为Django开发者介绍SQLAIchemy ORM
Posted Python程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为Django开发者介绍SQLAIchemy ORM相关的知识,希望对你有一定的参考价值。
我经常在工作和个人项目中使用Django。但是在最近的工作项目中,我有机会使用Flask和SQLAlchemy。所以我必须学点新东西。
Flask很简单,因为它是一个微框架,里面没有很多东西。然而,理解SQLAlchemy以及如何使用它比我预期的要困难得多。
在本文中,我试图通过一些示例来展示Django ORM和SQLAlchemy之间的主要区别,这些示例演示了如何在Django中执行某些操作,以及如何在SQLAlchemy中执行相同的操作。如果您出于任何原因试图切换到SQLAlchemy,我希望它对您有用。
在深入讨论示例和Django ORM与SQLAlchemy之间的区别之前,让我们先从理解事务开始,因为如果您想使用SQLAlchemy编写任何内容,那么事务是一个非常重要的概念。
事务
将事务视为确保多个数据库操作(插入、删除、……)作为一个组,要么一起成功,要么一起失败的一种方法。
启动事务时,我们记录数据库的当前状态,然后执行SQL语句。如果所有这些语句都成功,则提交事务。提交之后,所有更改都将持久化到数据库中,并对其他事务可见。
但是,如果一个或多个语句失败,我们将捕获异常并回滚任何成功的语句。
Django和SQLAlchemy中的事务
我们在Django和SQLAlchemy中处理事务的方式是不同的。
在Django中,我们很少考虑事务。因为Django的默认行为是在自动提交模式下运行,这意味着每个SQL语句都被包装到它自己的事务中,这个事务将根据SQL语句成功与否自动提交或回滚。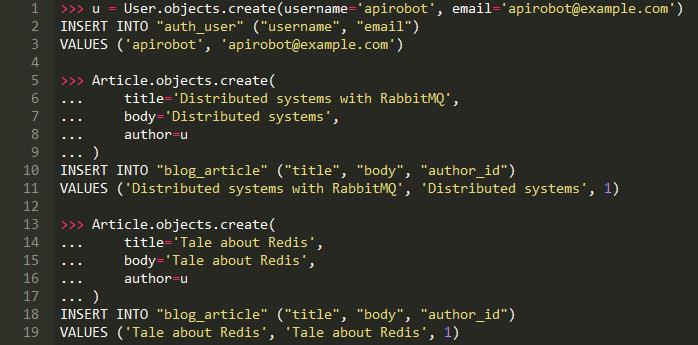
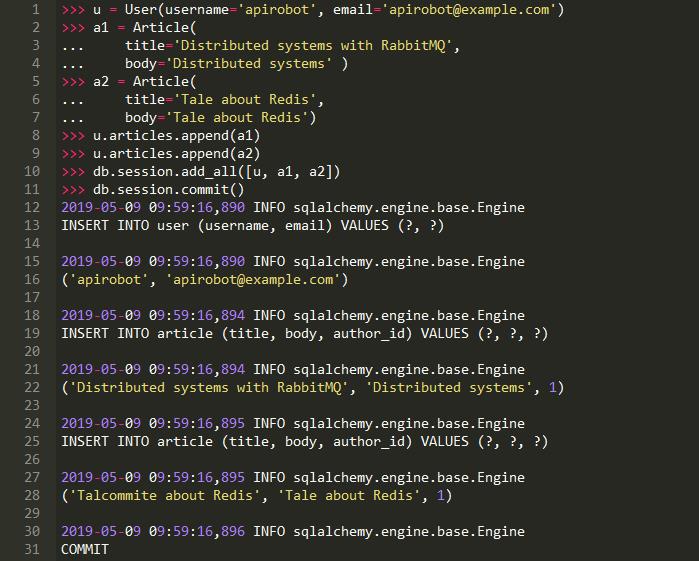
但在SQLAlchemy中,我们有Session对象。会话是SQLAlchemy与数据库交互的方式。它允许您累积多个更改,然后发出commit命令,该命令将自动将所有更改作为一个单元写入数据库。这种模式也称为工作单元:
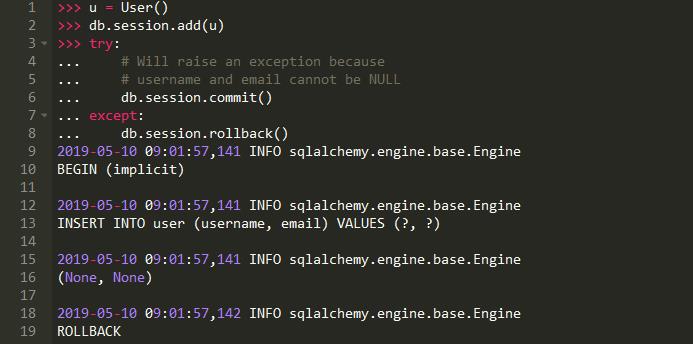
当提交引发一个异常,你想要处理它,你应该手动回滚事务,这样你的应用程序才能继续正常运行:
Django和SQLAlchemy中的原子性
现在,当您了解了Django和SQLAlchemy处理事务的区别之后,您应该会看到这两种方法的优缺点。
在自动提交模式下运行的优点是,它使得使用这个ORM更容易理解和编写代码。缺点是,如果你有多个查询,其中一个成功,另一个失败,那么你的数据库就有损坏的风险:

解决风险的方法是对数据库原子进行查询。原子性意味着您在一个事务中所做的事情作为一个单元进行或失败。如果代码块成功完成,则将更改提交给数据库。如果出现异常,则回滚更改。
这就是session在SQLAlchemy中的作用。在Django中,我们可以使用原子函数实现原子性:
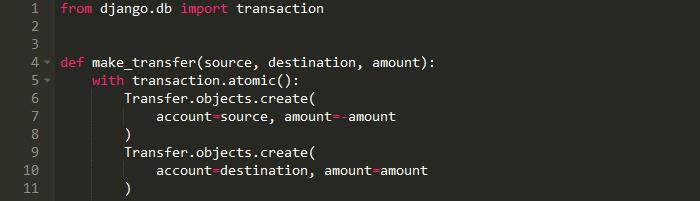
这两种Transfer要么都将被添加到数据库中,要么都不添加。
Django和SQLAlchemy中的模型
在Django和SQLAlchemy中定义模型时,您将立即看到的主要区别是,在SQLAlchemy中必须显式地定义模型。但是在Django中,很多事情都是在底层完成的。
例如,让我们看看如何在Django和SQLAlchemy中定义具有不同关系的模型。
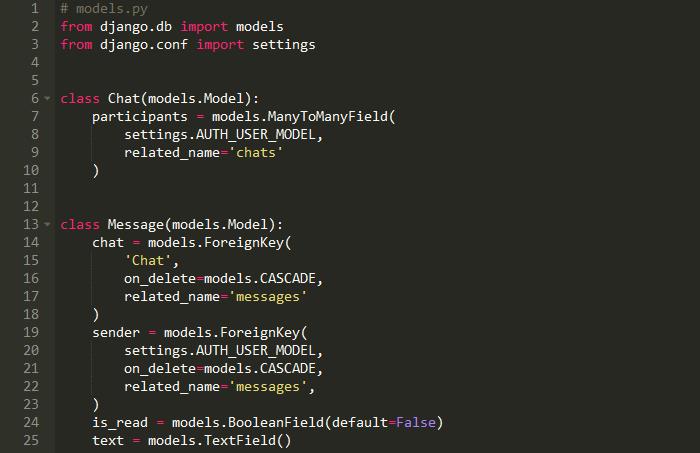
在Django中:
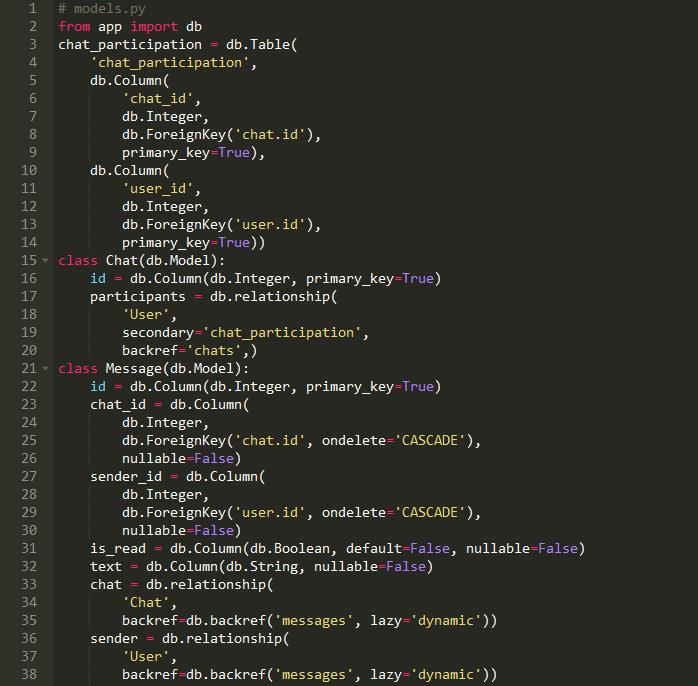
同样的事情在SQLAlchemy:
让我们来讨论一下主要的区别。
Django的模型。默认情况下,Model类创建一个自动递增的整数主键。在SQLAlchemy我们必须明确定义:

另一个区别是,在SQLAlchemy中,我们必须自己对关系建模,比如一对多、多对多和一对一。在Django中更简单,因为它为您处理关系。
例如,如果我们想在SQLAlchemy中创建一对多的关系,我们应该首先定义一个列:

然后声明两个模型之间的关系:

注意,当我们定义一个外键时,我们指向聊天表的id列。但是当我们定义模型之间的关系时,我们不是指向表,而是指向Chat模型。
backref参数自动声明反向关系。lazy= ' dynamic '创建了一个动态关系,这意味着当我们访问chat时。消息,SQLAlchemy将返回一个查询对象,我们可以进一步过滤:

如果我们不指定lazy参数,默认值将是' select '。它的工作方式不同。当我们首次使用chat.messages时,SQLAlchemy会向数据库发送一个查询,获取所有相关的消息,并返回一个列表:

Django和SQLAlchemy中的查询
当我们想要在Django中过滤查询时,我们使用的关键字参数的格式是column=value或column_operation =value:
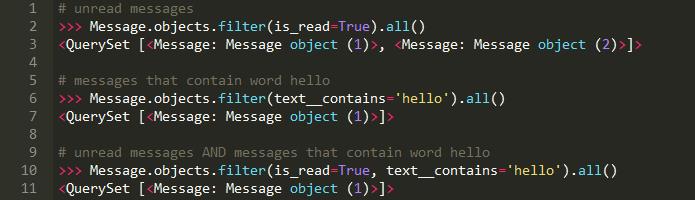
在SQLAlchemy中,我们使用模型表达式进行过滤:
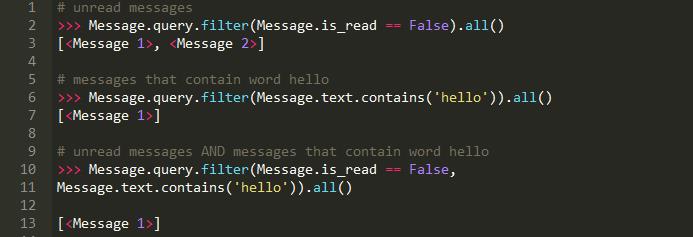
说到连接,在Django中更简单,因为它为我们处理连接:

在SQLAlchemy我们必须明确:

SQLAlchemy会自动尝试查找要连接的内容,但是我们可以明确地将其指定为要连接的第二个参数:

大多数情况下,它在不指定第二个参数的情况下也能工作。但是,如果模型之间有很多关系,有时它会以您不希望的方式执行自动连接。所以要小心。
现在让我们看看如何重用查询。例如,如果我们需要获得有未读消息的对话框(与2个参与者的聊天),该怎么办?或者我们想要检查一个特定的聊天是否是一个对话框,以及它是否有未读的消息。我们不想在不同的地方重复粘贴代码。记得擦干(不要重复)。
在Django中,我们可以为聊天模型创建一个自定义的QuerySet和属性:
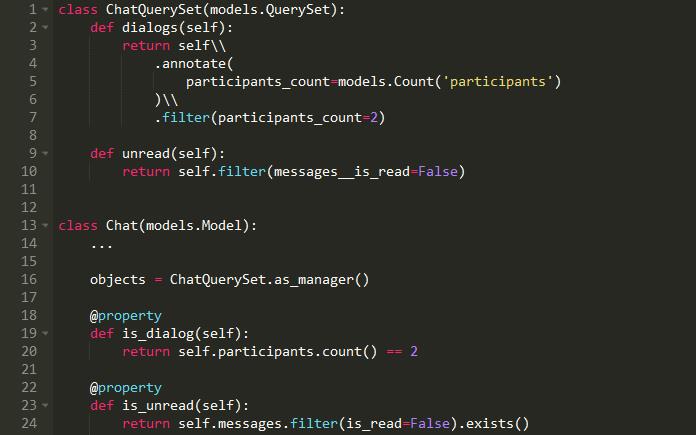
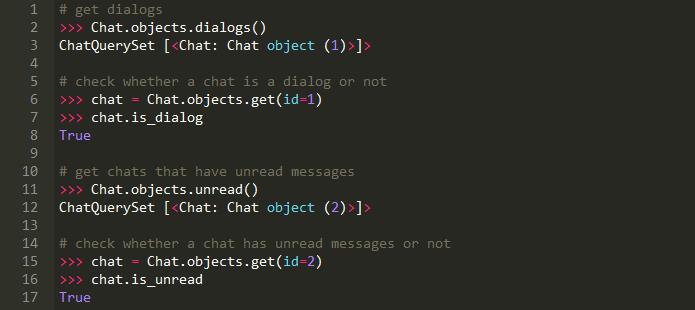
如何使用:
在SQLAlchemy中,我们可以使用混合属性或方法使代码可重用:
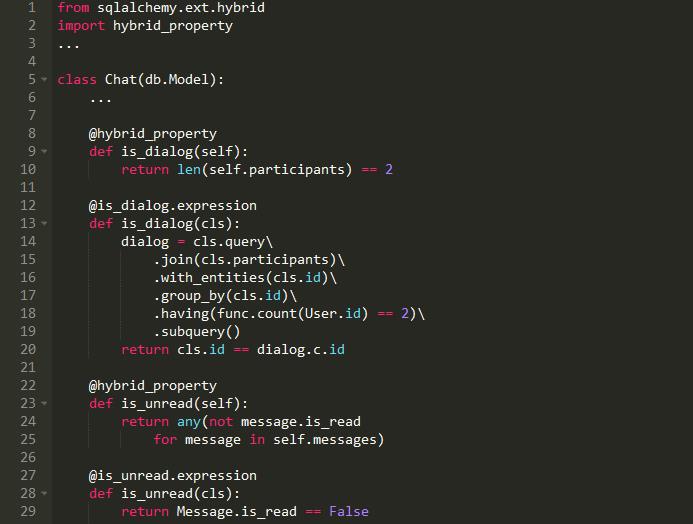
混合属性意味着该属性既可以在类级使用,也可以在实例级使用:
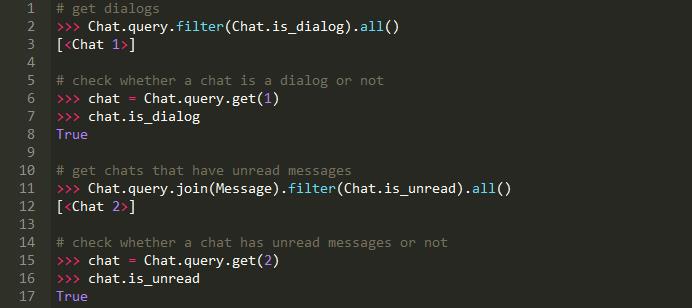
混合方法也可以在实例级和类级使用。不同之处在于,如果需要,我们可以将参数传递给方法。
N + 1问题
让我们来讨论一个无论使用Django还是Flask都会遇到的问题:假设您需要从数据库中提取每个聊天的消息,然后显示消息文本和关于消息发送者的信息:

为了显示所有这些信息,我们将向数据库发送多少个查询?由于Django比较懒,所以在编写chat .object .all()时,它只将聊天信息提取到内存中。它不提取关于消息的信息,当然,也不提取关于消息发送者的信息。
因此,如果我们有2个聊天,每个聊天有10条消息,那么它将需要23个查询。首先,我们从数据库中提取所有聊天记录(1 db请求)。对于每个聊天,我们提取所有消息(另一个2 db请求)。最后,对于每条消息,我们提取其发送者的信息(2个聊天* 10条消息)。1 + 2 + 2 * 10 = 23
我们可以做的是使用prefetch_related函数将需要的信息预加载到内存中:
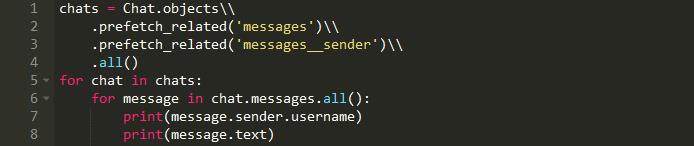
我们总共只有3个查询。一个用于聊天,一个用于消息,一个用于用户(发送者)。
我们可以在SQLAlchemy做类似的事情:
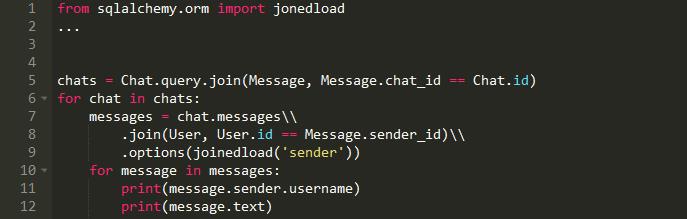
我们使用joinedload将sender预加载到内存中。正如您所看到的,我们没有预先加载聊天消息。问题是您不能预加载lazy= ' dynamic '关系,因为它产生的是查询,而不是集合(列表)。因此,在为您的模型定义和使用lazy= ' dynamic '关系时要小心,因为它会导致对数据库的大量查询。然而,没有什么可以阻止你定义两个关系到同一个模型:
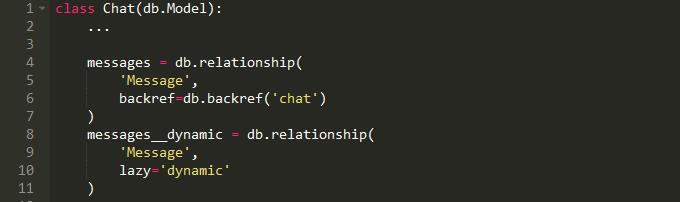
我建议您使用默认情况下返回列表的关系,但是当您确实需要动态关系来过滤嵌套数据时,您可以轻松地将其添加到模型中。
另外,请记住,即使不使用动态关系,您也可以过滤嵌套的关系。contains_eager能帮你做到:
首先,我们加载具有未读消息的聊天。然后我们预加载聊天-信息的关系。预加载后,此关系将生成未读消息列表。
结论
我们已经了解了最流行的Python ORM: SQLAlchemy和Django ORM。从我的经验来看,Django ORM更容易学习和使用,但是SQLAlchemy为您提供了更大的灵活性,而且可能更适合大型应用程序。
如果您是初学者,并且正在尝试为下一个项目Django或Flask + SQLAlchemy选择使用什么,我强烈建议您继续使用Django。最初,Flask可能看起来很简单,但是当您开始构建能够解决实际问题的应用程序时,使用起来就比Django更有挑战性了。此外,Django的生态系统更大。它有更多的开源库和教程。
如果您不是初学者,并且正在尝试构建微服务,那么Flask + SQLAlchemy可能是更好的选择。但如果你已经到了那一步,你自己应该就知道如何对框架进行取舍了。
英文原文:https://apirobot.me/posts/introduction-to-sqlalchemy-orm-for-django-developers
译者: Yang
以上是关于为Django开发者介绍SQLAIchemy ORM的主要内容,如果未能解决你的问题,请参考以下文章