题似的在相似度计算时误差很大。暂时先不考虑这个问题。
图形向量化
对切割完成的小图标需要对其数值化,因为我们电脑不能直接使用图片格式操作(要是可以还要这么多操作嘛),因此我们需要把图片型数据变成数值型数据让计算机去进行操作。向量化过程就是图片的像数值存储在python字典当中便于后期操作。说到字典类型,虽存储相同数据量占的存储空间更大,是因为其中存储了索引结构,这就便于后面查找节省更多时间。可以说是用空间换时间的方法。
# 将图片转换为矢量def buildvector(im):d1 = {}count = 0for i in im.getdata():= icount += 1return d1
向量相似度计算
这里建立一个类对象方便后面代码的调用,关于向量空间的验证码识别不用觉得很厉害的样子,你可以认为就是向量<1,2>和<2,1>的夹角cos值计算就行了。顺便说一下它和很火热的机器学习、深度学习的图像识别的对比。
它不需要大量的训练迭代;不用担心过拟合现象;可以随时添加移除错误的数据查看效果;易理解和实现;提供分级结果;可以查看最接近的多个匹配;对于无法识别的东西只要加入到搜索引擎中,马上就能识别了。缺点就是分类的速度比神经网络慢很多,它不能找到自己的方法解决问题还有上面提到的(感觉优点比缺点多,废话,我写这个当然要多说优点啦)。
import mathclass VectorCompare:# 计算矢量大小def magnitude(self, concordance):total = 0for word,count in concordance.iteritems():total += count**2return math.sqrt(total)# 计算矢量之间cos值def relation(self, concordance1, concordance2):relevance = 0topvalue = 0for word,count in concordance1.iteritems():if concordance2.has_key(word):topvalue += count*concordance2[word]return topvalue/(self.magnitude(concordance1)*self.magnitude(concordance2))
想了解更多向量空间搜索引擎的原理可以参考这篇英文文献:
http://ondoc.logand.com/d/2697/pdf项目还有其他代码,有如何读取训练集什么的这里就不写了,像参考学习的可以用下面的码云链接去下载源代码和数据集即可。
https://gitee.com/mjTree/MyPython/tree/master/向量空间验证码识别还有就是说几句话,一个简单的向量空间思路就可以解决验证码识别问题,这个方法却是很不错。之所以说很不错是因为现在这个年代,做一些项目时动不动就是机器学习、深度学习、卷积神经网络什么的乱七八糟名词来解决问题。好是好但是觉得有点可悲,完全没有自己的思路和想法,是没法让人去记住这个项目。
如果你是外包公司利益至上那不说什么,但如果是一个学者就需要好好深思一下。对我那些读研究生的同学们说:不管未来两年还是三年的时间里,希望你们能在这个比较急躁的学习气氛中静下心来认认真真的专研学术知识。为自己也为中国计算机事业贡献一份力量 。
。
猎隼
猎隼
以上是关于向量空间验证码识别的主要内容,如果未能解决你的问题,请参考以下文章