大型分布式系统集成测试实践和探索之测试痛点
Posted 百度QA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大型分布式系统集成测试实践和探索之测试痛点相关的知识,希望对你有一定的参考价值。
随着服务使用人群和相应产生数据的激增,越来越多系统选择横向或者纵向扩展,以分布式技术为底层解决承载能力问题。分布式系统具有可扩展、抗单点(没有SOP问题)等技术优势,同时以低廉成本(廉价服务器)带来更多业务支撑。
但分布式系统内部逻辑复杂、外部服务耦合模块众多,为相关测试带来不小的挑战。本文以分布式系统测试难点之一集成测试为切入点,带领各位分析分布式系统集成测试遇到的痛点成因、当前合理的应对措施、进行中但悬而未决的问题思考。
一、分布式系统集成测试痛点
在分布式系统集成测试中,我们发现如下4个痛点普遍存在。后文每一个痛点都辅以相应的分析。
分布式系统生态中上下游耦合模块多,耦合交叉部分测试覆盖薄弱;
上下游模块间集成测试没有明确测试标准,测试人员间信息不对称;
跨层次的组合场景测试缺失或混乱无秩序,测试范围实质固化在当前系统层面;
风险自底层向上扩散,缺少整体风险评估。
1.1 薄弱的交叉耦合部分
误区一:沙盒联调测试稳定代表集成测试过关
以下图真实项目场景为例,为实现Master服务的高可用,主(primary)备(slave)Master服务节点会进行元信息(meta)数据同步。其中主primary把要变更的操作以Redo Log方式写入底层分布式文件系统。备从底层分布式文件系统tail方式读取日志并加载进内存数据结构中。
将分布式文件系统看作黑盒的话,上游的Master service服务测试人员在沙盒上进行功能、性能、压力等层面进行正常系统沙盒测试即完成了集成测试的部分。
(图例:主从原信息同步)
但我们能完全将底层的分布式文件系统看作黑盒吗?
由于上下游服务的测试都由笔者技术负责,所以容易得到整个生态数据流原貌: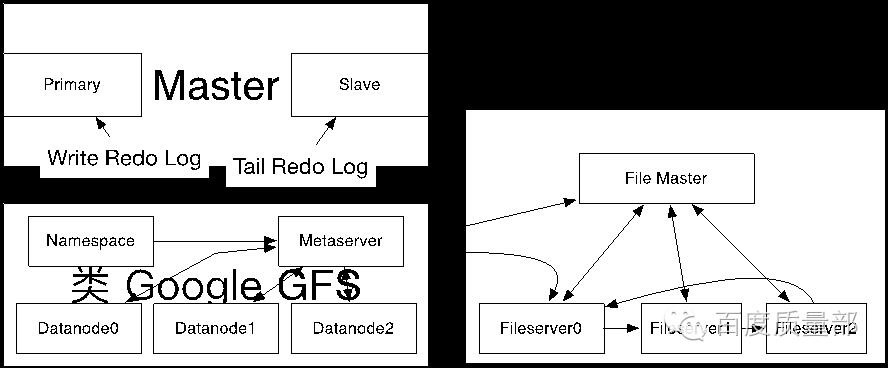
(图例:数据流有删减)
互联网企业的分布式系统大多使用经济型服务器(成本较低、故障率略高),每个数据流环节都可能出现局部故障。每个局部故障都可能产生一段时序逻辑。看完这个数据流,大家还能淡定的将底层完全看做黑盒来进行集成测试吗?
1.2 缺失的集成测试标准
误区二:公司内部项目组测试标准一致,大家测试力度大体相当
假设如下三种场景发生:
恰巧1.1中提到的测试处于同一项目组;
恰巧处于同部门但不同项目组;
处于不同部门(不同项目组)。
第一种情况较为理想,同一项目组内部可以评估集成测试力度,可以跳出单一项目功能测试从整体系统生态来考量测试标准。
现实生活当中第二第三种更为普遍。这时测试标准的差异就会体现。
关注底层稳定性的上游测试组,会迫切希望下游系统提供稳定性波动因素列表、按照等级划分的故障恢复计划等来完善集成测试的薄弱环节。同理,独立思考的下游测试项目组会对上游提醒注意如上内容的场景设计。
而当双方不处于同一测试力度时,会表现的要么用力过猛、要么潦草走过场。测试质量最终参差不齐。
测试力度用力过猛,以快速迭代试错容忍小故障的服务可能错过最佳发布期。潦草走过场,质量和稳定为上的系统生态,大范围看这部分就是木桶中那块短木。
1.3 混乱无序的组合测试
a.可以造成分布式系统稳定性抖动非常多,对上游系统暴露何种稳定性抖动或者故障接口以及如何暴露这些接口是我们面临的难题。
(图例:部分稳定性抖动因素)
b.当接口列表确定后,以什么样的规则进行上下游系统接口场景组合、场景组合验证通过标准成为接下来考虑的问题。
1.4 系统集成的风险评估
集成测试风险集中在哪些环节、风险评估的标准、评估标准如何指导集成测试,这些问题是引入风险评估时需要考量的问题。
风险评估后,需要根据项目情况分析并制定:
质量风险的底线;
短期集成测试计划和长期集成测试需达到的可量化的成熟度。
知晓分布式系统集成测试的测试痛点后,如何针对相应问题进行实践和探索,如何在实践中抽象出通用的模型和方法,如何甄别通用方法解决了哪些问题、哪些问题悬而未决成为我们后续考虑的问题。该系列问题分成三部分,后两部分”实践和探索、通用集成测试模型”将在后续系列主题中展开介绍,敬请期待!
关注“百度质量部”订阅号,回复以下内容立马查看干货哦~
-----------------------------------------------------------
1.回复关键词“评测”查看评测系列文章
2.回复关键词“CI”查看CI系列经验分享
3.回复关键词“移动测试”查看移动测试系列工具点评
以上是关于大型分布式系统集成测试实践和探索之测试痛点的主要内容,如果未能解决你的问题,请参考以下文章