教程 | 用Python识别图片验证码中的文字
Posted Python大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了教程 | 用Python识别图片验证码中的文字相关的知识,希望对你有一定的参考价值。
【导语】在今天这篇文章中,作者分享给大家一个有趣又干货满满的 Python 项目。通过这份教程,大家不仅又多了一个动手项目,还可以用 Python 破解图片验证码里的文字识别,十足的技术范儿。
文章目录
前期准备
(1)安装包,直接在终端上输入pip指令即可:
(2)新建项目
知识
(1)Pillow 中的 Image
(2)基于 Tesseract-OCR 的 pytesseract
小项目:破解图片验证码登陆
总结
前期准备
(1)安装包,直接在终端上输入pip指令即可:
# 发送浏览器请求pip3 install requests# 文字识别pip3 install pytesseract# 图片处理pip3 install Pillow
(2)新建项目
test_pillow :模块 Pillow 的基本使用测试
case_verification :实战案例,破解网站图片验证码验证
知识知识
(1)Pillow 中的 Image
# -*- coding: utf-8 -*-"""@author = 老表@date = 2019-08-16@个人公众号 : 简说Python"""# 注意:print_function的导入必须在Image之前,否则会报错from __future__ import print_functionfrom PIL import Image"""pillow 模块 中 Image 的基本使用"""# 1.打开图片im = Image.open("../wordsDistinguish/test1.jpg")print(im)# 2.查看图片文件内容print("图片文件格式:"+im.format)print("图片大小:"+str(im.size))print("图片模式:"+im.mode)# 3.显示当前图片对象im.show()# 4.修改图片大小,格式,保存size = (50, 50)im.thumbnail(size)im.save("1.jpg", "PNG")# 5.图片模式转化并保存,L 表示灰度 RGB 表示彩色im = im.convert("L")im.save("test1.jpg")
(2)基于 Tesseract-OCR 的 pytesseract
Python-tesseract是Google的Tesseract-OCR引擎的包装器。它作为独立的调用脚本也很有用,因为它可以读取Pillow和Leptonica成像库支持的所有图像类型,包括jpeg,png,gif,bmp,tiff等。此外,如果用作脚本,Python-tesseract将打印已识别的文本,而不是将其写入文件。
要在你的电脑上使用 pytesseract 模块,你还需要安装 Tesseract-OCR ,Mac上安装该工具我比较建议使用 Homebrew ,安装好后,直接在终端输入下面指令即可:
brew install tesseract
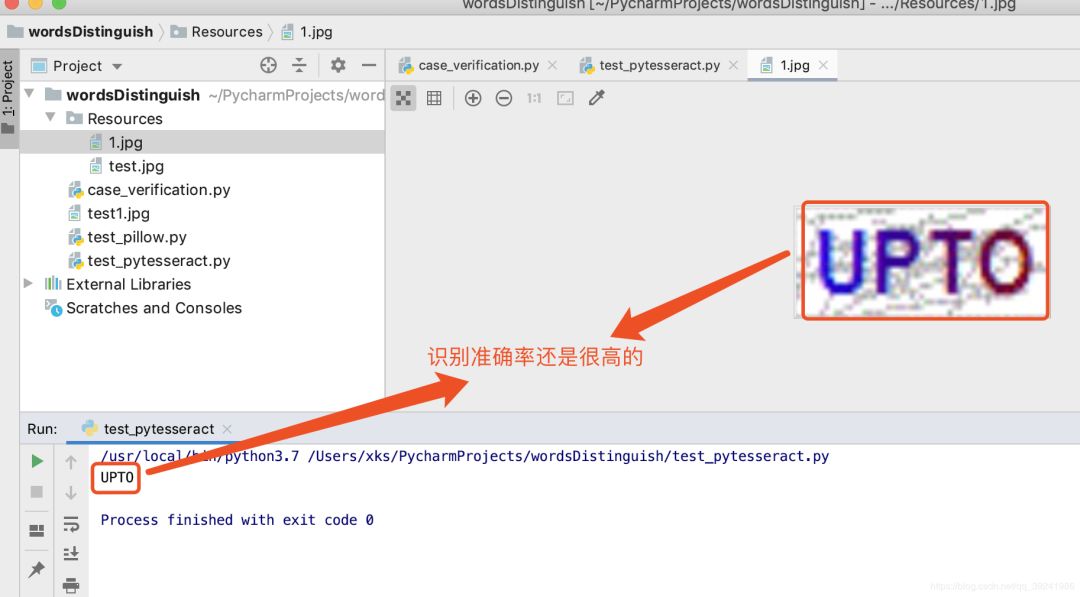
# -*- coding: utf-8 -*-"""@author = 老表@date = 2019-08-16@个人公众号 : 简说Python"""# 从 Pillow 中导入图片处理模块 Imagefrom PIL import Image# 导入基于 Tesseract 的文字识别模块 pytesseractimport pytesseract"""@pytesseract:https://github.com/madmaze/pytesseract"""# 打开图片im = Image.open("../wordsDistinguish/Resources/1.jpg")# 识别图片内容text = pytesseract.image_to_string(im)print(text)
小项目:破解图片验证码登陆
(1)准备过程
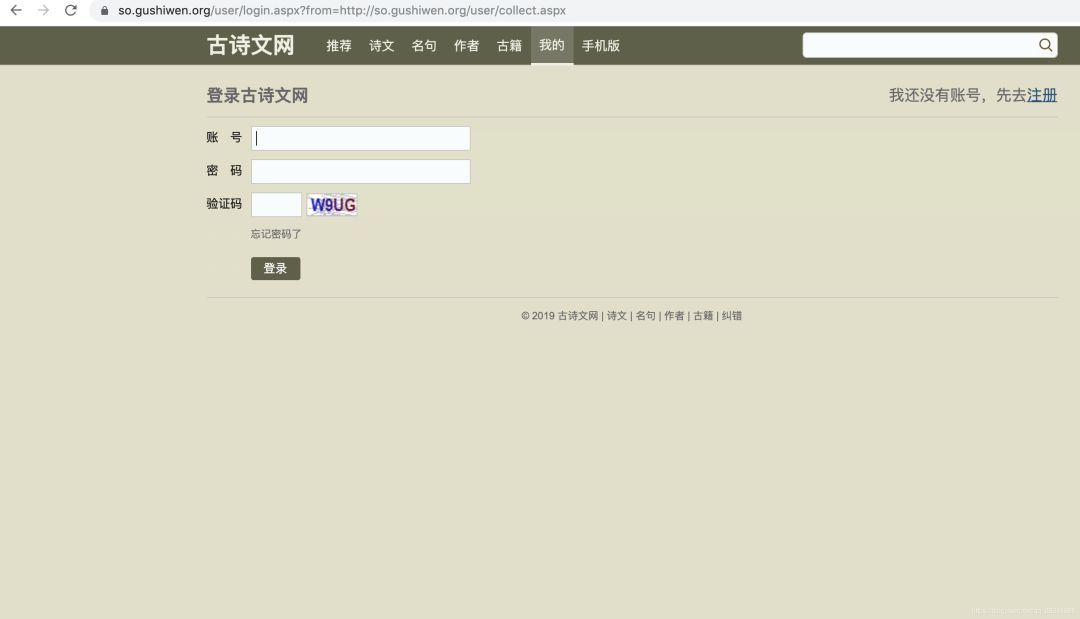
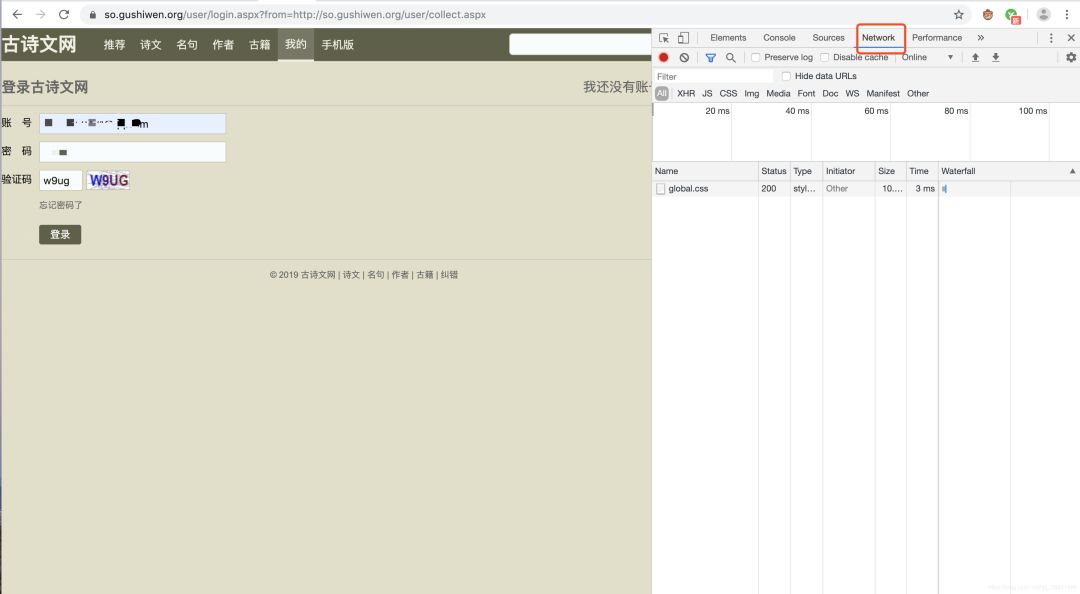
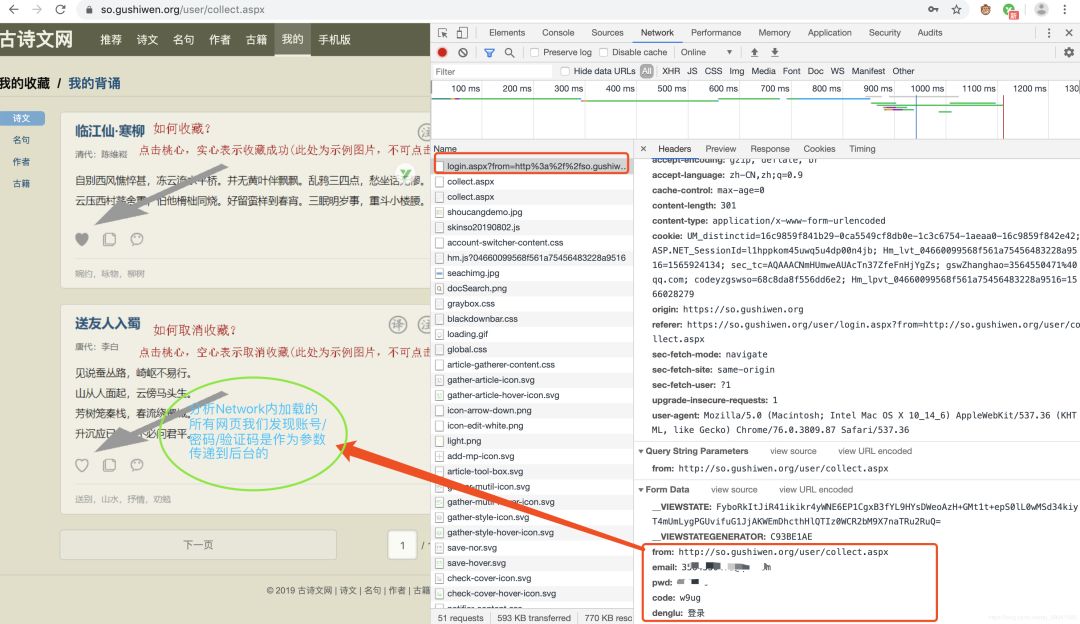
输入账号密码,和验证码,点击登录,注意Network内的变化。
(2)代码敲起来
a.验证码识别我们根据前面的知识知识里的,直接采用pytesseract模块。
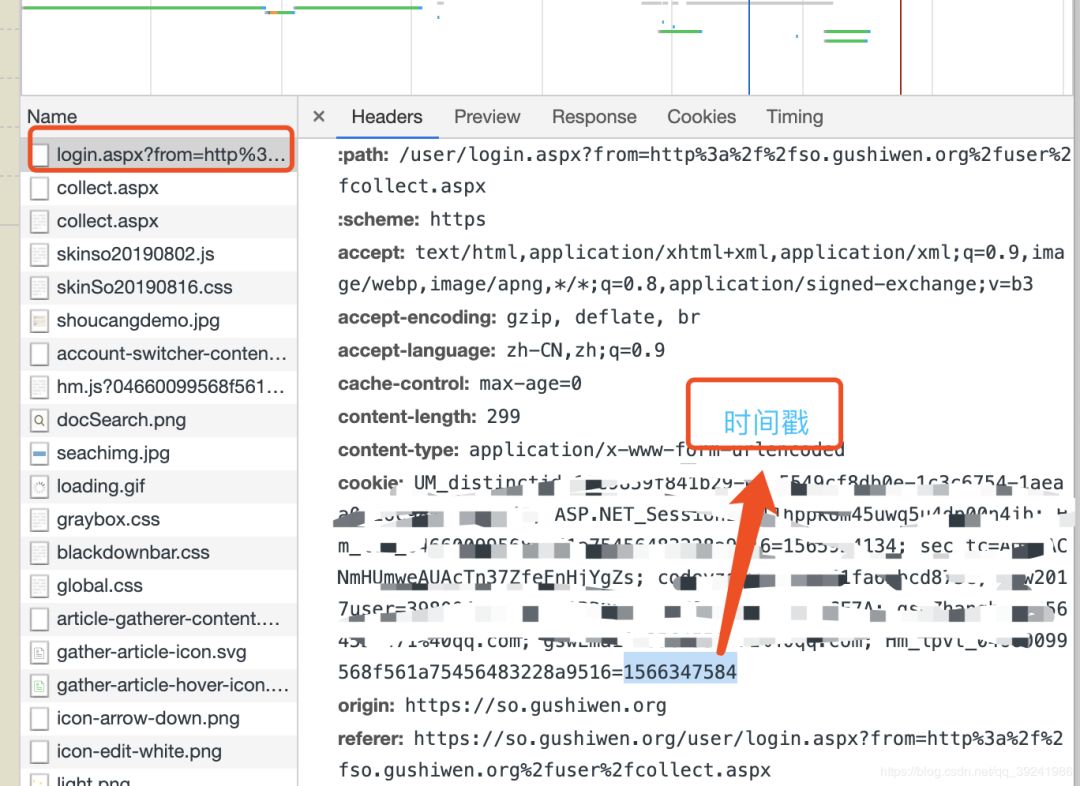
b.登录参数传递,利用requests库发送post请求即可,问题是如何把验证码和登录联系起来,通过前面分析我们知道验证码是在“https://so.gushiwen.org/RandCode.ashx”里生成的,而登录页面是“https://so.gushiwen.org/user/login.aspx”,分析发现,正常浏览器登录这两个网址的cookie是一致的,并且都带有时间戳,所以,只要在代码请求时保证两者的cookie一致即可,这里我们利用requests库的session方法可以实现。
# -*- coding: utf-8 -*-"""@author = 老表@date = 2019-08-16@个人公众号 : 简说Python"""# 从 Pillow 中导入图片处理模块 Imagefrom PIL import Image# 导入基于 Tesseract 的文字识别模块 pytesseractimport pytesseract# 导入发送网络请求的库 requestsimport requests# 导入正则库 reimport re"""模拟登录,破解字母数字图片验证码目标网站:https://so.gushiwen.org"""# 请求头headers = {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/76.0.3809.87 Safari/537.36"}# 通过requests 创建一个 session 会话,保持两次访问 cookie 值相同session = requests.session()# 下载识别验证码图片函数def get_verification():# 生成验证码图片urlurl = "https://so.gushiwen.org/RandCode.ashx"# 通过session发送get请求,获取验证码resp = session.get(url, headers=headers)# 将验证码保证到本地with open(r"../wordsDistinguish/Resources/test.jpg", 'wb') as f:f.write(resp.content)# 打开验证码图片文件im = Image.open(r"../wordsDistinguish/Resources/test.jpg")# 基本处理,灰度处理,提升识别准确率im = im.convert("L")# 保存处理后的图片im.save("test.jpg")# 利用pytesseract进行图片内容识别text = pytesseract.image_to_string(im)# 去除识别结果中的非数字/字母内容text = re.sub("\W", "", text)# 返回验证码内容return textdef do_login():i = 0 # 识别错误次数# 获取验证码captcha = get_verification()# 基本检验,验证码位数必须为四位while len(captcha) != 4:captcha = get_verification()i = i + 1 # i+=1print("第%d次识别错误" % i)print("开始登录,验证码为:"+captcha)# 传递的登录参数data = {"from": "http://so.gushiwen.org/user/collect.aspx","email": "你的注册邮箱","pwd": "你的登录密码","code": captcha,"denglu": "登录"}# 登录地址url = "https://so.gushiwen.org/user/login.aspx"# 利用 session 发送post请求response = session.post(url, headers=headers, data=data)# 打印登录后的状态码print(response.status_code)# 保存登录后的页面内容,进一步确认是否登录成功with open("gsww.html", encoding="utf-8", mode="w") as f:f.write(response.content.decode())# 开始程序if __name__ == "__main__":do_login()
(3)运行结果
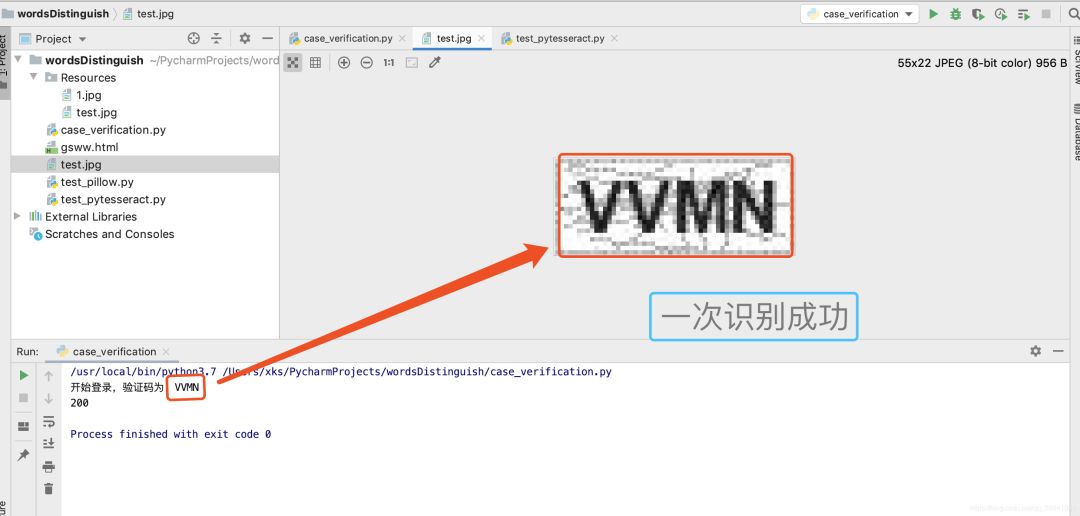
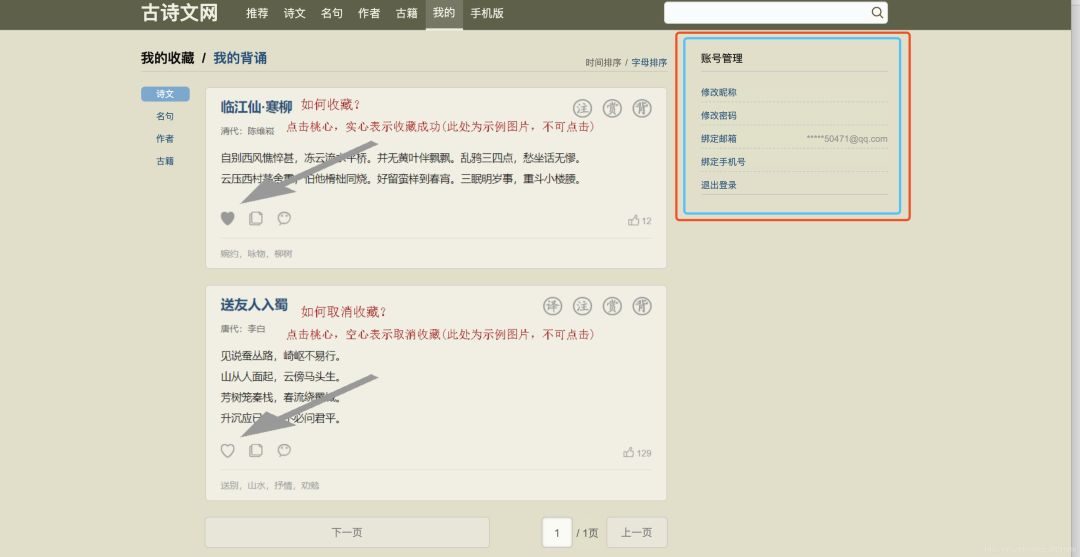
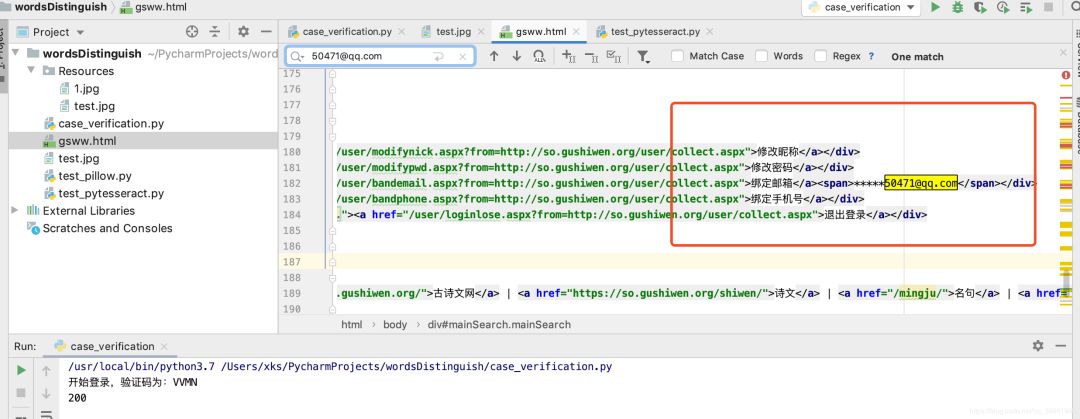
我们在浏览器观察登录后的页面发现,只有登录后的页面才有账号管理模块,其中有用户的唯一标识:绑定邮箱的后几位,我的是50471@qq.com。
总结
◆
福利时刻
◆
入群参与每周抽奖~
扫码添加小助手,回复:大会,加入福利群,参与抽奖送礼!

推荐阅读
以上是关于教程 | 用Python识别图片验证码中的文字的主要内容,如果未能解决你的问题,请参考以下文章