微服务集成测试自动化探索
Posted 51NB技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微服务集成测试自动化探索相关的知识,希望对你有一定的参考价值。
杜亮亮
51信用卡基础技术部测试负责人,经历并参与了51信用卡测试技术架构的开发和演进。
简介
51信用卡自2015年开始实施微服务架构,是业界较早尝试微服务架构的技术团队,整个团队有幸见证了微服务从最初的几个服务试点到全面铺开的过程。架构的演变也催生了自动化测试框架和策略的演变,测试团队通过持续地探索和总结,在集成测试自动化框架建设和策略选择上积累了一些经验,抛砖引玉和大家一起分享。

微服务架构下集成测试自动化的困境
1.1
微服务架构给测试带来的改变
先看下《微服务设计》1.3章节对SOA的定义:
SOA(Service-Oriented Architecture,面向服务的架构)是一种设计方法,其中包含多个服务,而服务之间通过配合最终会提供一系列的功能。一个服务通常以独立的形式存在于操作系统进程中。服务之间通过网络调用,而非采用进程内调用的方式进行通信。
微服务架构是SOA的一种特定方法,基于这种架构在开发层面带来的好处在《微服务设计》一书中描述得很清楚了。从测试角度来看,通信方式由进程内调用变成网络调用,最明显的改变有两个:
第一,数据流转更加清晰。微服务架构下的时序图非常清晰,服务之间分工明确,代替了传统服务数据只在服务内部模块间流转的方式。
第二,数据入口多元化,可测试性增强。服务的拆分带来的另一个好处就是测试粒度变小变细,每个微服务都具备独立的网络调用方式,不管是提供Http接口还是消费消息队列,都给集成测试可测试性和覆盖率带来了便利和提升。
1.2
集成测试自动化的困境
软件工程没有银弹,对于微服务也是一样。在《微服务设计》1.1.1章节做着Sam Newman对微服务架构的担忧:
当考虑(微服务)多小才足够小的时候,我会考虑这些因素:服务越小,微服务架构的优点和缺点也就越明显。使用的服务越小,独立性带来的好处就越多。但是管理大量服务也会越复杂,本书的剩余部分会详细讨论这一复杂性。如果你能够更好地处理这一复杂性,那么就可以尽情地使用微服务了。
一方面服务拆分给测试带来很多便利,另一方面服务数量的增加也带来了测试复杂度的指数增长,好像陷入了一种囚徒困境。
以下图的功能为例,该功能一共涉及了7个微服务,2个消息中间件,还有没在时序图上体现的两种DB(mysql/cassandra)和缓存中间件(redis)。由于服务和中间件之间的调用也是网络调用,所以在测试过程可以把中间件和DB当成一个微服务节点来分析。面对这样一个涉及12个微服务的功能(不考虑集测自动化策略,比如拆分成几个小功能分块实现自动化降低复杂度),我们需要一个什么样的框架来支撑,才能让测试工程师写出的集测自动化case具备易用性、可维护性这些美好的特性。
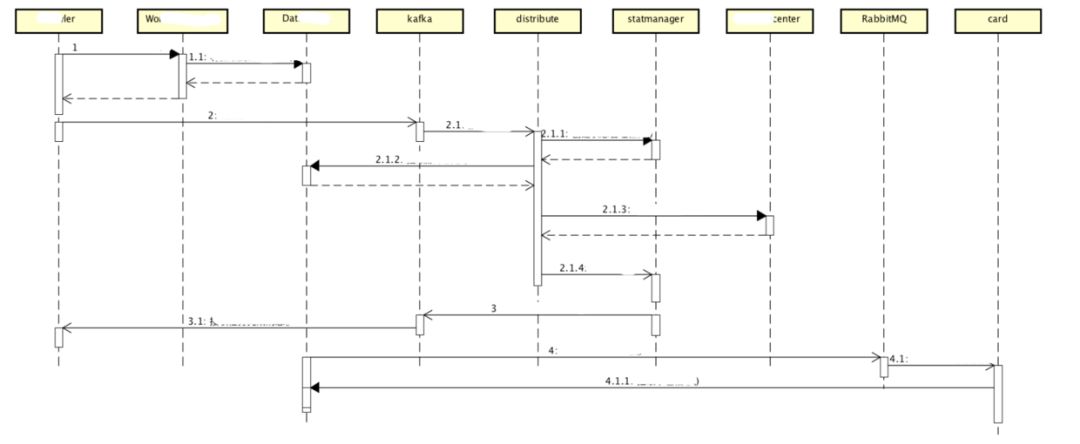
图一
1.3
拆解困境
当时51信用卡的集测框架大概使用了一年多,中间迭代过两个大的版本,已经从最原始的纯Java框架过渡到基于关键字驱动和数据驱动开发的框架,原理参考下图:
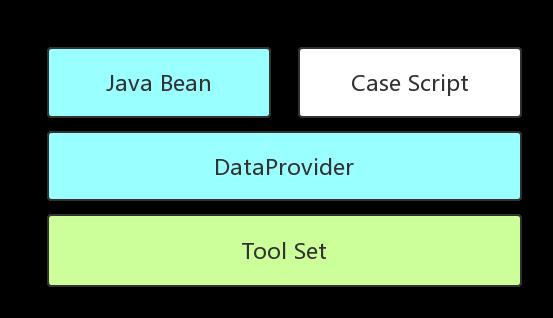
图二
初代框架第一层是测试脚本(参考下图的代码)和Java Bean,第三层是工具层,由常用的Util类组成,比如:MysqlClientUtil、HttpClientUtil、RedisClientUtil等。第二层是解析层或者执行层,它会将第一层的测试脚本初始化为对应的Java Bean实例,然后再把实例拆分成各个Util类的静态方法执行。
//初代框架测试脚本
{
"mysqlClient": {
"url": "mysqlurl:3306",
"username": "username",
"password": "password",
"sqlList": [
"insert into user (userid, username) values (123456, 'zhangsan')"
]
},
"httpClient": {
"reqeust": {
"method": "GET",
"url": "serice/queryUserInfo",
"headers": null,
"query": {
"userid": 123456
},
"body": null
},
"responseExpected": {
"headers": null
"body": {
"username": "zhangsan"
}
}
},
"redisClient": {
"address": "redisaddress:6307",
"command": "get userinfo:123456"
"resultExpected": {
"username": "zhangsan"
}
}
}
初代框架在面临图一复杂的功能时,最重要的一个问题就是扩展性。脚本的每个modul都代表了一次网络调用,可读性很好。但是测试流程被固化在每个Java Bean之中,每一个新的功能都有可能要定制一个新的Java Bean(调整action调用顺序)和DataProvider(图一 蓝色部分)。而当Util类变更时,同样需要变更Java Bean和DataProvider,这个变更的工作量堪称地狱级。
第二个问题是数据的重用。图二中的userid这个字段在脚本中出现3次,在某些复杂场景下可能就不是一个字段而是整个数据结构,降低了case的可维护性。数据库连接和中间件连接(脚本中的redis client)每个case都会先初始化再销毁,这个对于执行效率也是一种影响。
基础框架有了,问题也找到了,下面我们要做的就是改造基础框架来满足新的自动化需求。
2
造一个“轮子”逃出困境
2.1
BDD&DSL
In software engineering, behavior-driven development (BDD) is a software development process that emerged from test-driven development(TDD).[1][2][3][vague] Behavior-driven development combines the general techniques and principles of TDD with ideas from domain-driven design and object-oriented analysis and design to provide software development and management teams with shared tools and a shared process to collaborate on software development.[1][4]
BDD is largely facilitated through the use of a simple domain-specific language (DSL) using natural language constructs (e.g., English-like sentences) that can express the behavior and the expected outcomes. Test scripts have long been a popular application of DSLs with varying degrees of sophistication. BDD is considered an effective technical practice especially when the "problem space" of the business problem to solve is complex.[5]
——BDD
在寻找扩展性解决方案的过程中,了解到兄弟部门正在尝试用Rest-Assured代替初代框架中基于Apache HttpClient封装的Util。通过了解Rest-Assured我们接触到了BDD,其中领域驱动设计(domain-driven design)的idea让我们沉思:是不是初代框架在设计模式上就有缺陷?
从元数据角度看,BDD中的behavior和关键字驱动是一个概念,关键字相对独立和分散,BDD的优势是通过领域驱动对behavior做了一层抽象,并通过一定的逻辑(given when then)将behavior串联成一个具体的功能。这样带来的好处是,所有的behavior在当前领域只做一件事,比如在测试领域behavior就是做功能验证(或者为功能验证做准备),我们要做的就是针对测试领域的behavior抽象出一个父类,并通过一定规则将不同的behavior串联起来。
从case脚本的表现力来对比,数据驱动下的脚本只做数据存储,BDD使用DSL作为脚本语言,可以表达出更丰富的行为和预期结果(express the behavior and the expected outcomes),可读性和信息的承载度上了一个台阶。这一part我们要做的就是选择合适的语言作为框架的DSL。
通过对比BDD和关键字+数据驱动混合模式,我们得到了两个action,后面要做的就是验证action是否正确。
2.2
行为父类Behavior
测试的本质就是功能验证,所有的行为不是为了功能验证就是在为验证做准备。举个例子,测一个查询接口,首先在DB中插入需要的数据,然后调用查询接口,最后对比接口返回的实际数据是否和预期数据一致。在这个数据流转过程中,插入DB的数据可能有部分和接口返回的数据是同一个,手工执行的过程中,这些数据会存在测试工程的脑海或者中间媒介,相当于线程中的上下文,而每个行为都有可能去操作这个上下文。
针对上文测试行为的两个特征,抽象了两个接口CompareIntf和AssignContextIntf。CompareIntf负责功能验证,返回值就是预期值和实际值的对比结果,如果是为了验证做准备的行为,比如向DB插入数据,以行为的成功与否作为返回值。AssignContextIntf负责和上下文进行数据交互,包括增删改查,而且只有当CompareIntf返回true的时候才会执行AssignContextIntf。
//测试行为接口抽象
public interface CompareIntf {
public boolean compareExpectAndActual();
}
public interface AssignContextIntf {
public void assignContext();
}
最终抽象出的父类参考下文UML类图。Behavior类成员变量中的两个Map以及相关的api先按下不表,下一章节会介绍其作用。className的取值是子类的包名+类名,作用是通过类加载器以及双亲委派机制实例化子类,从而舍弃了初代框架中的固定的Java Bean,将框架和具体行为的类名解耦,框架只负责流程的执行而不用关心流程中涉及哪些行为类,从而解决了扩展性的问题。
remark的作用是对className的应用场景做一个补充,比如调用某微服务查询接口,让每个行为的意图都保存在case中,增加可维护性。
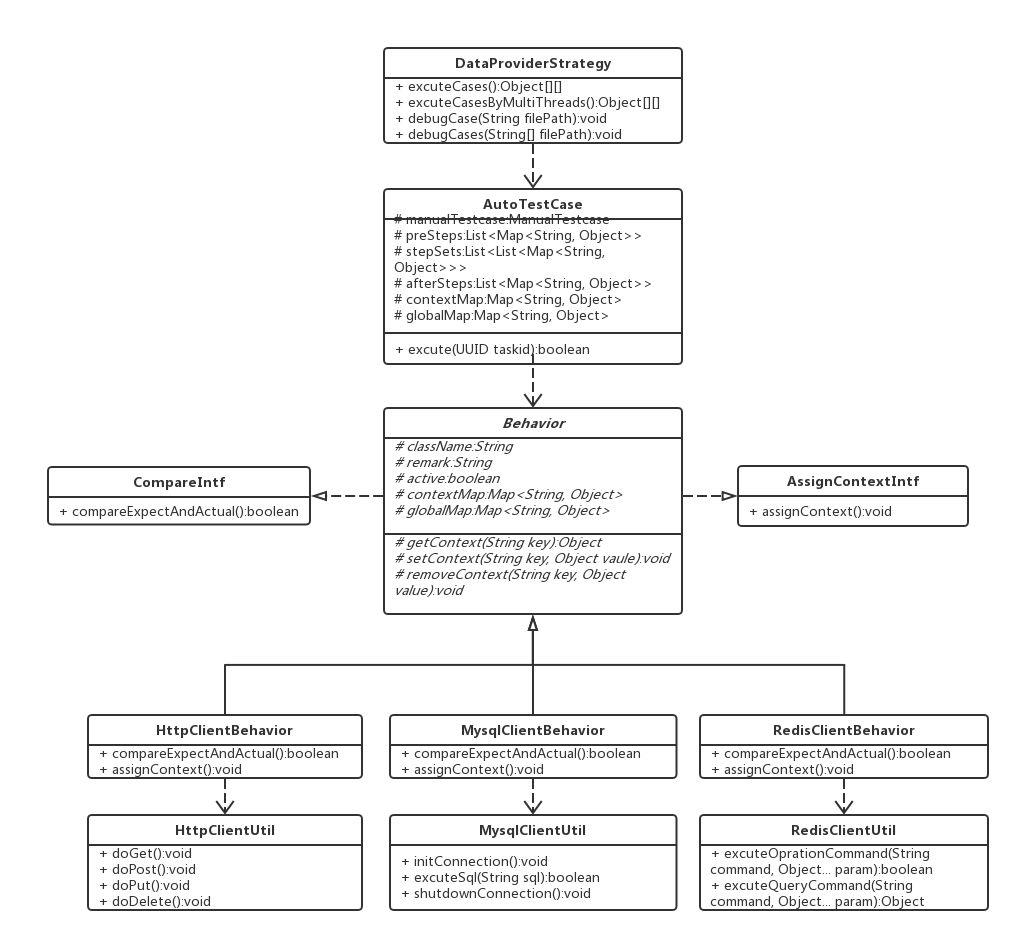
图三
确定了父类之后,我们把初代框架第三层中的所有Util类都套上了一层装饰器(Behavior的子类),主体逻辑在放在CompareIntf实现中。拿web开发类比的话,Behavior类似Controller,用来作为数据的入口,而Util类和Service类一样,负责功能的主体逻辑。
接着我们又把行为类进行分类,把功能类似的行为类放到同一个工程作为一个Library,这样Library与框架,Library与Library之间都完成了解耦。
解决了父类的抽象和扩展性问题,就差一个框架把所有的行为类整合成一条完整的自动化case了。
2.3
AutoTestFrame
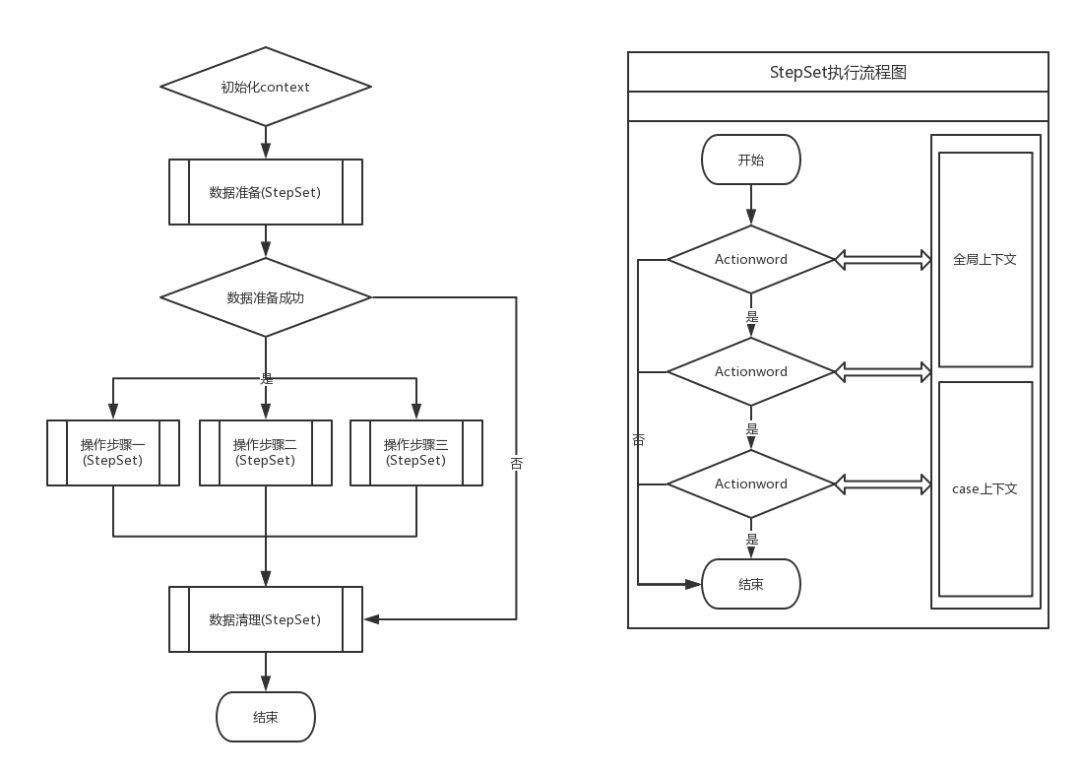
图四
在分析自动化用例执行流程时,我们发现和传统基于BDD开发的工具不一样的是,测试用例的执行流程give-when-then非常固定。参考图四左边流程图,把用例分割成三个部分数据准备-操作步骤-数据清理,首先执行数据准备,执行成功则执行操作步骤-数据清理,失败的话跳过操作步骤,直接执行数据清理,保证case不管成功失败对整个环境都是幂等操作。
用例的三个部分,不管是数据准备还是操作步骤,通常都不是单独的一个行为类,而是行为类的集合。我们把多个行为类组成一个StepSet,数据准备和数据清理都是一个StepSet,操作步骤有点特殊,会并行执行的多个StepSet。
StepSet的执行逻辑参考图四1右边的流程图,串行执行行为类的compareExpectAndActual方法,返回true则执行下一个,返回false则break整个流程,case执行失败。执行过程中行为类会和两个上下文发生数据交互,也就是上个章节行为类的两个Map成员。
基于以上的分析,我们在DSL中去掉了流程关键字(give-when-then),把流程控制硬编码在框架中。至此第一个action两part都解决了,框架的雏形接近完成,也该有个名字了,AutoTestFrame,简称ATF。
2.4
DSL选择
这一章没有前面那么多去伪存真的过程,ATF还是沿用了初版框架中Json作为DSL,而没有选择BDD推荐的自然语言。原因有三个:第一,Json在51微服务的架构中具有天生的优势,服务间的通信使用Http+Json的REST规范,处于亲儿子的地位;第二,KV 类语言有着接近自然语言的表现力,除了Json还有xml,yaml等,初代框架的脚本在加上remark之后基本处于可读的状态;第三,Json to Java有着丰富的第三方库,Jackson、FastJson、Gson等,省去了编写和维护DSL解析器的精力。
既然是DSL,在易读的同时也会有一些抽象的特性来简化操作。ATF通过占位符配合关键字开发了一些常用的特性,比如时间函数(参考图五)、Jpath、加解密等,这些DSL会在行为类初始化之前被替换为实际值。
图五

2.5
框架的应用
到此为止,ATF通过引入ClassName和类加载器、规范case执行流程、确定DSL解决了扩展性问题,通过提取上下文并赋予行为类的上下文访问权限解决了数据重用问题,那开篇提到的问题有没有解决?实际在项目中使用的结果如何?
先来看下开篇提到的功能最终的脚本,参考图六,最终我们把时序图拆成了三个部分来实现集测自动化,图中的脚本是从发送kafka消息开始一直到倒数第三个服务结束。脚本基本还原了时序图,具备不错的可读性,即使换一个完全不了解该业务的测试工程师,也能很快领会脚本的意图。至于case的debug,和jenkins的打通由于篇幅有限,这里就不过多介绍了。
ATF在51信用卡实施了一年多,有一个Library专门维护集测常用的60多个行为类,包括各种消息中间件、DB、Http等。除此之外,我们也开发了和Appium、Selenium相关的Library,还在试用阶段。不完全统计,目前已经使用ATF的项目超过50个,平均集测覆盖率超过30%,核心业务的覆盖率超过60%。
图六

2.6
RobotFramework
太阳底下没有新鲜事,51信用卡经过三次迭代开发的集测自动化框架ATF,并不是在自动化领域第一个吃螃蟹的。
Robot Framework is a Python-based, extensible keyword-driven test automation framework for end-to-end acceptance testing and acceptance-test-driven development (ATDD). It can be used for testing distributed, heterogeneous applications, where verification requires touching several technologies and interfaces.
目前官方提供超过60个Libraries,不仅涉及集成测试领域,还包括App、Web、DeskTop Client等多个领域。虽然RobotFramework是用Python编写,但是可以通过一个扩展LibraryJavalibCore作为胶水来粘合Java编写的Library。除了DSL外,RobotFramework还有一个DesckTop Client,支持通过GUI来编辑DSL,进一步降低了自动化的准入门槛。
表面上看我们似乎是照猫画虎造了个java版的RF,还是简易版的,都是用同一种思想解决同样的领域问题。实际上,就像每种编程语言都会有独立的HttpClient Library,在自动化领域,Library之于框架的价值等同于Library之于编程语言的价值,它们才是背后默默奉献的螺丝钉。虽然RF有类似胶水语言的Library来解决跨语言的问题,可能并没有JVM的内部调用来的可靠。所以,无论是在Library和业务贴合性上,还是在框架语言、DSL选择上,对于51信用卡现有微服务的架构和技术栈,ATF都更适合在当前体系下扮演集成测试自动化框架的角色。
3
总结
图七
随着ATF支撑的服务数量和case数量的增加,我们遇到了很多新的问题。当单服务的case数量超过一定数量时,超过了设定的阈值(5分钟),ATF新增了用例过滤策略、并发执行策略(图七)来缩短执行时间。今年年初我们将ATF整合进用例管理平台,通过web页面也可以完成自动化用例编写。在实现remote excutor时,我们利用URLClassLoader自定义管理Libraries,实现了行为类热加载,目前正在试用阶段,后面还会支持高可用高并发等更多特性。好的框架一定是与时俱进,通过不断迭代解决实际的问题,ATF还很年轻,我们相信它还会有第四、第五、第N次迭代。
引用
1. 《微服务设计》Sam Newman著 崔力强 张骏译
2. BDD
https://en.wikipedia.org/wiki/Behavior-driven_development
3. 《从数据驱动到各种驱动》
https://zhuanlan.zhihu.com/p/30588403
4.RobotFrameword wiki
https://en.wikipedia.org/wiki/Robot_Framework#cite_note-2
5.JavaLibCore 、https://github.com/robotframework/JavalibCore/wiki/Getting-Started
了解更多51信用卡NB技术!
以上是关于微服务集成测试自动化探索的主要内容,如果未能解决你的问题,请参考以下文章