分析与总结InnoDB多版本并发控制机制-MVCC底层实现
Posted 一叶而不知秋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分析与总结InnoDB多版本并发控制机制-MVCC底层实现相关的知识,希望对你有一定的参考价值。

一叶而不知秋
向管中窥豹寻知外,坐井观天又出来。

什么是MVCC?
MVCC是Multi-Version Concurrency Control(多版本并发控制)的缩写,MVCC没有统一的实现标准,不同的存储引擎对MVCC的实现方式是不同的,典型的有乐观并发控制和悲观并发控制。InnoDB对MVCC的实现采用的是乐观并发控制。
InnoDB-MVCC如何实现?
在《高性能mysql》一书中,关于InnoDB-MVCC的实现是这样介绍的:
InnoDB的MVCC,是通过在每行记录后保存两个隐藏的列来实现的(用户不可见)。一个列保存行创建的时间,一个列保存行过期(删除)的时间,这里所说的时间并不是传统意义上的时间,而是系统版本号,下面是REPEATABLE READ隔离级别下MVCC的具体操作:
- SELECT
InnoDB会根据以下两个条件检查每行记录:
(1)InnoDB只查找版本早于当前事务版本的数据行(行的系统版本号小于或者等于事务的系统版本号),这样可以确保事务读取到的行,要么是在事务开始之前已经存在的,要么是事务自身插入或者修改过的;
(2)行的删除版本要么未定义,要么大于当前事务版本号。可以确保事务读取到的行,在事务开启之前未被删除。
- INSERT
InnoDB为新插入的每一行保存当前系统版本号作为行版本号。
- DELETE
InnoDB为删除的每一行保存当前系统版本号作为行删除标识。
- UPDATE
InnoDB将更新后的列作为新的行插入数据表,并保存当前系统版本号作为该行的行版本号,同时保存当前系统版本号到原来的行作为行删除标识。
看完书中对MVCC具体操作的介绍之后,一开始感觉很有道理,但是自己脑补一个实例之后,马上感觉书中对SELECT操作的介绍存在的疑点,例如,在RR隔离级别下我开启了一个事务(事务版本号:1024),并且插入了一条id = 5的数据行,可想而知这条数据的行版本号应该是创建它的事务版本号1024,此刻(上一条事务未提交)我新开启一个事务(事务版本号1025),对全表进行SELECT,按照上面的逻辑当前事务可以查询到版本小于当前事务版本的数据行,那就是说可以查询到id = 5的数据。但是,按照RR隔离级别的约定,版本号为1025的事务并不被允许读取到这行数据,这就产生了矛盾。说到这里,大家也都应该能体会到我说的问题所在了。
听听官方文档怎么说
既然书中所述存在疑问,那我们就去看看MySQL的官方文档怎么说:

参考以上部分文档中所述,文中明确指出InnoDB为每一行数据都添加了三个隐藏字段,而删除标记有没有开辟特有的字段并未显式的说明,只说了在“特殊位置”被标记删除。也就是说,除了用户定义的字段以外,还有三个隐式的字段,简单的结构如下:
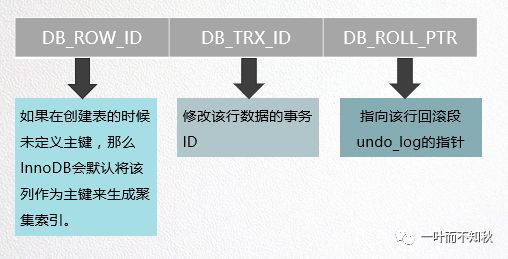
从图中可以看出这三个字段的具体作用,其中DB_ROW_ID是行ID,数据表在InnoDB的底层存储结构为B+树,而B+树需要根据主键来生成聚集索引,如果数据表的创建者未定义主键,那么InnoDB将会默认DB_ROW_ID作为主键来生成聚集索引;DB_TRX_ID是该数据行的事务ID,也就是前面《高性能MySQL》中所说的行“创建时间”;DB_ROLL_PTR保存的是一个指针,这个指针指向了该行回滚段中的undo_log。而MVCC就是根据DB_ROLL_PTR、DB_ROLL_PTR这两个字段(还有一个在“特殊位置”的删除标记)来构建事务可视版本(快照)的。
什么是回滚段?
回滚段是一个保存每条数据行之前版本日志的地方。回滚段中的撤销日志分为插入和更新撤销日志,插入撤销日志仅仅在事务回滚时需要,事务一提交就可以丢弃,更新撤销日志也用于一致性读取,但是只有在InnoDB没有分配快照的情况下,才可以丢弃这些快照,在一致性读取中可能需要更新撤销日志中的信息来构建数据库行的早期版本。
回滚段如何构造?
当一个事务更新一条记录时,会将更新后的记录作为新的一行插入,将旧的行构建为undo_log记录在回滚段中,并将新数据行的回滚字段DB_ROLL_PTR指向这个undo_log

当多个事务更新同一条事务时,undo_log会形成链式结构

了解了以上内容,我们开始具体讨论InnoDB-MVCC是如何实现多版本控制的。多版本实际上就是不同的事务都有着自己可视的数据版本,不同的事务数据版本是不同的。InnoDB-MVCC通过快照读的方式构建事务自己的可视版本,简单来说就是在事务操作之前获取当前的数据快照,这个快照所“呈现”的数据就是我当前事务的可视版本。那么快照该如何构建呢?继续往下看。
READ_VIEW
read_view是MySQL底层实现的一个结构体,是和SQL语句绑定的,在每个SQL语句执行前申请或获取。可以将其理解为构造快照的前提或者依据,一个快照所呈现的数据是什么样子(版本)的基本依赖于read_view中所存储的数据。
READ_VIEW底层实现
read_view是MySQL底层使用C++代码实现的一个结构体,如下图所示:

其中,构建当前可视版本(快照)主要用到的变量有low_limit_id、up_limit_id、trx_ids以及creator_trx_id:
low_limit_id:表示创建read_view时,当前事务活跃读写链表中最大的事务ID
up_limit_id:表示创建read_view时,当前事务活跃读写链表中最小的事务ID
trx_ids:创建read_view时,活跃事务链表里所有的事务ID
creator_trx_id:当前read_view所属事务的事务版本号
什么是当前事务活跃读写链表呢?可以将其理解为一个事务池,事务池中所存储的是当前所有正在运行(已开启但未提交)的事务。MySQL将当前所有活跃的事务保存在information_schema.innodb_trx表中,如下图所示:

READ_VIEW的作用
MVCC会根据read_view中所保存的信息来构建当前事务可视版本。
对于小于或者等于RC的隔离级别,事务开启后,每次执行SQL语句都会申请一个read_view,然后在执行完这个SQL语句后,调用read_view_close_for_mysql将read view从事务中删除。每次在执行SQL语句之前都会判断trx->read_view为空(理论下必为空),然后重新申请一个read_view(这就是为什么RC隔离级别下会产生不可重复读的原因)。
对于RR隔离级别,当申请一个read_view后,事务未提交不会删除,整个事务将不再申请新的read_view,保证事务中所使用的read_view都是同一个,从而实现可重复读的隔离级别。
MVCC-SELECT可见范围(总结)
了解了这么多,我们再回过头来总结一下MVCC的SELECT规则。因为除了上面所提到了部分内容,官方文档中也没有很详细的介绍MVCC的具体操作,我看了很多网上的总结,有人总结了三条,也有人总结了四条,但通过分析以后,本文总结六条供大家参考:
(1):DB_TRX_ID >= view->low_limit_id的记录不可见。DB_TRX_ID >= view->low_limit_id的记录必为当前事务开启之后开启的事务更新或插入的,所以不可见;
(2):DB_TRX_ID位于[view->up_limit_id,view->low_limit_id)区间时,如果存在于trx_ids集合中,则不可见。如果DB_TRX_ID存在于这个集合中,说明该记录的修改或创建者(事务)在当前事务开启时并未提交,所以不可见;
(3):DB_TRX_ID < view->up_limit_id的记录可见。DB_TRX_ID < view->up_limit_id,说明该记录的修改或创建者(事务)在当前事务开启之前已经提交,所以可见;
(4):DB_TRX_ID = creator_trx_id的记录可见。DB_TRX_ID = creator_trx_id说明该记录的修改或创建者(事务)是当前事务,所以可见;
(5):DB_TRX_ID != creator_trx_id的被标记删除记录可见。所有被删除且已提交的事务将被真正删除(删除但未提交只是标记删除),所以不会查询到,标记删除的记录除自身删除的以外,当前事务可见,DB_TRX_ID = creator_trx_id为自身删除所以不可见,其余皆可见;
(6):以上对于view不可见的记录,需要通过记录的DB_ROLL_PTR指针遍历回滚段中的undo_log构造当前view可见版本数据。不可见的记录只是说明该记录的当前版本不可见,但是它之前的某一版本是当前事务可见的,所以应当构建出该数据当前事务的可见版本。
思考:
在之前8月29日所发的InnoDB的MVCC是不是乐观锁?一文中,我们提到说MVCC是在RR和RC两种隔离级别之上实现的一种机制,但在本文中隐隐约约散发着一股“MVCC实现了RR和RC两种隔离级别”的气息。他们之间的关系具体是什么样的呢?留给大家去思考和探索。(我也在思考与求证当中,但更趋向于后者)
你如果想 学技术 | 屯干货 | 聊职场
以上是关于分析与总结InnoDB多版本并发控制机制-MVCC底层实现的主要内容,如果未能解决你的问题,请参考以下文章