Django 与数据库交互中的九个知识点
Posted Python程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Django 与数据库交互中的九个知识点相关的知识,希望对你有一定的参考价值。
Python部落(python.freelycode.com)组织翻译,禁止转载,欢迎转发。
对于开发人员来说,虽然对象映射关系(ORMs)确实非常的有用,但是数据库的访问也是有成本的(例如:计算成本与时间成本)。那些沉浸于数据库开发的研究人员经常会发现,一点小小的改变,就可以换得性能上的巨大提升。
在此篇文章中,我将分享在 Django 中使用数据库的 9 个小技巧。
1. 过滤器聚合
在 Django 2.0 之前,如果你想得到“用户总数”、“活跃用户总数”等信息时,你不得不使用条件表达式。
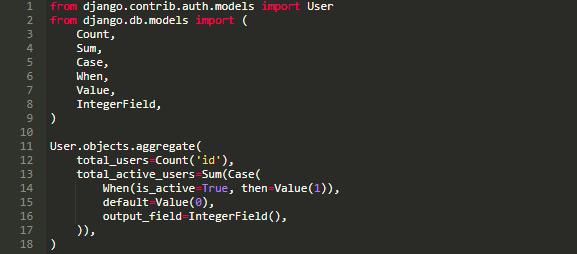
Django 2.0 中,通过在聚合函数中添加一个过滤器使这种问题变得更加简单、容易处理:

怎么样? 看起来很简洁明了吧。 如果你使用的是 PostgreSQL 的话,若要进行这种查询,查询程序如下:
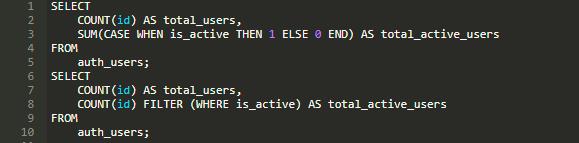
可以看到,在第二个查询语句中,使用 FILTER(WHERE) 过滤语句。
2. 将查询结果变为 namedtuples 形式
我个人非常喜欢 namedtuples。 从 Django 2.0 之后,ORM 也同样青睐于 namedtuples。
在 Django 2.0 中, 在 value_list 方法中添加了一个名为 named 的属性。将 name 设置为 True,查询结果将以 namedtuples 的形式展示。
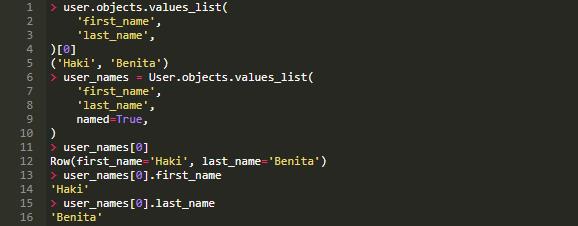
3. 自定义函数
Django 的 ORM 功能强大且内容丰富。但是却不可能紧跟所有的数据库供应商的步伐。幸运的是, ORM 允许用户根据自身需要开发自定义的函数。
假设我们有一个报告模型,其中包含了一个记录“持续时间”(duration)的值。现在,我们想要找到所有报告的平均持续时间:

看上去还不错的样子, 但是一个平均值包含的信息有点少。下面让我们计算一下标准差:
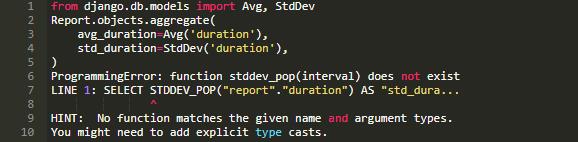
为什么错误了? PostgreSQL 不支持对间隔类型字段数据进行标准差计算。我们需要先将间隔变为数字,然后再用 STDDEV_POP 去计算标准差。
一个可行的解决办法就是从持续时间中提取数据:
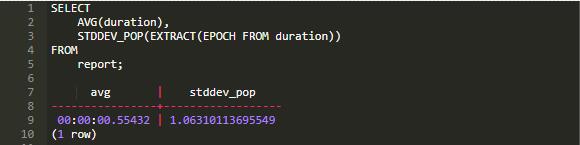
那么问题来了,我们如何在 Django 中实现上述操作? 我想你已经猜到了, 答案就是:自定义的函数:

我们定义的函数调用形式如下:
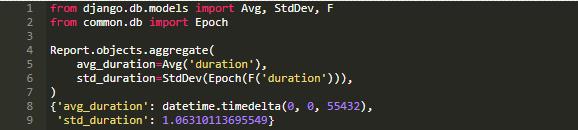
需要注意的是,我们在调用 Epoch 自定义函数时使用了 F 表达式。
4. 超时声明
这个可能是所有小知识点中,最简单但却最重要的小知识点。 正所谓:人非圣贤,孰能无过。我们不能对每种边缘情况面面俱到,所以我们需要设置边界条件。
与 Tornado, asyncio 或者 Node 这些非阻塞程序服务不同, Django 经常会用到同步工作进程。这也就意味着,当一个用户的操作程序运行很长时间时,工作进程处于阻塞状态,其他人都无法使用,直到此人的操作程序运行完毕。
我想在实际情况活中, 没有人会只使用一个工作进程来运行 Django。但是我们仍旧希望一个查询进程不会占用太多的资源和时间。
在很多 Django 应用程序中,大部分时间都用在了等待数据库查询结果上。所以,在查询语句中设置一个超时属性是一个很好的开端。
在 wsgi.py 中,我们设置了一个全局超时变量,如下程序所示:
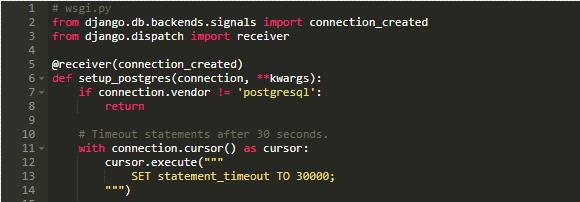
为什么要使用 wsgi.py 呢? 因为这样一来,它只会影响工作进程,而不会进程之外的查询与 cron 等任务。
希望你使用的是持久数据库链接, 这样一来,每个链接的设置就不会增加额外的系统开销。
我们也可以在用户这一级上设置超时:

额外提一点: 网络也是一大耗时的地方,所以当你调用远程服务器的时候,记得设置超时提醒:

5. 限制
与上一条在边缘情况设置超时相似,我们在某些情况下需要设置限制。有时候,我们想让用户产生报表,然后将其倒入到电子表格中。而在所有的的产品中,这些行为通常被认为是异常行为。
有时会遇到一个用户想要获取从一大早开始的所有销售数据,这种情况是很常见的。同样常见的情况是,当第一次查询正在处理且卡顿时,用户经常会打开另一个窗口,重复进行查询请求。
这就是限制的原因
下面,让我们设置一个限制,用于限制一个查询请求的返回结果不超过 100 行数据。

bad example 是一个反面例子。在其的代码中,你已经将所有查询的结果取出来并存进了内存,但是你却只显示了 100 行数据。 也许你应该参考一下 good example 中代码。在此代码中, Django 使用 SQL 中的限制语句,从而保证了只提取 100 行数据。
现在我们可以安心的说:我们添加了限制要求,用户行为在计划当中,一切尽在掌握。但我们仍旧有一个问题:用户想要的是所有的销售数据,但是我们只给了他 100 行数据,他就会认为数据库中一共就只有 100 行数据,这是不对的想法。
和严格返回前 100 行数据不同,当我们的数据查超过 100 行数据的时候,我们会抛出一个异常:

上面的代码能够正常使用,但是其中也加入了其他的查询代码。我们是否能够做的更加漂亮呢? 我觉得应该是可以的:

可以看出了,我们截取的不是 100 行数据,而是 101 行数据。如果 101 行数据存在,我们就可以确信数据库中的数据大于 100 行。话句话说,只有我们能够获取到 LIMIT+1 行数据时,我们就可以确定,数据库中的函数行数大于 LIMIT 行。记住 LIMIT+1 这个小窍门,有时候还挺有用的。
6. 选择并更新时出现的问题
这是一个挺难得问题。由于数据的锁机制, 我们过去经常会在半夜的时候得到交易超时错误。我们的代码中,交易操作代码的常见模式如下:
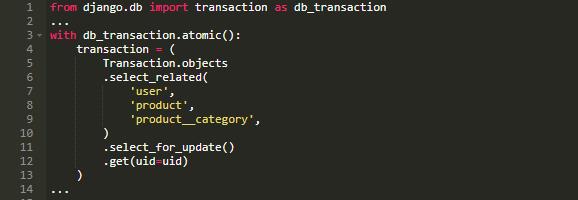
因为交易的操作经常会涉及一些用户和产品的属性,所以我们经常会使用 select_realted 语句来强制关联并保存一些查询语句。
更新一个交易就会涉及到获取锁的问题,从而确保此交易目前没有被别的其他程序操作。
现在你是否看到了问题的关键呢? 没有? 我们也没有。
在晚上的时候,我们会运行一些 ETL(Extract, Transform, Load)进程来维护产品与用户表格。这些 ETL 进程会对表格进行更新和插入操作,所以他们也会获取到使用表格的锁。
现在,你知道问题出现在哪里了吧? 当需要执行 select_realted 语句中的 select_for_update 语句时,Django 需要去获取其所查询的所有表格的锁。
我们用来实现交易的代码也会尝试去取的交易表格和 用户、产品、类别的表格的锁。半夜的时候,一旦 ETL 进程获取到了最后三个表格的锁,将其锁定,交易就会失败。
现在我们对问题的由来已经有了深入的了解,那么接下来的问题就是寻找方法来锁定唯一必要的表格——交易表格。幸运的是,在 Django 2.0 中, select_for_update 语句中引入了一个新的参数。
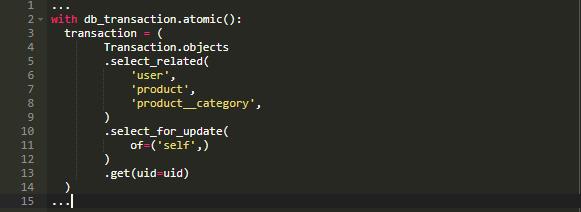
可以看到,在 select_for_update 语句中,引入了 of 参数。使用 of 参数,我们可以指定想要锁住哪些表格。self 是一个特殊的关键字,表示我们想要锁住我们正在使用的模型,在此种情况下,就是指交易表。
现在,这些功能仅限于 PostgreSQL 和 Oracle 使用。
7. 外键索引 FK indexes
当我们创建一个模型时, Django 会为所有的外键创建一个 B-tree 索引,B-tree 索引的开销会很大,而且有些时候根本没有必要。
典型的例子就是 M2M 关系模型,即 多对多关系模型:

在上面的模型中, Django 会在后台创建两个索引,一个针对用户,一个针对群组。 在 M2M 模型中,另一个常见的模式就是使用两个字段来作为唯一的外键。在这种情况下,一个用户只能是一个群组的成员:
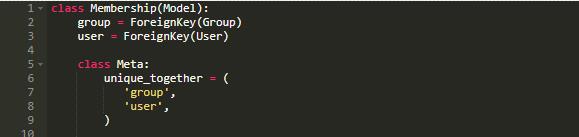
这个 unique_together 将会在两个字段上创建一个索引,这样一来,我们的模型就会拥有两个字段,三个索引。
由于我们使用这个模型的应用场景问题,很多时候,我们可以忽略这两个外键而单单使用这个唯一约束的外键 unique_together:
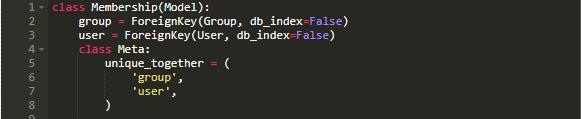
删除冗余索引将使插入和更新速度更快,此外,也会使我们的数据库现在变得更轻,这总归算是一件好事。
8. 组合索引中列的顺序
具有多个列的索引成为组合索引。在 B-tree 组合索引中,第一列使用树结构索引。在第一层的树叶中我们为第二层创建一个新的树结构,以此类推。
索引中列的顺序非常重要。按照之前所说的例子,我们首先会得到一个群组的树,对于每一个群组,会创建一个针对用户的树。
B-tree 组合索引的的经验法则是让二级索引的值尽可能的小。换句话说就是值越多的列排在第一位。
在的我们例子中,可以认为用户的数量大于群组的数量,所以将用户列排在首位,这样会使得基于群组的第二级索引更小。
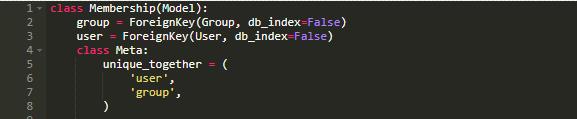
但这只是一个经验法则,对此我们应该持有怀疑的态度。最终的索引应该根据具体问题具体分析。此处主要想说的是,我们要注意到隐式索引以及组合索引中列顺序的重要性。
9. BRIN 索引(Block Range INdexes)
B-tree 索引结构像一颗树结构。对于随机访问而言,查找单个值的成本是树的高度加一。 这使得 B-tree 索引很适合那些唯一约束和某些范围查找。
B-tree 索引的缺点在于树的大小,B-tree 可能变得非常的大。
通常人们可能认为已经别无他法,但是数据库为某些特定的情况提供了其他类型的索引。
从 Django 1.11 开始,在创建模型建立索引的时候,提供了一个 Meta 参数,这给了我们提供了一个探索其他类型索引的机会。
PostgreSQL 有一个非常有用的索引类型,叫做 BRIN(Block Range Index)。在某些情况下, BRIN 索引要比 B-tree 索引更加有效。
下面的一段内容参考自官方文档:
BRIN 被设计用于处理非常大的表格,其中某些列与他们在表格内的物理位置有一些自相关性。
要理解这句话的含义,我们就应该首先了解 BRIN 索引的原理。顾名思义,BRIN 索引会在表格的相邻的块区域之间建立一个小型的索引。这个索引很小,它可以确定某个值不在这个块索引范围之内或者这个值可能在这个块索引范围之内。
下面我们简单的举一个例子来说明 BRIN 索引的工作原理以帮助我们理解。
可以看到,这些数排成一列,自成一块。然后我们每三个相邻的块组成一个区域。对于每一个区域保存其中的最大值与最小值。
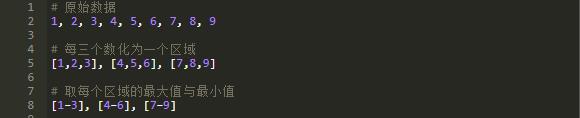
有了这些索引,让我们先尝试一下寻找数值 5 的位置:
- [1-3] 5 肯定不包含其中
- [4-6] 5 可能包含其中
- [7-9] 5 肯定不包含其中
可以看到,使用这个索引,我们可以将我们的查找范围缩小到 [4-6] 这个区域之间。
下面我们另举一个例子,其中,元素的位置随机排列,分块后的区域如图所示,然后取每个区域的最大值与最小值。

同样,我们尝试寻找 5 所在的位置:
- [2-9] 5 可能包含其中
- [1-7] 5 可能包含其中
- [3-8] 5 可能包含其中
可以看出来,这样的索引不但毫无用处,因为它并不能帮我缩小查找范围,而且还使得我们查找了更多的数据,因为我们需要为整个表格建立索引。
让我们重温一下官方文档中的描述:
... 其中某些列与他们在表格内的物理位置有一些自相关性
这是 BRIN 索引的关键,为了更好的利用这一点,我们希望,每列中的值都基本上已经排序好了或者其在磁盘的位置都是聚类好的。
现在回到 Django,我们有哪些常被索引的字段,并且最有可能在磁盘上自然排好序呢?没错,需要的是 auto_now_add 参数。使用
在 Django 模型中一个非常常见的模式如下:
当我们将 auto_now_add 参数设置为 True 时,Django 将自动使用当前行创建时的时间填充该值。created 字段也是查询时的一个非常好的候选字段,所以也经常被索引。
下面我们为 created 字段添加 BRIN 索引:
为了了解索引大小的差异,我创建了一个约有两百万行的表,并在磁盘上按照日期字段自然排列:
- B-tree 索引的大小为 37 MB
- BRIN 索引的大小为 49 KB
是的, 你没有看错。
当我们创建一个索引的时候,除了索引的大小外,我们还需要考虑其他很多因素。但是,在 Django 1.11 所支持的索引中,我么可以非常容易的将新型的索引整合到我们的应用中,使得我们的程序更加轻便且快速。
英文原文:https://ogmcsrgk5.qnssl.com/vcdn/1/优质文章长图/9-django-tips-for-working-with-databases-beba787ed7d3.png
译者:无
以上是关于Django 与数据库交互中的九个知识点的主要内容,如果未能解决你的问题,请参考以下文章