领域驱动设计示例
Posted 技术琐话
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了领域驱动设计示例相关的知识,希望对你有一定的参考价值。
我过去看过很多IT项目。其中一些设计非常好,同时也有一些非常糟糕。基于这些经验,我想写一些示例项目,我还想展示如何使用UML建模示例项目,以及如果我们将领域驱动设计原则应用于模型会发生什么。
在开始讲述本文之前,您应该阅读Eric Evans撰写的“Domain-driven Design”和Vaughn Vernon的“实现领域驱动设计”。 文中例子的大部分是基于他们的工作,如果你想深入研究领域驱动的设计,他们的书是必读的。
需求分析
一家公司提供时间出租服务。他们有一些员工,还有很多自由职业者作为分包商存在。目前,他们使用Excel工作表来管理他们的客户,自由职业者,时间表等。Excel解决方案无法很好地进行扩展。它无法应对多用户使用的场景,也不提供安全和审计日志。因此他们决定构建一个新的基于Web的解决方案。以下是核心要求:
搜索自由职业者分类的功能
用于存储联系自由职业者的不同渠道的解决方案
搜索项目分类的功能
搜索客户分类的功能
维护合同中自由职业者的时间表
基于这些要求,开发团队决定使用UML对所有内容进行建模,以全面了解新的解决方案。现在让我们看看他们做了什么。
架构总览
以下是他们第一次设计的情况:
这很简单。有客户,自由职业者,项目和时间表。还有一种基于角色安全的用户管理。但是等等,这里有些不对劲。 里头有一些隐藏的设计缺陷。你看得到他们吗? 缺陷如下:
这是一个非常大的对象图。如果他们在这里不使用Hibernate / JPA延迟加载,那么在重负载下它肯定会耗尽内存
为什么用户和角色之间的关联是双向的?`
Freelancer类包含Projects列表。这也意味着在不修改Freelancer对象的情况下无法添加项目。这可能会导致重负载下的事务失败,因为可能有多个用户正在为同一客户添加项目。
ContactInformation是什么意思? 需求规定的“沟通渠道”。两者是一个概念?
整个模型似乎更像是一种全关系图而不是软件模型。另外,这是商业逻辑吗?该团队希望围绕模型创建一些商业服务来存储和检索数据,实体只是由JPA管理的POJO。
当前解决方案有很大的代码气味,一个贫血的领域模型。团队也会认识到这一点。但是什么可以解决方案呢?好吧,一位资深团队成员建议使用域驱动设计原则来为解决方案建模。好的,现在让我们看看DDD如何改进设计。
DDD的方式
在我们深入研究领域驱动设计之前,我们应该先谈谈DDD背后的原理。
DDD背后的一个原则是通过使用相同的语言来创建相同的理解来弥合领域专家和开发人员之间的差距。另一个原则是通过应用面向对象的设计和设计模式来降低复杂性,以避免重新发明轮子。
但什么是域?域是一个“知识领域”,例如公司运营的业务。域也称为“问题空间”,因此我们必须设计解决方案的问题。
好的,让我们来看看要求。我们可以认为有一个“时间租赁”领域,这是完全正确的。但是,如果我们深入了解Domain,我们会看到一些名为“Subdomain”的东西。以下子域名可能是包括以下内容:
Identity and Access Management Subdomain
Freelancer Management Subdomain
Customer Management Subdomain
Project Management Subdomain
我们可以把大问题分成小问题。这可以帮助我们设计出更好的解决方案。
分离的域可以很容易地可视化。在DDD术语中,这称为上下文映射,它是任何进一步建模的起点。
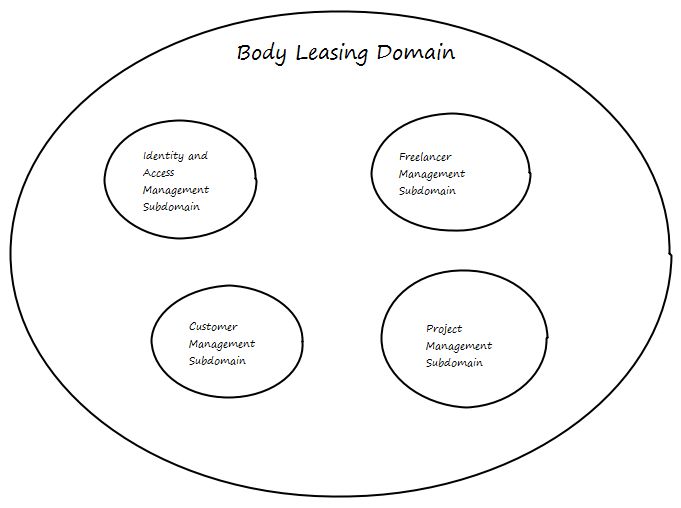
现在我们需要将子问题空间与我们的解决方案设计对齐,我们需要形成一个解决方案空间。DDD术语中的解决方案空间也称为有界上下文,并且最好将一个问题空间/子域与一个解空间/有界上下文对齐。
构建模块
领域驱动设计的构建模块分为战术和战略模式。我写了一篇关于DDD构建块的文章,所以如果你想深入了解,请访问这篇文章。
请注意,以下架构模式和类图不依赖于技术。该解决方案可以使用Java SE / EE,C#甚至javascript实现。无关紧要,我们可以使用每种目标技术存档相同的好处。
新的架构总览
让我们看下新的架构
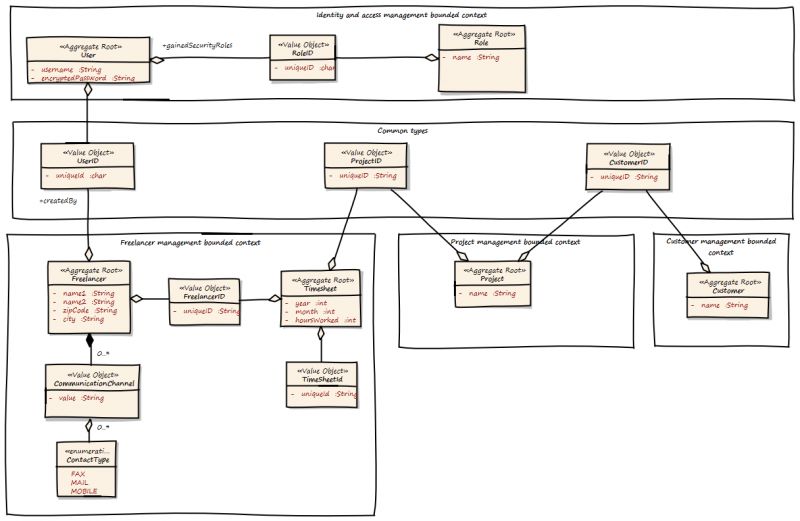
好的,这里发生了什么?现在每个已识别的子域都有有界上下文。有界上下文是孤立的,彼此一无所知。它们仅由一组常见类型粘合在一起,如UserId,ProjectId和CustomerId。在DDD中,这组常见类型称为“共享内核”。我们还可以看到什么是“核心领域”的一部分,什么不是。如果有界上下文是我们试图解决的问题的一部分,并且不能被另一个系统替换,那么它就是“核心域”的一部分。如果它可以被另一个系统替换,那么它就是“通用子域”。“身份和访问管理”上下文是“通用子域”,因为它可以由现有的IAM解决方案替换,例如Active Directory或其他。
我们将一组战术和战略模式应用于模型。这些模式有助于我们构建更好的模型,提高容错能力并提高可维护性。
在每个有界上下文中都有聚合和值对象。聚合是对象层次结构,但只能从聚合外部访问层次结构的根。聚合处理业务常量。对对象树的每次访问都必须通过Aggregate,而不是通过其中的一个元素。这大大增加了封装性。
Aggregates和Entites是我们模型中具有唯一ID的东西。值对象不是事物,它们是值或度量,如UserId。值对象被设计为不可变的,它们不能改变它们的状态。每个状态更改方法都返回值Object的新实例。这有助于我们消除不必要的副作用。
设计行为
让我们设计一些行为,“Freelancer迁移到新位置”用例。在没有DDD的情况下,我们可以创建一个简单的POJO,如下所示:
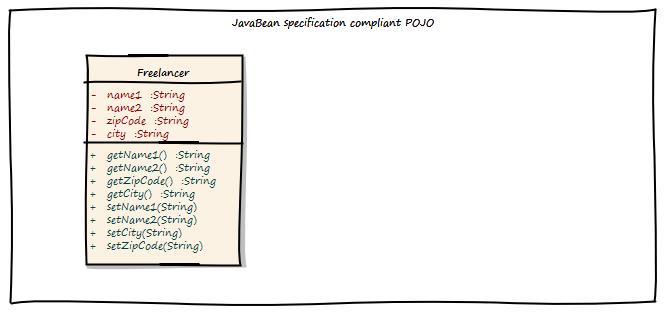
通过应用域驱动设计,我们得到以下结果:
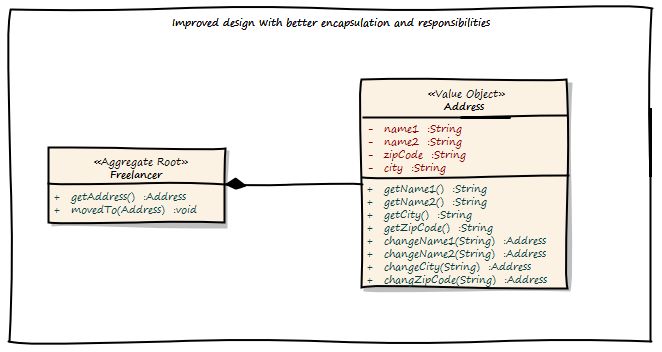
完整的用例和持久性
好的,我们继续模仿“自由职业者迁移到新位置”的用例。首先,我们需要为Freelancer Aggregate提供一种存储空间。DDD将这样的存储称为存储库。使用存储库,我们可以按名称搜索Freelancer,通过Id加载现有的Freelancer,从存储中删除它或向存储添加新的Freelancer。根据经验,每种类型的聚合都应该有一个存储库。请注意,存储库是业务术语中描述的接口。我们将在下一章讨论实现。
下图显示了建模的用例。你会看到一些新的工件。首先是用户界面,我们的域模型的客户端。客户端可以是一切,从JSF 2.0前端到SOAP Web服务或REST资源。所以请以一般方式考虑客户。客户端向ApplicationService发送命令。ApplicationService将命令转换为域模型用例调用。因此,FreelancerApplicationService将从FreelancerRepository加载Freelancer Aggregate,并在Freelancer Aggregate上调用moveTo()操作。FreelancerApplicationService也构成了事务边界。每次调用都会导致新的事务。基于角色的安全性也可以使用FreelancerApplicationService实现。将事务控制保留在域模型之外始终是一个很好的选择。事务控制更多是技术问题,而不是业务问题,因此不应在域模型中实现。
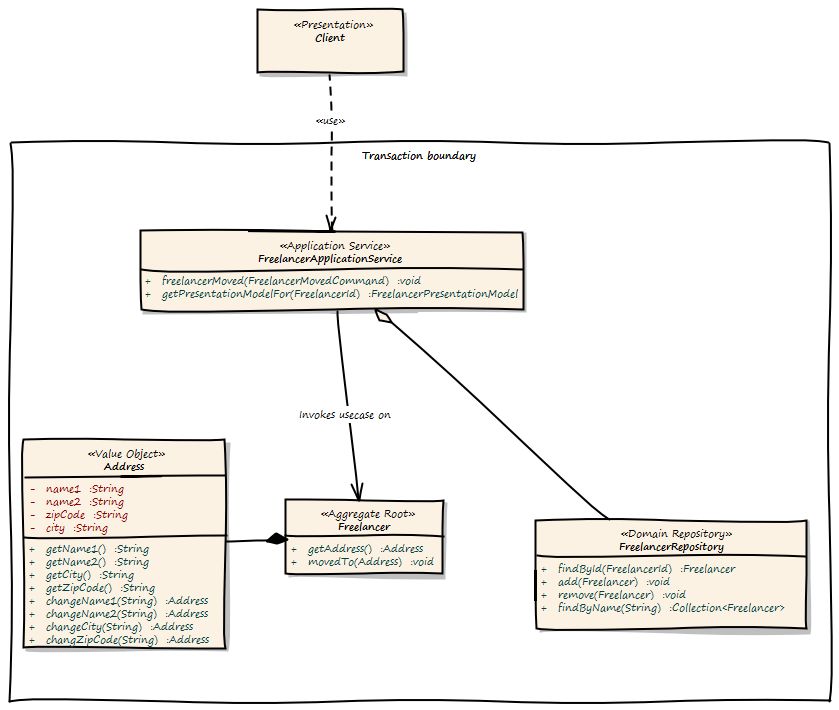
应用架构
好的,现在让我们来看看应用程序架构。对于每个有界上下文,应该有一个单独的部署单元。这可以是Java WAR文件或EJB JAR。这取决于具体的技术实现。我们将有界上下文设计为彼此独立,并且此设计目标也应该反映在独立的部署单元中。
每个部署单元包含以下部分:
领域层
基础实施层
应用层
域层包含我们之前在此示例中建模的基础架构独立域逻辑。基础实施层提供了与技术相关的工件,例如基于Hibernate的FreelancerRepository实现。应用层充当具有集成事务控制的业务逻辑的网关。
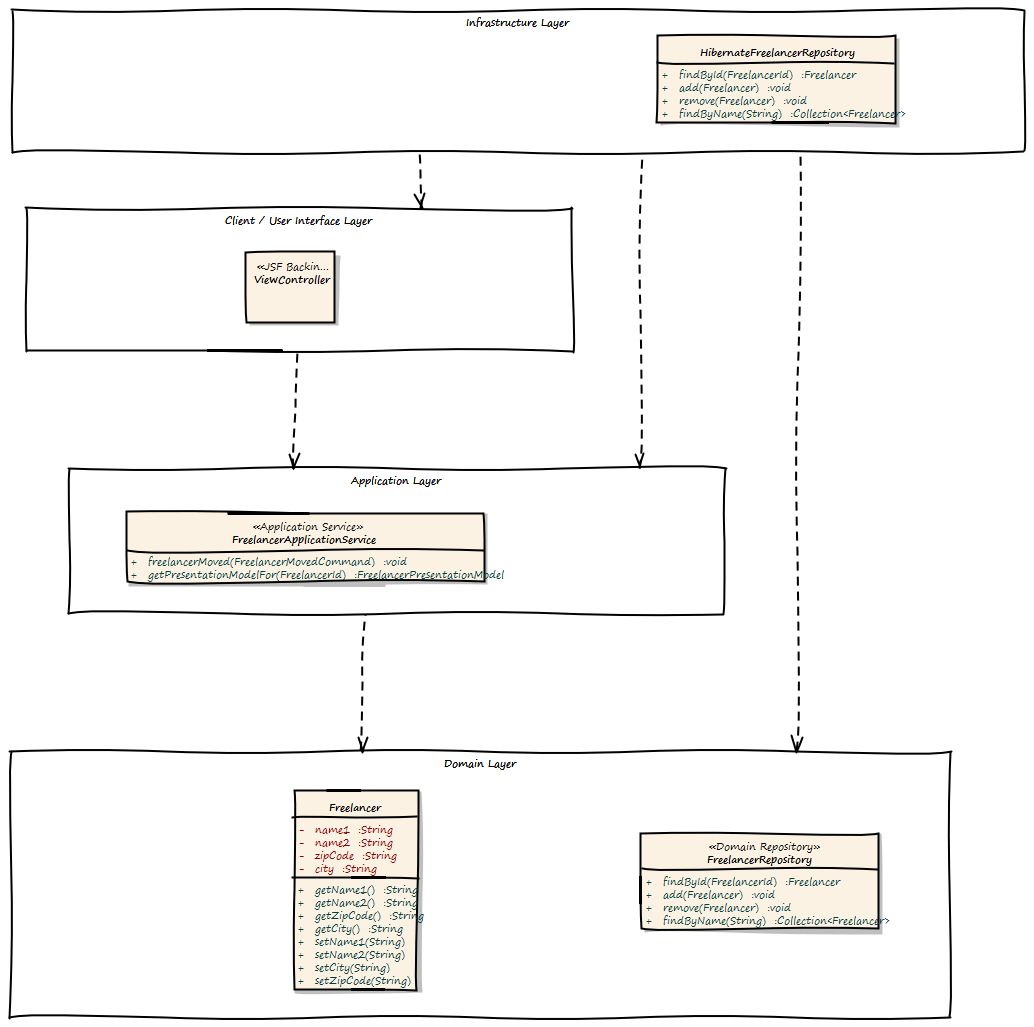
使用这种架构,我们的业务逻辑的域层不依赖于任何东西。我们可以将Repository实现从Hibernate更改为JPA,甚至可以将NoSQL更改为Riak或MongoDB,而不会影响任何业务逻辑。
领域层
领域层包含真实的业务逻辑,但不包含任何基础结构特定的代码。基础架构特定的实现由基础架构层提供。域模型的设计应遵循CQS(命令 - 查询 - 分离)原则的描述。可以有查询方法只返回数据而不影响状态,并且有命令方法,它们影响状态但不返回任何内容。
应用层
应用层从用户界面层获取命令,并将这些命令转换为域层上的用例调用。应用层还为业务操作提供事务控制。应用程序层负责通过Mediator或Data Transformer模式将聚合数据转换为客户特定的表示模型。
基础实施层
基础实施层为所有其他层提供基础架构相关部分,如Hibernate或JPA支持的实现。聚合数据可以存储在像Oracle或mysql这样的RDMBS中,也可以存储为基于键值或基于文档的NoSQL引擎的XML / JSON甚至Google ProtocolBuffers序列化对象。这取决于您,只要存储提供事务控制并保证一致性。基础设施可以最好地描述为“域模型周围的一切”,因此,如果我们与其他系统交互,则数据库,文件系统资源甚至Web服务消费者。
客户端/用户界面层
客户端层使用应用程序服务并在这些服务上调用业务逻辑。每次调用都是一个新事务。
客户端层几乎可以是任何东西,从作为视图控制器的JSF 2.0 Backing Bean到SOAP Web服务端点或RESTful Web资源。甚至可以使用Swing,AWT或OpenDolphin / JavaFX来创建用户界面。
请查看UI级别的服务集成与服务器端包含(SSI)以获得想法。
上下文集成
现在我想写一下Context Integration。这是怎么回事?考虑身体租赁领域的以下要求:
只有在未分配项目的情况下才能删除客户
输入时间表后,需要向客户收费
同步集成
让我们从第一个开始吧。在这种情况下,客户管理有界上下文需要在删除客户之前检查是否有为给定客户注册的项目。这需要一种两种有界上下文的同步积分。
有很多机会。首先,我们希望保持上下文彼此独立。那我们该怎么处理呢?这是客户有界上下文与项目管理有界上下文交互的设计:
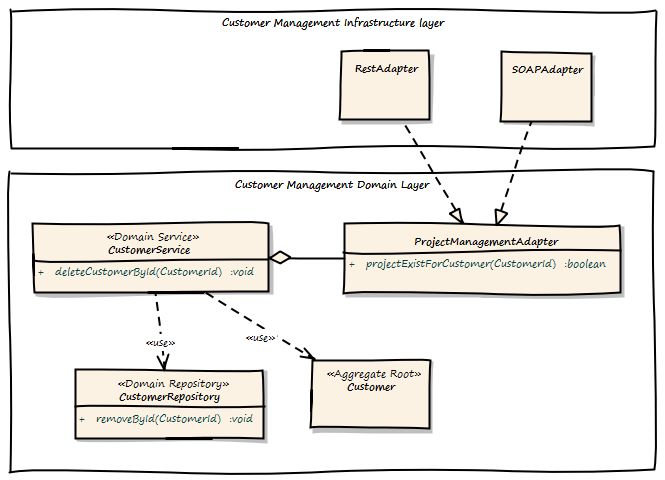
有一个新术语:领域服务。什么是领域服务?域服务实现了Entity,Aggregate或ValueObject无法实现的业务逻辑,因为它不属于那里。例如,如果业务逻辑调用包括跨多个域对象的操作,或者在这种情况下与另一个有界上下文集成。
ApplicationService调用CustomerService的deleteCustomerById方法。如果给定CustomerId存在项目,CustomerService将通过调用customerExists()来询问ProjectManagementAdapter。仅当它返回false时,才会从CustomerRepository中删除Customer。
ProjectManagementAdapter有两种实现方式,一种是SOAP和一种基于REST的实现。我们可以使用SOAP来使用XML编组调用完整的Web服务操作并使用完整的JAX-WS堆栈,或者我们可以使用REST并调用http://example.com/customers/customerId/projects并获取404(不是找到)或20x(确定)HTTP响应代码。这取决于您,但REST可以不那么复杂,更容易集成,也可以更好地扩展。我们也可以从REST开始,如果需要,可以切换到SOAP。在不影响域层的情况下更改实现非常容易,我们只使用适配器的另一种实现。
在Project Management Bounded Context端,有一个ApplicationWebService公开为REST资源或SOAP服务,实现了通信的服务器部分。此服务或资源委托给ProjectApplication Service,后者委托ProjectDomainService询问是否为给定的CustomerId注册了Project。
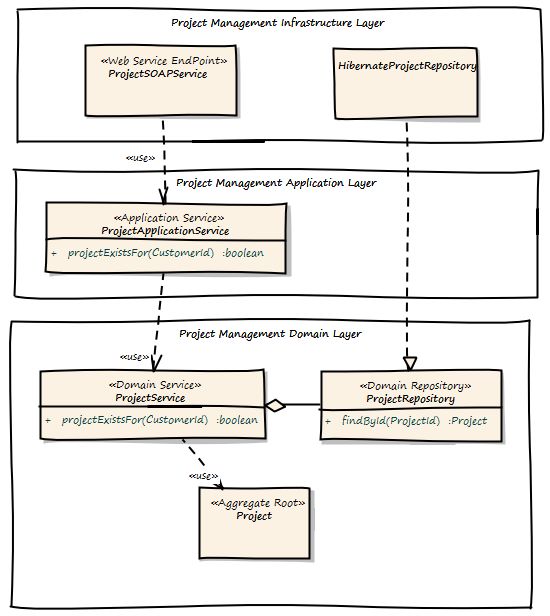
无论如何,我们必须处理交易边界。Web Service或REST资源调用不会触发开箱即用的事务,并且使用XA /两阶段提交会增加复杂性并降低可伸缩性。最好不要在物理上删除客户,而是将其标记为逻辑删除。在事务失败或并发问题的情况下,将客户恢复到其原始状态将很容易。
在这里,您还可以看到基础架构层位于所有其他层之上的原因。它必须能够根据以下层中定义的接口委托给它或实现特定于技术的工件。
一个同步例子
好的,现在我们继续一个更复杂的例子。考虑一下要求,即一旦输入时间表,就需要向客户收费。
这是一个非常有趣的。这很有趣,因为它不需要同步调用。账单可以及时发送,也可以在几个小时后或月末与其他账单一起发送。或者可以通过客户的大客户经理或其他任何方式丰富账单,Freelancer管理上下文并不关心。
我们如何使用DDD模式对此进行建模?这里的关键是“一旦时间表是......”,这是我们域中的业务相关事件,这些事件可以建模为域事件!
创建域事件并将其转发到事件存储库并存储在那里以进行进一步处理。EventStore是Bounded Context Deployment Unit的一部分,在Store中存储Event是在ApplicationService管理的运行事务下完成的。在基础结构方面,有一个Timer将存储的事件转发到最终的消息传递基础结构,例如基于JMS或AMQP,甚至可以将REST资源的调用视为消息传递。
那么为什么我们需要本地EventStore呢?好吧,消息传递基础结构可能暂时不可用,但这不应该影响我们运行的Bounded Context。因此,当基础架构再次可用时,事件将排队并交付。如果我们将消息传递基础结构直接与Event生成器耦合,则生成器可能无法在发生基础结构错误时发送。即使我们使用消息传递,如果出现问题,这可能会对整个基础架构造成连锁反应,这也是我们使用消息传递的原因:系统解耦
以下是Freelancer Management Bounded Context的建模方式:
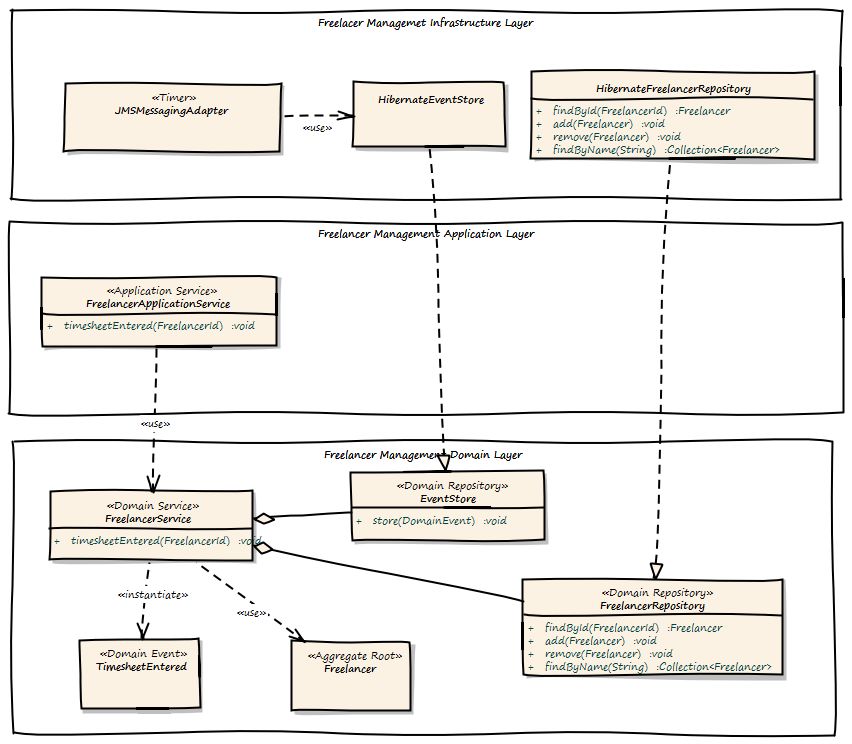
FreelancerService创建一个TimesheetEntered域事件并将其转发到EventStore,它基本上是另一个Repository。然后,JMSMessagingAdapter从EventStore获取挂起的事件,并尝试将它们转发到目标消息传递基础结构,直到传递成功。但是这种转发在另一个事务中处理,并且可以由例如计时器触发。
好的,客户管理上下文如何处理事件?建模如下:
同样,基础架构层必须位于所有其他层,因为它必须在上下文集成调用应用程序服务的情况下。
以下是JMSMessageReceiver位于基础结构层中的来源。MessageReceiver还负责重复数据删除。这可能发生在系统故障,已经发送事件被重新传递或其他错误的情况下。由于基础架构层位于应用层之上,因此它可以调用CustomerApplicationService,CustomerApplicationService本身调用CustomerService,后者实现业务逻辑以发送账单。
在此方案中,事务边界位于ApplicationService。我们可以争辩说JMSMessageReceiver可以调用CustomerService,并围绕JMS Transaction进行。这也是一个可行的解决方案。
棘手的部分是重复数据删除。如果发生基础设施故障或系统中断,可能会发生这种情况。通过为每个事件提供唯一ID,并跟踪已处理的ID,可以避免这种情况。
另一个棘手的部分是事件排序。这取决于消息传递基础结构。如果基础设施支持事件排序,一切都很好。如果没有,这必须由我们自己实施。无论如何,将事件设计为幂等操作是一种很好的做法。这意味着每个事件都可以多次处理,并且每次都具有相同的结果而没有不必要的副作用。
查询来自多个有界上下文或聚合的数据
有时我们需要收集分布在多个聚合甚至是有界上下文的数据。这可能是一项艰巨的任务。在一个有界上下文中,我们可以使用专门的数据库视图并使用Hibernate或JPA检索数据,但是将数据分布在多个有界上下文中可能会导致许多远程方法调用和其他问题;此解决方案可能无法很好地扩展我们还要考虑使用视图可能会破坏精心设计的Aggregate的业务不变性。这是我们真正需要照顾的问题!
现在,可能是什么解决方案?我们可以考虑CQRS或Command-Query Responsibility Segregation!基本上我们将模型划分为包含业务逻辑的命令模型和用于检索数据的查询模型。因此,对于此示例,命令模型将包含我们要查询的所有有界上下文,以及查询模型,该模型用于查询聚合数据(并且被优化以有效地查询数据)。使用域事件同步命令模型和查询模型!在命令模型中触发业务操作后,将由查询模型发出并处理域事件,并更新数据。
使用CQRS,我们可以设计高性能数据处理系统,并且与商业智能集成也不再是问题。想一想:查询模型基本上可以是数据仓库。
结束语
我非常喜欢Domain-driven Design背后的想法。使用这种技术,即使非常复杂的域逻辑也可以轻松地进行提取和建模。这可以带来更好的系统,改善的用户体验以及更可靠和可维护的解决方案。感谢Eric Evans和Vaughn Vernon!DDD /域驱动设计是面向对象的编程。
往期推荐:
技术琐话
以分布式设计、架构、体系思想为基础,兼论研发相关的点点滴滴,不限于代码、质量体系和研发管理。
以上是关于领域驱动设计示例的主要内容,如果未能解决你的问题,请参考以下文章