测码奔腾·鼎新基于tesseract识别验证码实践
Posted 北研测试部
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了测码奔腾·鼎新基于tesseract识别验证码实践相关的知识,希望对你有一定的参考价值。
文/付伟
验证码是一种防止程序自动化的一个措施,是一种反自动化技术,可以防止恶意破解密码、刷票、论坛灌水,有效防止黑客对网站、应用程序以暴力破解方式进行不断的身份验证。实际上验证码是很多网站通行的方式,利用比较简易的方式实现了这个功能,同时验证码的样子也会尽量千奇百怪,让机器不能够识别。
金融领域目前大力推广自动化测试,注册,登录,找回密码,支付等交易过程中必不可少的会有验证码环节,验证码的存在使得很自动化测试工作止步。针对这一现状,本文以识别某系统验证码为例,通过环境搭建、验证码图像分析和预处理、Tesseract-OCR识别识别验证码、Tesseract-OCR语言包训练、训练的语言包识别验证码等过程介绍字符验证码识别的方法,对后续Web自动化测试和OCR识别都有一定的参考价值。
关键字:自动化测试、Tesseract-OCR、验证码识别
验证码获取

大多数验证码识别研究为了方便计算识别率基于Captcha生成大量的验证码,本文针对某系统验证码进行验证,通过利用selenium截取页面,定位验证码元素的位置,利用PIL进行处理,获取其中验证码部分。
验证码获取基于python通过selenium+PIL实现。Selenium本身不是测试工具,是模拟浏览器操作的工具,支持全部主流的浏览器,同时支持主流的编程语言。 PIL是python的第三方图像处理库,具备强大的图形处理功能,包含格式转换、对点的处理图像过滤、大小转换、图像旋转等。
具体安装python、selenium、PIL不在此展开,需要提醒的是用于webdriver的浏览器驱动需要与电脑上的浏览器版本相对应,否则无法驱动浏览器执行操作。
实现思路是:
1)登录页面按F12检查元素,找到验证码图片的元素id
2)调用chromedriver,通过webdriver定位工具定位验证码在页面中的上下左右边界
3)通过Image截取网页中验证码验证码图片并保存
主要实现代码如下:
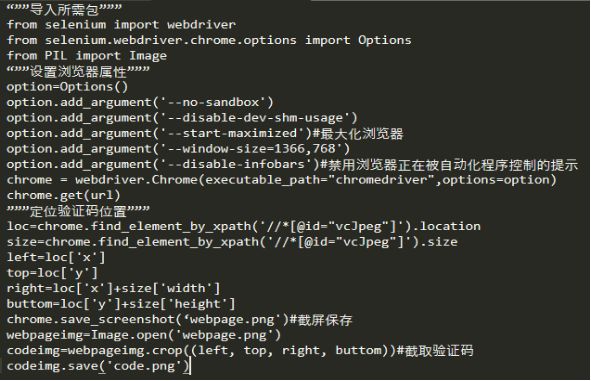
通过上述代码获得类似以下的验证码:

验证码图像分析与预处理
初步观察验证码为RGB图像,验证码内容由阿拉伯数字和小写字母组成,长度为4个字符,字符间偶有重叠,背景噪声与验证码字体明显不同,验证码字符为相近颜色。至此想到对验证码图片像素进行统计分析,思路如下:
1)遍历每个像素点的RGB值,统计每个颜色出现的次数;
2)为体现像素间的差距对RGB进行加权处理,查看加权后的颜色分布;
3)通过查看颜色分布设定去掉背景噪声的阈值;
4)将保留下的像素填充到与原图尺寸一样的白色背景的图片上;
5)去除边框,最后对所得图像灰度化,二值化。
实现代码如下:
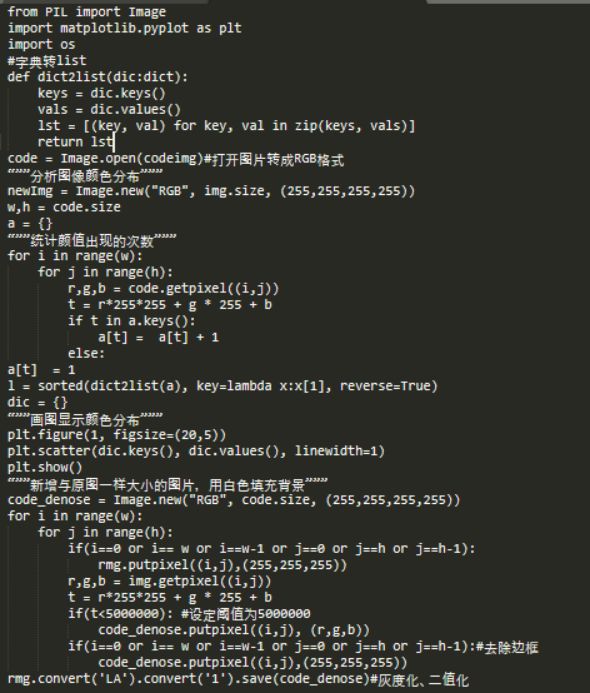
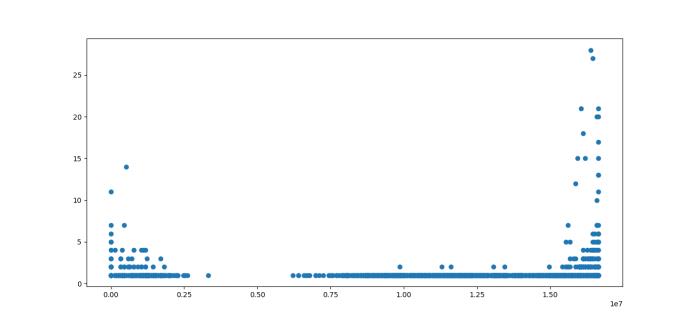
颜色分布如下,明显看出阈值为5000000
图像处理效果为:
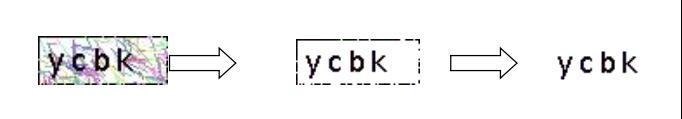
Tesseract-OCR识别识别验证码
OCR即光学字符识别,是指通过电子设备扫描纸上的打印的字符,然后翻译成计算机文字的过程。也就是说通过输入图片,经过识别引擎,去识别图片上的文字。Tesseract是一种适用于各种操作系统的光学字符识别引擎,本文通过该识别引擎对预处理后的验证码进行识别 。
Tesseract的识别步骤大致如下:
1)连通区域分析,检测出字符区域区域以及子轮廓。在此阶段轮廓线集成为块区域。
2)由字符轮廓和块区域得出文本行,以及通过空格识别出单词。固定字宽文本通过字符单元分割出单个字符,对比例文本通过一定的间隔和模糊间隔来分割。
3)依次对每个单词进行分析,采用自适应分类器,分类器有学习能力,先分析且满足条件的单词也作为训练样本,所以后面的字符识别更准确。
本文首先对单个验证码图片进行识别,Windows系统进入命令行模式,进入验证码图片所在的目录,运行tesseract name.png textname(其中name.png要被识别的验证码图片文件名,textname为识别后的验证码字符存放的文件名,默认格式为TXT文件)。随机选取两个,识别结果如下:

结果表明验证码中字符间有重叠的情况识别有误,为了统计识别率,手工对1052张验证码进行标记,此部分工作需手工完成,需消耗较大人工成本。下载GitHub上开发者贡献的语言包,执行以下语句:
pytesseract.image_to_string(code.png,lang='eng',config="-psm7")进行识别,识别结果如下:
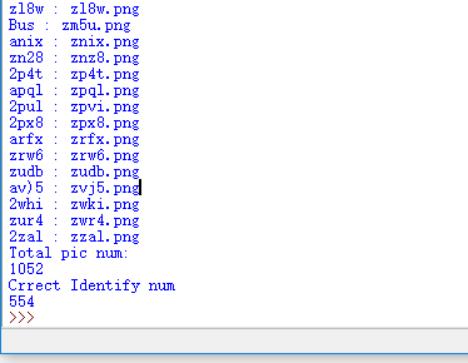
识别正确率为554/1052=52.7%。
Tesseract-OCR语言包训练
根据上述统计结果,识别正确率不高,因此需要针对验证码图片样本进行训练,提高识别率,通过训练,也可以形成自己的语言库,进而应用于后续自动化测试。
本文采用jTessBoxEditor工具训练验证码语言包,训练前需要安装好该软件,该软件为免安装版,解压即可使用。需要特别说明,这个工具是基于java虚拟机运行的,需要安装一个java虚拟机。本文选取100张经过处理的验证码图片进行训练,具体语言包训练过程及图示如下:
1)进入解压后的jTessBoxEditor文件夹,双击里边的“jTessBoxEditor.jar”,打开该工具;
2)点击tools-Merge TiFF然后选中经过处理的验证码图片,命名为num.font.exp0.tif保存;
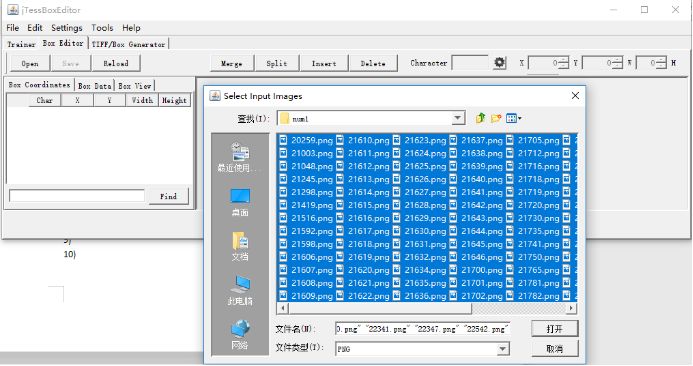
按住shift选中图片
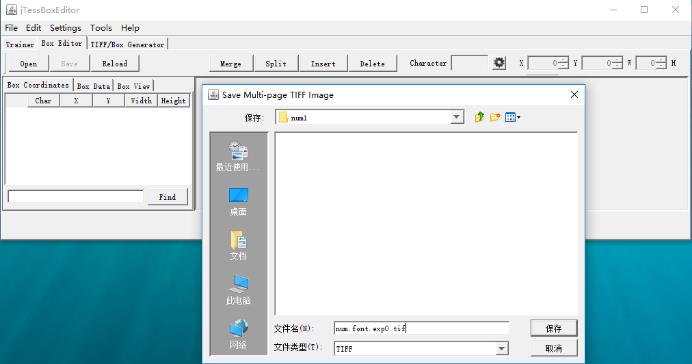
保存合并后的tif文件
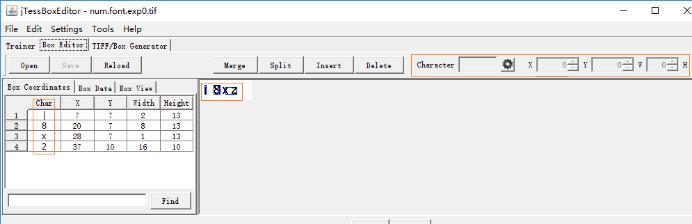
3)合并生成后,运行命令行窗口,通过cd命令进入tif文件所在的文件夹,运行以下命令生成box文件;
tesseract num.font.exp0.tif num.font.exp0 -psm 7 batch.nochop makebox
4)在jTessboxedit中Box Editor选项卡中点击open按钮打开上一步生成的tif文件,若验证码图片中字符的位置和大小定位不准就调整X、Y、W、H的值,识别出来的字符不对就修改字符,对所有验证码图片调整完成后点击save保存;
5)生成训练的库文件,进入到tif和box所在的文件夹,依次执行以下命令;
tesseract.exe num.font.exp0.tif num.font.exp0 -psm 7 nobatch box.train #使用tesseract生成.tr训练文件
unicharset_extractor.exe num.font.exp0.box #生成字符集文件
echo font 0 0 0 0 0 > font_properties.txt #生成font_properties文件
mftraining -F font_properties.txt -U unicharset -O num.unicharset num.font.exp0.tr #生成聚字符特征文件
cntraining.exe num.font.exp0.tr #生成字符正常化特征文件
rename normproto num.normproto #文件重命名
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
combine_tessdata.exe num. #合并训练文件,生成zwp.traineddata文件
至此系统验证码语言包已训练完毕。将生成的“num.traineddata”语言包文件复制到Tesseract-OCR 安装目录下的tessdata文件夹中,就可以使用训练生成的语言包进行验证码识别了。
训练的语言包识别验证码
执行以下语句对上述1052张验证码图片进行识别,识别效果如下,pytesseract.image_to_string(code.png,lang='num',config="-psm7"):
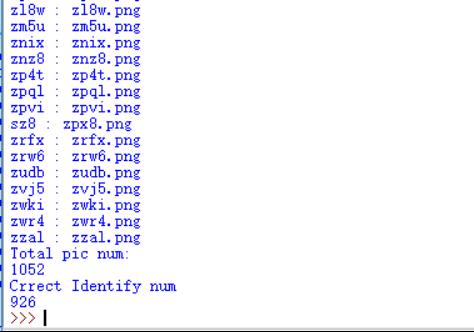
识别正确率为926/1052=88%
总结与展望
通过验证码识别的实践,积累了相关的技术,也对相关工作有一定的借鉴作用:
1)通过对比两次识别的正确率可以看出,针对性的训练特定情况下的样本形成特定的语言库,能够明显提高识别率,训练100张验证码图片正确率能够达到88%,可以推断随着样本数量增加,正确率会继续提高。
2)本文通过从验证码图像分析到训练语言包,以某系统验证码为例,比较完整的介绍了字符验证码识别过程,对其他系统的验证码识别也有一定的参考价值,对后续的自动化测试开展做了相关的技术准备。
3)Tesseract-OCR支持多种语言,验证码识别只是它的一部分应用场景,其他的图片转换成计算机文字的相关领域研究、实践也可借鉴本文方法。
参考:
https://blog.csdn.net/zbj18314469395/article/details/79954153
https://blog.csdn.net/kangshuaibing/article/details/84333611
https://blog.csdn.net/chouzhou9701/article/details/82587833
 顾问:侯晓靓 李阳 牛晔
顾问:侯晓靓 李阳 牛晔
总编辑:张勇
编辑:顾雪翠
以上是关于测码奔腾·鼎新基于tesseract识别验证码实践的主要内容,如果未能解决你的问题,请参考以下文章
JAVA验证码识别:基于jTessBoxEditorFX和Tesseract-OCR训练样本