记一次堆排序使用的真实案例
Posted BaristasCafe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次堆排序使用的真实案例相关的知识,希望对你有一定的参考价值。
前几天有个同学在同学群里问:我遇到一个难题,有两张结构一样数据量都是10万的表在两个不同的数据库中,现在要将这两个表的数据查询出来并且按照时间做倒序排序,然后分页显示在一个列表上。本来用数据库的排序很快就搞定,但是难就难在现在是两个库,无法用数据库提供的排序方法。有人知道怎么做吗?(ps:原话可能不是这样的,但是为了将问题叙述清楚所以总结了一下)
作为一个乐于助人的我,同学遇到问题当然要积极帮(zhuang)忙(X)啦(手动滑稽),下面为了容易理解我就用对话的形式来展开。
我:同学,你可以把思路转一下。
同学:怎么转?
我:你想想嘛,其实分页就是求TOPK嘛。按时间倒序显示第一页,就是取时间最大的10条(加入一页有10条),第二页就是去掉第一页的TOP10。
同学:然后呢?
我:然后按照求TOPK的套路去求救可以了,使用堆排序遍历两个库的数据构建最大堆,堆的大小正好是每一页的大小,即堆的数据就是这一页的数据。
同学:堆排序?那是什么鬼?
我:堆排序你不知道,我画个图你就明白了。
我们来看一下如何用下面这个数组构建一个最大二叉堆:
2 |
1 |
5 |
4 |
3 |
7 |
9 |
二叉堆本质上就是一种完全二叉树,我们先用这个数组来构建一棵完全二叉树(PS:二叉堆的存储形式一般都是用数组存储,这里转换成树的形式是为了方便讲解):
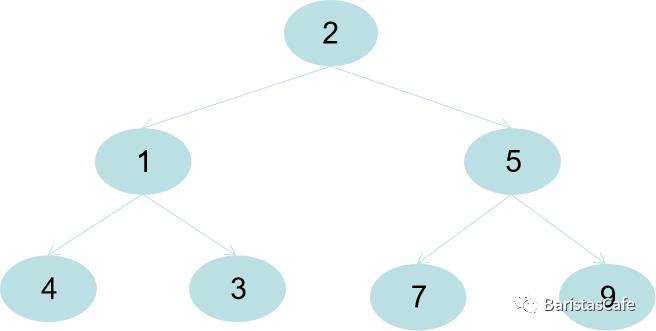
构建好二叉树之后就会用这棵二叉树构建二叉堆,怎么构建呢?首先我们从最后一个非叶子节点开始,也就5这个节点开始,由于5小于左右节点中最大的一个节点9,所以5节点下沉,结果如图所示(PS:红色字体的节点为这次操作中变换的部分):
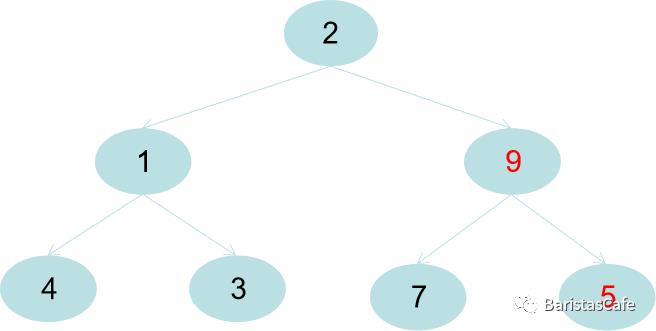
那么现在就轮到1这个节点了,由于1比它的左右节点中最大的节点4要小,所以下沉:
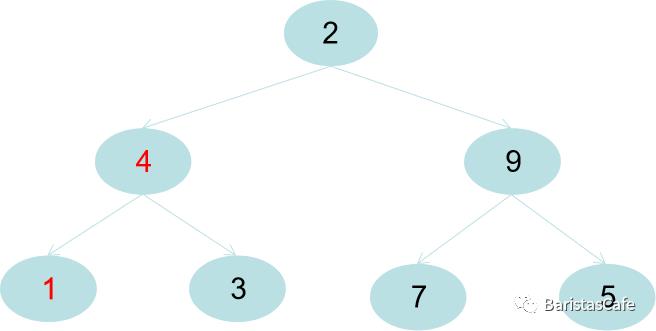
调整完4这个节点后就轮到根节点了,根节点2比左右节点中最大的节点9要小所以下沉:
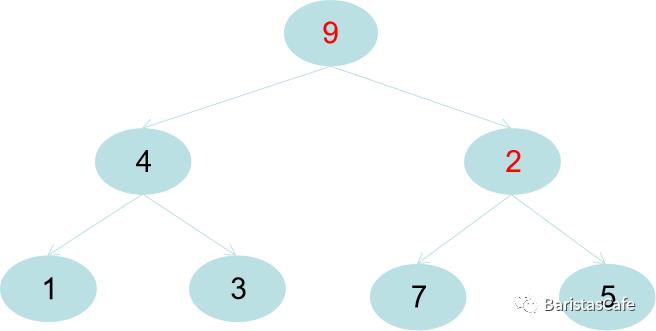
节点2下沉了之后再继续比较,发现它比它的左右节点中最大的节点7还是小了,所以继续下沉:
好了,就这样最大二叉堆就构建完成了。
同学:二叉堆是理解了,但是这有什么用呢?
我:当然有用啦,只要设置了堆的大小就能求出数组中最大的几个数。
同学:排序算法不是有很多种吗,为什么要用堆排序而不用插入排序呢?
我:这里可以解析一下,堆排序的空间复杂度是O(1)的,而平均时间复杂度和最坏情况下的时间复杂度都是O(nlogn)。而插入排序的的平均时间复杂度是O(nlogn),最坏的情况下是O(n^2)。所以说堆排序是一种比较稳定的算法。(感兴趣的同学可以自己推导一下这两个算法的时间复杂度)。
同学:堆排序我是明白了,可是要怎么运用呢?
我:有了堆排序就好办了,假设你每一页的数据量是100,那么你就可以设置你的堆的大小为100。然后检索两个数据库的所有数据的日期字段和唯一字段,根据这两个字段去构建最大堆,得到的第一个最大堆就是第一页的唯一字段的所有数据,第二个最大堆就是第二页的唯一字段的所有数据……以此类推,最后把这些堆缓存到HashMap中,当要查第十页的时候就从HashMap中找到第十页的唯一字段,然后用这个字段的值作为条件分别去两个库中查询,最后将从两个库中查询出来的100条记录再做一次排序即可。
同学:那每次访问都要构建一次二叉堆会不会很慢,当数据量比较大的时候会不会把内存耗尽?
我:如果你的数据变化不大的话可以缓存起来,那么就不用每次请求都构建二叉堆了。至于内存问题你可以像redis一样持久化到硬盘,或者采用一些淘汰策略,像LRU算法一样,把最少访问的页面数据淘汰掉,还有比LRU更优一点的LRU-K算法,至于使用哪种算法就要取决于你的业务特点了。
同学:好的,谢谢了,我再研究研究。
以上是关于记一次堆排序使用的真实案例的主要内容,如果未能解决你的问题,请参考以下文章