那些经典算法:堆排序应用
Posted 尧字节
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了那些经典算法:堆排序应用相关的知识,希望对你有一定的参考价值。
前言
上篇谈到堆的基础知识,本篇文章讨论的是关于堆排序的应用。首先我们应该从堆的特点出发,大顶堆中堆顶是最大的元素,小顶堆中的堆顶是最小元素。
Top K问题
所以,从堆的定义来说,很容易想到堆顶元素是TOP 1,那么如何求经典的TOP K问题那,
Top K中的K的数量是有限的,那么我们想到可以建立一个固定大小的堆,比如只保存K个数量的堆。如果求最大的Top K 元素,是建立大顶堆,还是小顶堆,如果用大顶堆,堆顶是最大的元素,我们新加入的元素必须和所有的堆中元素做比对,显然不够划算;如果用小顶堆,那堆顶元素是最小的元素,新加入的元素只要和堆顶元素做对比,如果比堆顶元素大,就可以把堆顶的元素删除,将新加入的元素加入到堆中,是不是很奇妙,每次求TopK的问题的时候,只需要直接返回堆中所有元素即可,效率非常高,每次堆化的算法复杂度为O(logK),那么N个元素堆化的时间为O(nlogK),如果不用堆,每次新增元素都要重新排序,再取前面N个。
定时器应用
我们在编写网络处理代码中,经常要处理的是网络的连接超时问题,如果客户端在一定时间内没有发送任何消息,这时候我们需要把这个客户端的连接断开,不然连接越来越多,影响服务器处理的性能。
如何实现这种定时器的功能那,有个办法就是单独新建一个线程,每秒去轮询一次看看是否有超时的连接,如果有连接超时则断开,这里面有个问题就是如果超时时间设置为5分钟,所有连接钟,最快也要4分钟超时,那么这个线程4分钟的时间的轮询判断都是浪费CPU的。
这里面可以同样利用堆的堆顶元素为最大元素或最小元素的特性,在这里我们可以假设有三个连接,连接的起始时间如下图,连接的超时时间为5分钟。
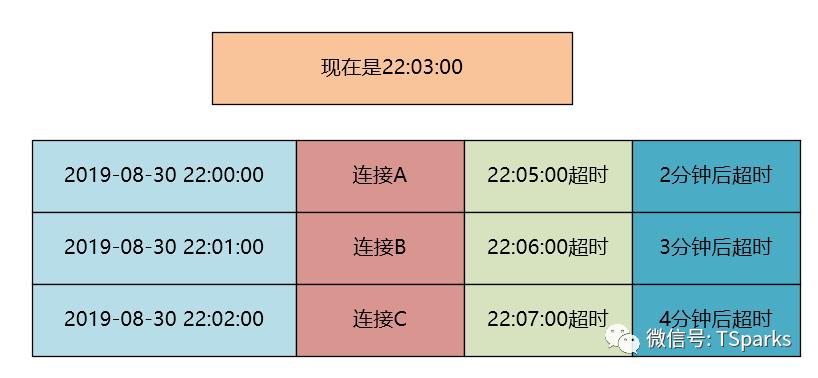
现在时间是22:03:00秒,那么三个连接依次为2分钟后超时,3分钟后超时,4分钟后超时。
我们这时候以超时时间后可以建立了一个小顶堆,那么堆顶元素为2分钟,清理连接的线程的休眠的时间就可以设置为2分钟,2分钟后取堆顶元素,执行连接关闭操作即可。
这也是我觉得很妙的办法。
求中位数和99%的响应时间
如果一个有序的数组为奇数个,中间的数据就是中位数;如果数组的个数为偶数个,那么n/2或(n+1)/2其中的,那么可以取n/2作为中位数。
如果数组是静态的,这种情况下,排序直接取中间的数字就可以了,但是如果数据是不断变化的,那么每次添加一个元素都需要排序,效率很低。
同样可以用两个堆来解决,如果n为偶数,那么前n/2数据存储在大顶堆中,n/2存储在小顶堆中,那么大顶堆的堆顶元素为要找的中位数,如果n为奇数,可以将前n/2+1个数据存储在大顶堆中,后n/2存储在小顶堆中。
如果新的数据来了之后,如何处理,简单来说就是将数据与大顶堆中的堆顶元素比较,如果小于等于大顶堆中的元素,就插入到大顶堆中;如果比大顶堆的堆顶大,那就插入到小顶堆中。如果插入数据后不满足要求两个堆的数量为n/2和n/2 或n/2 和n+1/2 的要求,需要调整两个堆的大小,从大顶堆中删除堆顶元素,或小顶堆中删除堆顶元素,移动到另外一个堆中即可。
99%的响应时间先要介绍下,如果一个接口的有100个访问请求,分别耗时1ms,2ms,3ms…100ms,那么按照访问时间从小到大排列,排在第99位的访问时间,就是99%的访问时间,我们维护两个堆,大顶堆的元素个数为n99%,小顶堆的元素个数为n10%,那么大顶堆中的堆顶元素即是所求的99%的响应时间,这和中位数的应用是一样的,只是中位数中的应用更特殊一点。
堆的应用还有优先级队列,在这里面就不赘述了。
祝大家一切都好!
鸣谢昨天给我打赏的朋友,谢谢您,给我以鼓励!
——明翼 2019年8月30日 23:24分 于成都
以上是关于那些经典算法:堆排序应用的主要内容,如果未能解决你的问题,请参考以下文章