惊!MySQL MVCC原来这么简单
Posted 落叶飞翔的蜗牛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了惊!MySQL MVCC原来这么简单相关的知识,希望对你有一定的参考价值。
扫码二维码
获取更多精彩


MVCC概述
相关概念介绍
案例分析
总结

1 MVCC概述


事务隔离级别怎么实现的呢?
MySQL InnoDB存储引擎的事务隔离级别主要是MVCC(MVCC,Multiversion Currency Control)实现的。
多版本控制: 指的是一种提高并发的技术。最早的数据库系统,只有读读之间可以并发,读写,写读,写写都要阻塞。引入多版本控制之后,只有写写之间相互阻塞,其他三种操作都可以并行,这样大幅度提高了InnoDB的并发度。在内部实现中,与Postgres在数据行上实现多版本不同,InnoDB是在undolog中实现的,通过undolog可以找回数据的历史版本。找回的数据历史版本可以提供给用户读(按照隔离级别的定义,有些读请求只能看到比较老的数据版本),也可以在回滚的时候覆盖数据页上的数据。在InnoDB内部中,会记录一个全局的活跃读写事务数组,其主要用来判断事务的可见性。


事务
实现
MVCC概述
1. MySQL的大多数事务型存储引擎实现的其实都不是简单的行级锁。基于提升并发性能的考虑, 它们一般都同时实现了多版本并发控制(MVCC)。不仅是MySQL, 包括Oracle,PostgreSQL等其他数据库系统也都实现了MVCC, 但各自的实现机制不尽相同, 因为MVCC没有一个统一的实现标准。
2. 可以将MVCC看成是行级锁的一个变种, 但是它在很多情况下避免了加锁操作, 因此开销更低。虽然实现机制有所不同, 但大都实现了非阻塞的读操作,写操作也只锁定必要的行。
3. MVCC的实现方式有多种, 典型的有乐观(optimistic)并发控制 和 悲观(pessimistic)并发控制。
4. MVCC只在 READ COMMITTED 和 REPEATABLE READ 两个隔离级别下工作。其他两个隔离级别都和MVCC不兼容, 因为 READ UNCOMMITTED 总是读取最新的数据行, 而不是符合当前事务版本的数据行。而 SERIALIZABLE 则会对所有读取的行都加锁。
MVCC是被MySQL中事务型存储引擎InnoDB 所支持的
应对高并发事务, MVCC比单纯的加锁更高效
MVCC只在READ COMMITTED和REPEATABLE READ两个隔离级别下工作
MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现
各数据库中MVCC实现并不统一
InnoDB的MVCC是通过在每行记录后面保存3个隐藏的列来实现的
2 相关概念介绍
概念
介绍
Read view
InnoDB支持MVCC多版本,其中RC(Read Committed)和RR(Repeatable Read)隔离级别是利用consistent read view(一致读视图)方式支持的。所谓consistent read view就是在某一时刻给事务系统trx_sys打snapshot(快照),把当时trx_sys状态(包括活跃读写事务数组)记下来,之后的所有读操作根据其事务ID(即trx_id)与snapshot中的trx_sys的状态作比较,以此判断read view对于事务的可见性。
Read view中保存的trx_sys状态主要包括
low_limit_id:high water mark,大于等于view->low_limit_id的事务对于view都是不可见的
up_limit_id:low water mark,小于view->up_limit_id的事务对于view一定是可见的
low_limit_no:trx_no小于view->low_limit_no的undo log对于view是可以purge的
rw_trx_ids:读写事务数组
RR隔离级别(除了Gap锁之外)和RC隔离级别的差别是创建snapshot时机不同。RR隔离级别是在事务开始时刻,确切地说是第一个读操作创建read view的;RC隔离级别是在语句开始时刻创建read view的。
创建/关闭read view需要持有trx_sys->mutex,会降低系统性能,5.7版本对此进行优化,在事务提交时session会cache只读事务的read view。下次创建read view,判断如果是只读事务并且系统的读写事务状态没有发生变化,即trx_sys的max_trx_id没有向前推进,而且没有新的读写事务产生,就可以重用上次的read view。
Read view创建之后,读数据时比较记录最后更新的trx_id和view的high/low water mark和读写事务数组即可判断可见性。
如前所述,如果记录最新数据是当前事务trx的更新结果,对应当前read view一定是可见的。
除此之外可以通过high/low water mark快速判断:
trx_id < view->up_limit_id的记录对于当前read view是一定可见的;
trx_id >= view->low_limit_id的记录对于当前read view是一定不可见的;
如果trx_id落在[up_limit_id, low_limit_id),需要在活跃读写事务数组查找trx_id是否存在,如果存在,记录对于当前read view是不可见的。
由于InnoDB的二级索引只保存page最后更新的trx_id,当利用二级索引进行查询的时候,如果page的trx_id小于view->up_limit_id,可以直接判断page的所有记录对于当前view是可见的,否则需要回clustered索引进行判断。
如果记录对于view不可见,需要通过记录的DB_ROLL_PTR指针遍历history list构造当前view可见版本数据。
概念
介绍
回滚段
InnoDB也是采用回滚段的方式构建old version记录,这跟Oracle方式类似。
记录的DB_ROLL_PTR指向最近一次更新所创建的回滚段;每条undo log也会指向更早版本的undo log,从而形成一条更新链。通过这个更新链,不同事务可以找到其对应版本的undo log,组成old version记录,这条链就是记录的history list。
分配rollback segment
MySQL 5.6对于没有显示指定READ ONLY事务,默认为是读写事务。在事务开启时刻分配trx_id和回滚段,并把当前事务加到trx_sys的读写事务数组中。
5.7版本对于所有事务默认为只读事务,遇到第一个写操作时,只读事务切换成读写事务分配trx_id和回滚段,并把当前事务加到trx_sys的读写事务数组中。
分配回滚段的工作在函数trx_assign_rseg_low进行,分配策略是采用round-robin方式。
从5.6开始支持独立的undo表空间,InnoDB支持128个undo回滚段。
rseg0:
预留在系统表空间ibdata中
rseg1~rseg32:
这32个回滚段存放于临时表的系统表空间中
rseg33~rseg127:
根据配置存放到独立undo表空间中(如果没有打开独立Undo表空间,则存放于ibdata中)
trx_assign_rseg_low判断,如果支持独立的undo表空间,在undo表空间有可用回滚段的情况下避免使用系统表空间的回滚段。
分配undo logInsert数据只对当前事务或者提交之后可见,所以insert的undo log在事务commit后就可以释放了。
Update/Delete的undo记录通常用来维护old version记录,为查询提供服务;只有当trx_sys中没有任何view需要访问那个old version的数据时才可以被释放。
InnoDB对insert和update/delete分配不同的undo slot
insert的undo slot记在trx->rsegs.m_redo.insert_undo,调用trx_undo_assign_undo分配
update的undo slot记在trx->rsegs.m_redo.undate_undo,调用trx_undo_assign_undo分配
3 案例分析
InnoDB 里面每个事务有一个唯一的事务 ID,叫做 transaction id。它是在事务开始的时候向 InnoDB 的事务系统申请的,是按申请顺序严格递增的。
对于数据库的每行记录,MySQL都会有三个隐藏字段:db_trx_id (事务 id)、db_roll_pt (回滚指针)、delete_flag(删除标记)。
对于 DML 操作来说:
INSERT:创建一条数据,
db_trx_id的值为当前事务id,db_roll_pt为null。UPDATE:复制一行数据,将当前复制后这一行的
db_trx_id置为当前事务的id,db_roll_pt是一个指针,指向复制前的那一条的。DELETE:复制一行数据,将当前复制后这一行的
db_trx_id置为当前事务的id,db_roll_pt是一个指针,指向复制前的那一条的并把delete_flag置为true。
创建数据表t,用于做案例分析。
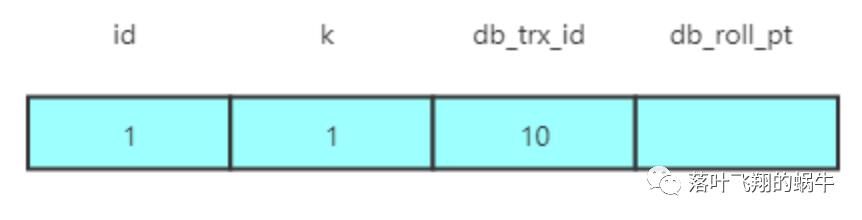
CREATE TABLE `t` (`id` int(11) NOT NULL,`k` varchar(32) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB;insert into t(id, k) values(1, 1);
插入数据后,数据的初始状态如下图所示。
设置隔离级别为MySQL默认的隔离级别——Repeatable Read。
分别开启4个事务用于实验。
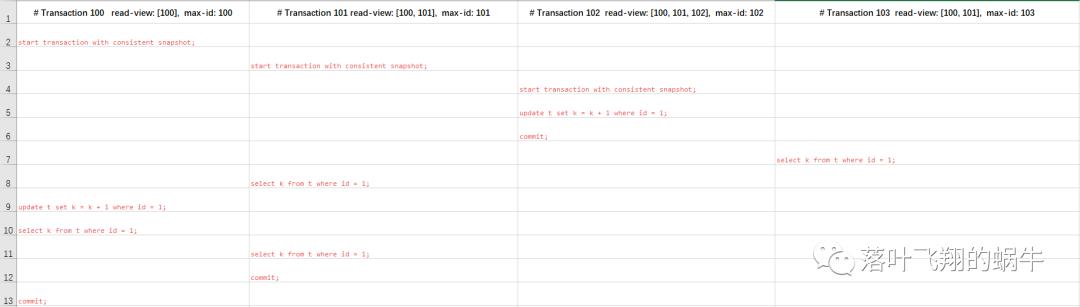
上图中第 8,10,12,13 行,
查询的结果分别是什么呢?


结果应该分别是:2,1,3,1 ~


下面我们来逐步回放,MySQL 底层是如何实现这整个过程的。
第 1 行:表示每个事务的 ID 号,其中 read view 取的是所有当前活跃的事务 ID 数组,活跃指的是,已开启并生成事务 ID 但未提交的事务。max id 取的是,目前为止,最大的事务 ID,不论是否已提交。我们还称 read view 数组中,最小的值为 min id。
第 2 - 4 行:表示分别开启事务,并创建此事务的 read view 及 max id,要注意的是,这里我并没有使用 begin/start transaction 来开启事务,是因为它们并不会马上创建 read view 及 max id,而是在执行第一条 select 语句后,来进行创建的。
第 5 行为修改 k 的值,自增 1,按照上面所说的规则,修改后数据的状态如下:
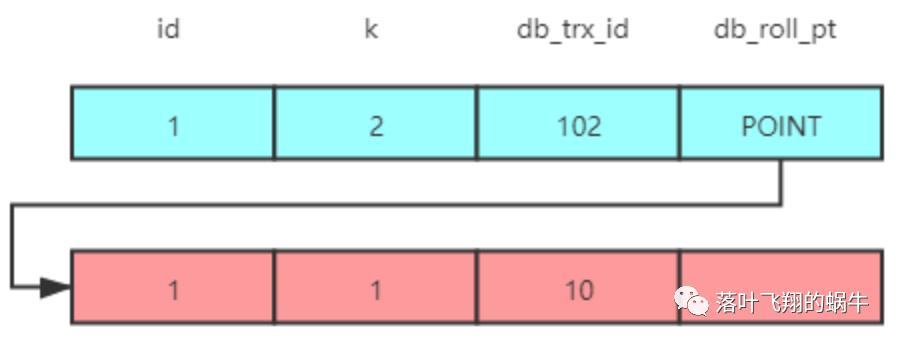
第 6 行,提交 ID 为 102 的事务。
第 7 行执行了一个简单查询,未手动开启事务,但也会自动开启并生成 read view 及 max id,分别为 read-view: [100, 101] ,max-id: 103
此时会根据查询规则,进行查找,规则如下:
1. 如果数据的 db_trx_id < min id ,则说明数据在开启当前事务前已提交的,内容可见。
2. 如果数据的 db_trx_id > max id ,则说明数据在此事务启动后生成的,内容不可见。
3. 如果数据的 min id <= db_trx_id <= max id ,则还分为两种情况:
3.1 若 db_trx_id 在 read view 的数组中,表示这个版本是由还没提交的事务生成的,不可见,但如果是自己的事务,则可见。
3.2. 若不在数据中,则表示这个版本是已经提交了的事务生成的,可见。
示意图如下
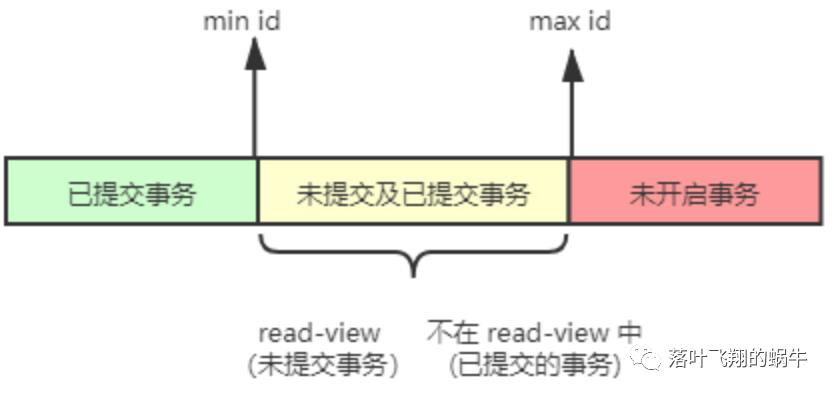
当前的事务的一致性视图为 read view: [100, 101] ,max id: 103,那么根据这个规则,在上面的数据链中查询数据,从最新的蓝色,开始找,找到第一个数据的 db_trx_id 为 102,符合规则 3.2 属于可见范围,查询结果为 2。
第 8 行,当前的事务的一致性视图为 read view: [100, 101] ,max id: 101。同样根据规则,第一个数据的 db_trx_id 为 102,符合规则 2,不可见,那么根据指针 db_roll_pt 继续查找,找到 db_trx_id 为 10 的数据,符合规则 1,数据可见,查询结果为 1。
第 9 行,修改 k 的值,自增 1,按照上面所说的规则,修改后:
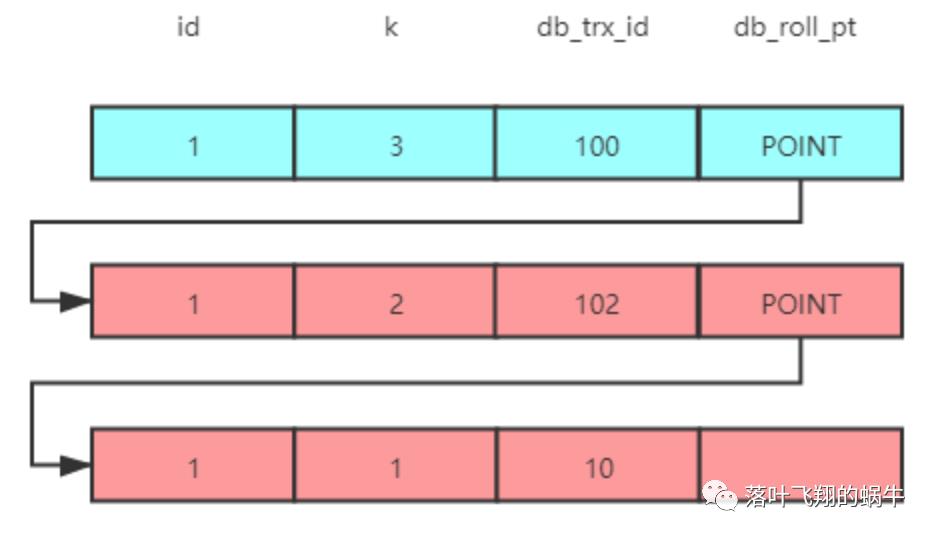
第 10 行,当前的事务的一致性视图为 read view: [100] ,max id: 100 同样根据规则,第一个数据的 db_trx_id 为 100,符合规则 3.1,在 read view 数组中,但是此 id 为当前事务 id,所以可是可见的,查询结果为 3。
第 11 行,当前的事务的一致性视图为 read view: [100, 101] ,max id: 101 同样根据规则,第一个数据的 db_trx_id 为 100,符合规则 3.1,在 read view 中,但是此 id 不为当前事务 id,所以内容不可见的,那么根据指针 db_roll_pt 继续查找,找到 db_trx_id 为 102 的数据,符合规则 2,不可见,继续根据指针 db_roll_pt 查找,找到 db_trx_id 为 10 的数据,符合规则 1,数据可见,查询结果为 1。
第 12 - 13 行,为提交事务语句。
处于 Read Committed 读已提交 也可套用上面的规则,不过一致性视图:read view 和 max id 的创建时机,是每一条 select 语句时重新生成。你根据上面的内容,可以自己动手试验下读已提交。
4 总结
一般我们认为MVCC有下面几个特点:
每行数据都存在一个版本,每次数据更新时都更新该版本
修改时Copy出当前版本, 然后随意修改,各个事务之间无干扰
保存时比较版本号,如果成功(commit),则覆盖原记录, 失败则放弃copy(rollback)
就是每行都有版本号,保存时根据版本号决定是否成功,听起来含有乐观锁的味道, 因为这看起来正是,在提交的时候才能知道到底能否提交成功
InnoDB实现MVCC的方式是:
事务以排他锁的形式修改原始数据
把修改前的数据存放于undo log,通过回滚指针与主数据关联
修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
二者最本质的区别是: 当修改数据时是否要排他锁定,如果锁定了还算不算是MVCC?
Innodb的实现真算不上MVCC, 因为并没有实现核心的多版本共存, undo log 中的内容只是串行化的结果, 记录了多个事务的过程, 不属于多版本共存。但理想的MVCC是难以实现的, 当事务仅修改一行记录使用理想的MVCC模式是没有问题的, 可以通过比较版本号进行回滚, 但当事务影响到多行数据时, 理想的MVCC就无能为力了。
比如, 如果事务A执行理想的MVCC, 修改Row1成功, 而修改Row2失败, 此时需要回滚Row1, 但因为Row1没有被锁定, 其数据可能又被事务B所修改, 如果此时回滚Row1的内容,则会破坏事务B的修改结果,导致事务B违反ACID。这也正是所谓“第一类更新丢失”的情况。
也正是因为InnoDB使用的MVCC中结合了排他锁, 不是纯的MVCC, 所以第一类更新丢失”是不会出现了, 一般说更新丢失都是指第二类丢失更新。

扫码二维码
获取更多精彩
以上是关于惊!MySQL MVCC原来这么简单的主要内容,如果未能解决你的问题,请参考以下文章