堆堆排序与优先队列
Posted 数据结构与算法
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了堆堆排序与优先队列相关的知识,希望对你有一定的参考价值。
作者丨皮蛋solo粥
https://www.jianshu.com/p/ed5f027e4f07
堆的一个非常典型的应用就是优先队列,在说堆之前我们先说下,什么是优先队列?
普通的队列我们知道,就是由入队时间的顺序来决定出队的顺序,先进先出后进后出。这种规则满足我们生活中大多数场景,比如超市结账地铁进站等等,而优先队列则是出队的顺序和入队的顺序无关,而和优先级有关,比如医院排队就诊,有120送来的急诊患者肯定优先级最高要第一时间就诊。
而在计算机中优先队列则被大量的使用,系统要同时执行多个任务,在执行时是将CPU的执行周期划成了时间片,在每个时间片里只能执行一个任务,执行哪一个任务就是取决于任务的优先级,系统会动态的选择当前优先级最高的任务来执行。所以此时就用到了优先队列,将所有需要执行的任务入列,由优先队列来选择优先级最高的任务。
可能此时有人会问,如果将所有任务按优先级进行一次排序不就可以吗?可现实是,当我们执行完一个任务之后,此时可能会再来好几个不同优先级的任务,而且刚刚拍好序的任务的优先级可能也会改变(原本很紧急,突然变得不紧急了),如果每次选择任务前都对任务进行一次排序,这样的耗时是很巨大的。
此时我们知道了优先队列的必要性,那么实现优先队列为什么要用堆呢?我们看下图
如果我们用普通的数组,那么入队时很简单直接随便放入数组,只需要O(1)的时间,然而在出队时要挑选最大的那个优先级,则需要O(n)的时间。同样如果是有序的数组,入队时需要维护这个数组的有序性,找到此优先级合适的位置,需要O(n)的时间,出队就很简单只需要拿出数组第一个就好了。而如果使用堆的话,则可以非常好的平衡入队与出队的时间复杂度。使用堆可以将入队与出队的时间复杂度都变成lg(n)级别,虽然使用堆在入队上是慢于普通数组,在出队上是慢于有序数组的,可是平均来讲,使用堆来实现优先队列的时间复杂度大大低于我们使用数组来实现。
 堆的定义
堆的定义
堆是一种特殊的数据结构,最为经典的实现是二叉堆,它是一棵完全二叉树。二叉树长这样
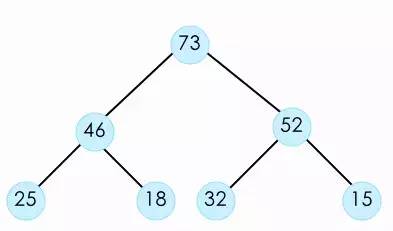
这个二叉树特点就是树里的任何一个节点都不大于它的父节点,并且他是一个完全二叉树。所谓完全二叉树就是,除了最后一层以外,其他的层的节点必须是最大值。也就是说这一层没有装满,你就不能开下一层。而且最后一层剩余的节点,必须集中在左侧(如下图)。这样堆我们也称为最大堆,因为树顶的那个元素总是最大的那个值。反之同样也有最小堆。
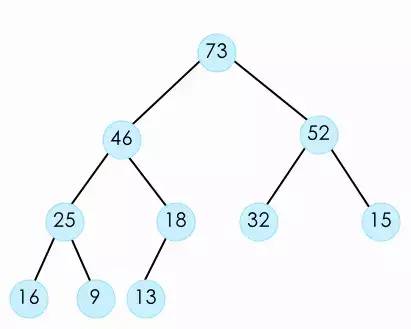
堆的实现
既然堆是一个树形结构,我们可以像其他普通的树形结构一样,创建节点的对象,这个对象有两个指针,指向它的左孩子和右孩子。但对于堆而言我们可以用数组来存储一个堆。我可以用编号来标记每一个节点。
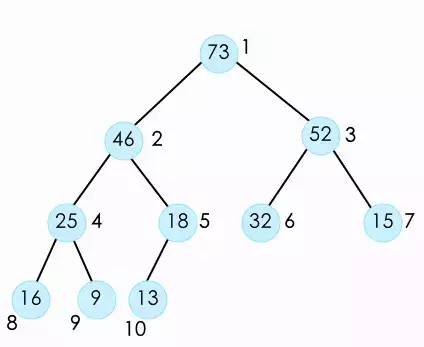
我们可以看出,节点的序号乘以2就是它左孩子的节点,节点序号乘以2加1就是右孩子的节点。所以我们可以归纳出,在第一个节点用1来标记的情况下,节点 i 它的父节点为 i/2,左孩子节点为i*2,右孩子i*2+1。
Ps:从1开始标记是比较常用的实现方式,你也可以从0开始,相应的表达式也有改变。节点 i 的父节点为 (i-1)/2 , 左孩子为2*i+1 、右孩子2*i+2。
上浮操作 shift up
当我们需要向一个最大堆添加一条新的数据时,此时我们的堆变成了这样。
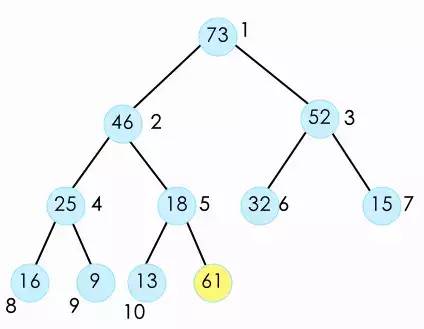
此时,由于新数据的加入已经不符合最大堆的定义了。所以我们需要对新加入的数据进行shift up操作,将它放到它应该在的位置。shift up操作时我们将新加入的数据与它的父节点进行比较。如果比它的父节点大,则交换二者。
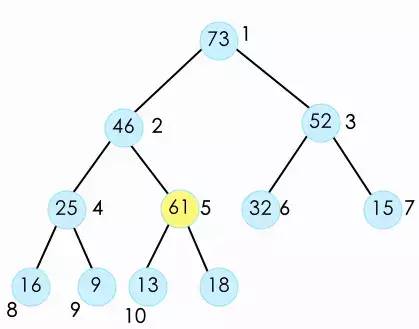
并且不断的重复这个操作,将它与父节点比较,直到它不大于父节点,或者它没有父节点(到顶了)。
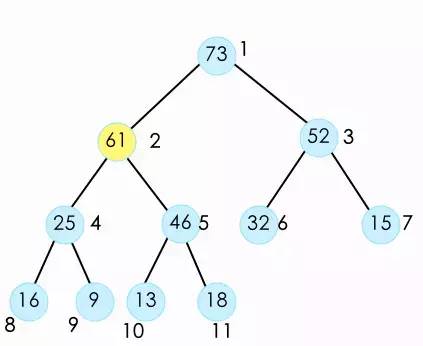
此时我们就完成了 对新加入元素的shift up操作。
伪代码如下
void shiftUp(int i) {
while(i>1 && array[i/2]<array[i]) {
swap(array[i/2],array[i]);
i /=2;
}
}
下沉操作 shift down
当我们从堆中(也就是优先队列中)取出一个元素时。我们是将堆顶的元素弹出。(只能从堆顶取出)
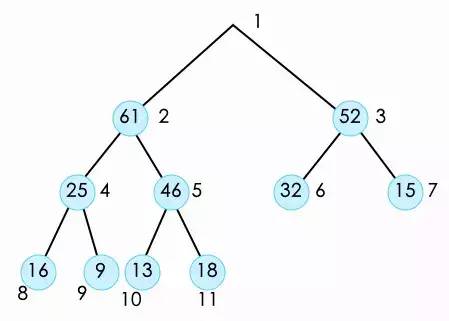
此时这个堆没有顶了,那么该怎么办呢?我们只需要把这个堆最后一个元素放到堆顶就可以了。
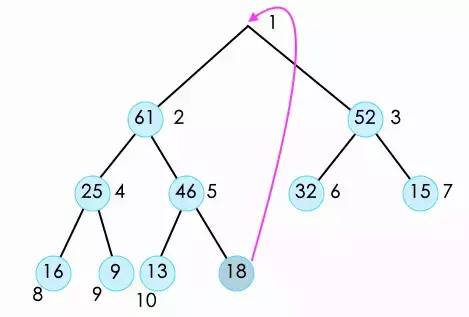
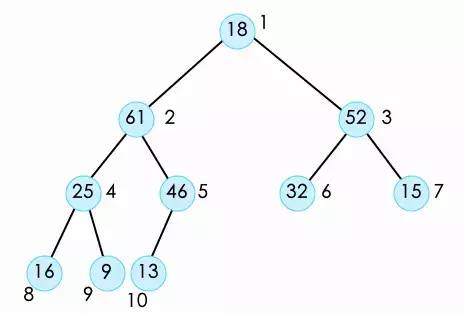
此时这个堆已经不符合最大堆的性质。为了保持这个性质,我们需要将堆顶的元素调整到它应该在的位置。也就是对它进行shift Down操作。在shift down时,因为它有左右孩子两个节点,所以我们需要将左右两个孩子节点进行比较,在得到较大的节点之后,再与它进行比较,如果它的子节点大,则将二者交换。并且不断的重复这样的操作,直到它没有叶子节点或者大于叶子节点停止。
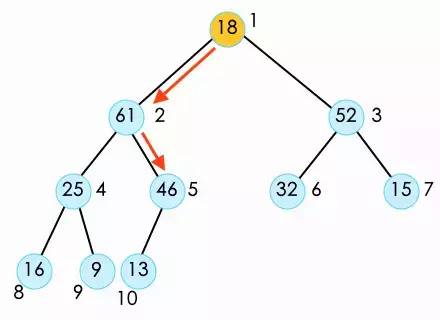
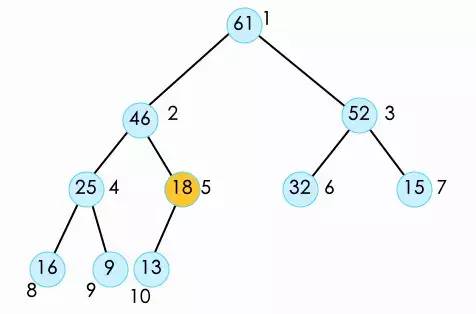
此时我们就完成了弹出一个元素之后的shift down操作。
伪代码如下
void shiftDown(int i) {
while(2*i <= array.count){
int j = 2*i;//需要交换的目标索引,初始为左孩子的
if(j+1 <= array.count && array[j+1]>array[j]) {//需要判断此节点有没有右孩子
j += 1;
}
if(array[i] >= array[j]) {//此时子节点没有大于父节点直接跳出
break;
}
swap(array[i] , array[j]);
i = j;
}
}
堆排序
堆排序(heap sort)是利用堆这种数据结构,来进行排序的一种算法。
首先将一个数组抽象成一个堆。这个过程,我们称之为heapify。
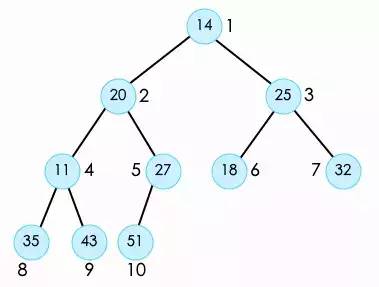
之后我们找到这个堆中第一个非叶子节点,这个节点的位置始终是数组的数量除以2,也就是索引5位置的27,从这个节点开始,对每一个非叶子的节点,,进行shift down操作。
27比它的子节点51要小,所以交换二者。
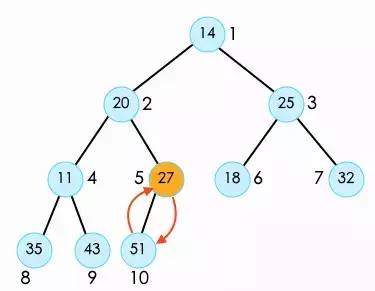
之后对索引4位置的11,以及索引3位置的25,继续进行shift down。
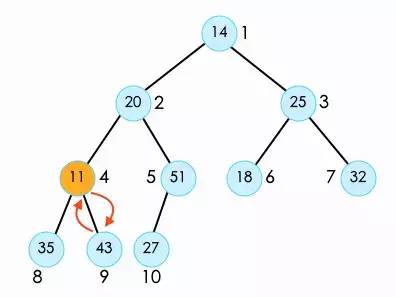
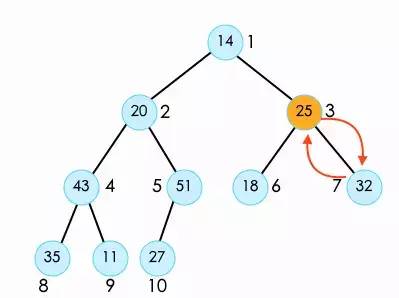
接下来我们看索引2位置的20。首先呢,我们需要将20与它两个子节点中较大的51交换。
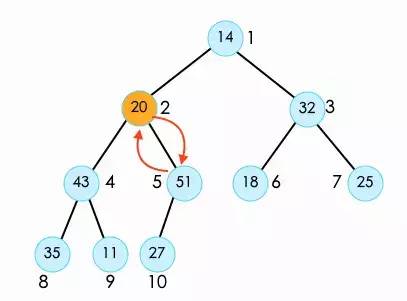
此时,还没有完,shift down操作是直到它没有叶子节点或者大于叶子节点时才停止。
所以我们需要继续将20与它的子节点27进行比较。
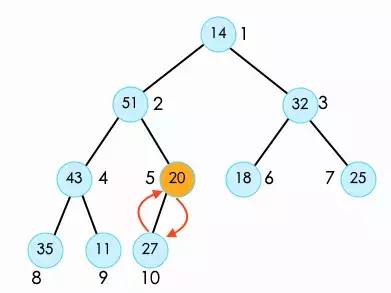
索引2才算操作完成了。
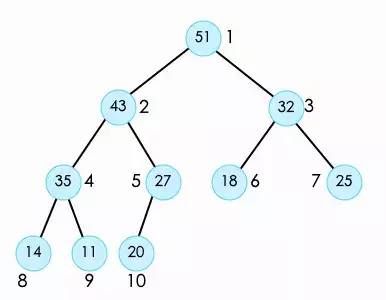
最后继续对索引1位置的14,以此类推进行shiftdown。整个堆就操作完成。使用的时候每次取出堆顶的元素,整个数组就是排序完成的了。
推荐↓↓↓
长
按
关
注
以上是关于堆堆排序与优先队列的主要内容,如果未能解决你的问题,请参考以下文章