排序--堆排序分析与实现
Posted 西邮Linux兴趣小组
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了排序--堆排序分析与实现相关的知识,希望对你有一定的参考价值。
何为堆
一个数组序列我们可以将其用完全二叉树或近似完全二叉树(不是满二叉树的完全二叉树)表示出来,当数组下标为i时,它的父节点为(i-1)/2,左孩子为(2i+1),右孩子为(2i+2),这种对应关系说明数组下标为0的地方也要存储数据。(关于完全二叉树和满二叉树我在这里不做介绍)
堆是在完全二叉树的基础上递归定义的,堆分为大顶堆和小顶堆。
大顶堆:根节点的数值大于孩子节点,完全二叉树的左右子树同时满足这个条件。
小顶堆:根节点的数值小于孩子节点,完全二叉树的左右子树同时满足这个条件。
从这种数据结构中我们可以发现:大顶堆的根节点也就是数组的第一个元素必定是最大值,而小顶堆必定是最小值,看到这,我想大家已经大概能感觉的到堆这种数据结构为什么可以用来排序了。
再来看个大顶堆和小顶堆的图解吧:
堆排序的过程
想写出堆排序的代码,首先我们一定要清楚堆排序的过程,根据堆这种数据结构的特性,我总结了一下堆排序的过程:
首先我们需要将一个数组初始化为堆;
在初始化堆的过程中我们必定要移动数组中元素的位置;
初始化完成之后,如果我们建立的是大顶堆,那么数组中的第一个元素就是数组的最大值,小顶堆就是最小值;
然后我们将最大值(最小值)和堆中的最后一个叶子节点(数组中的最后一个元素)进行交换,是不是类似于选择排序。可以预测到,如果是大顶堆,那么我们将会进行升序排序,如果是小顶堆,我们将会进行降序排序;
在进行了上一个步骤之后我们需要重新初始化堆,然后重复以上步骤,直到循环结束。
在上面的排序过程中,有很多细节没有说,只是在脑中大致建立起一个堆排序的过程,下面我们仔细研究一下其中的细节。

1.堆的初始化

堆的初始化实际上就是数组元素的移动与交换,只不过这种交换是发生在孩子节点与父节点之间。假设我们要建立的是大顶堆,我们只要保证每棵左右子树都是堆并且都是大顶堆那么最后整棵完全二叉树必然是大顶堆。根据完全二叉树的结构我们可以得到,假设我们的数组有n个元素,那么对应的完全二叉树的叶子节点就有(n+1)/2个,(子树)根节点的下标(0单元进行存储)是从(n/2)-1开始。叶子节点已经有序,可以单独看做已经初始化好的子堆,也就说我们只要从节点(n/2)-1处开始,分别计算出当前节点的左右孩子,先拿出值最大的孩子,然后将此孩子与父节点进行比较,如果孩子节点小于父节点,说明此子树已经是一子堆,直接考虑前一个非叶子节点,如果此孩子大于父节点,则需要将孩子节点与父节点互换后再考虑后面的结点,直至以这个节点为根的子树是一个堆!就相当于将这个比较小的节点不断下沉的画面。然后再考虑前一个非叶子节点。
我再给大家一张图,很直观:
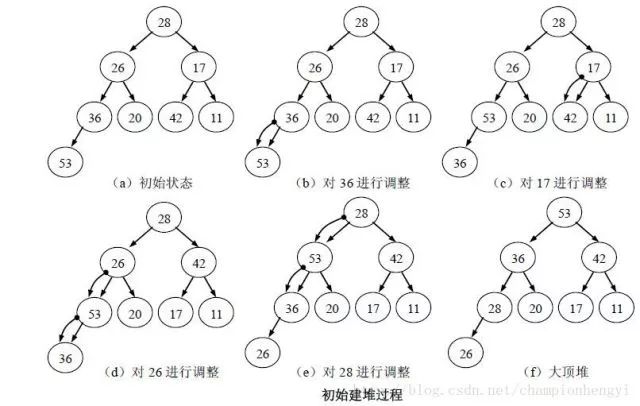
如图,我们不对叶子节点进行考虑,直接从36处进行调整,而我上面着重标注的那段话,就是图d和图e。
2.根节点的删除
与其叫做根节点的删除,不如说是根节点与n-i (i=1,2,3… …)处节点的互换,这样我们就相当于每次将当前数组的最大值放到数组的最后面,也就是实现了升序。可以看到,每建立一次堆,下次重新初始化堆的时候节点数量都会少一,那么当整个数组有序的时候也就是当只有一个节点进行堆的初始化的时候。
代码实现



小顶堆的实现代码和大顶堆没有区别,故不在列出。
效率分析
时间复杂度:
堆排序的时间代价主要花费在建立初始堆和调整为新堆时所反复进行的“筛选”上,由代码可知,我们总共建立了n-1次堆,建立新堆时总共进行的比较次数最多为{2[log2(n-1)+log2(n-2)+log2(n-3)… … +log2]} < 2n[(log2(n)],所以堆排序的时间复杂度为O(nlog2(n))。
空间复杂度:
只需要一个辅助空间,为O(1)。
最后,堆排是一种不稳定的排序。
https://blog.csdn.net/championhengyi/article/details/76187386
(更多详细内容,点击左下角【阅读原文】)
以上是关于排序--堆排序分析与实现的主要内容,如果未能解决你的问题,请参考以下文章