YARN & Mesos,论集群资源管理所面临的挑战
Posted Spark技术日报
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YARN & Mesos,论集群资源管理所面临的挑战相关的知识,希望对你有一定的参考价值。
在国内,大部分的Spark用户都是由Hadoop过渡而来,因此YARN也成了大多Spark应用的底层资源调度保障。而随着Spark应用的逐渐加深,各种问题也随之暴露出来,比如资源调度的粒度问题。为此,7月2日晚,在CSDN Spark高端微信群中,一场基于YARN和Mesos的讨论被拉开,主要参与分享的嘉宾包括TalkingData研发副总裁阎志涛,GrowingIO田毅,AdMaster技术副总裁卢亿雷,Spark Committer、Mesos/Hadoop Contributor夏俊鸾,下面一起回顾。
阎志涛——YARN和Hadoop捆绑以及资源分配粒度问题
这里好多老朋友了,这里主要说说Spark on YARN的实践挑战。Talking Data最初引入Spark是2013年,当时主要的考虑是提高机器学习效率,于是在Spark 0.8.1的时候就引入了Spark,那个时候的环境是Hadoop CDH 4.3版本。
最初用Spark就是跑一些基础的数据挖掘任务,其他任务还都是用MR+HIVE来完成。后来发现,对比Hadoop,Spark在开发和性能方面确实具有明显优势,因此就开始将整个数据中心的计算全部迁移到了Spark平台。任务多了,而且需要并发的跑任务,因此就需要一个资源调度系统。 CDH 4.3是支持YARN的,而Spark后边支持了YARN,因此比较自然地选择了YARN来做资源调度。
具体做法是分不同的队列,通过对不同类型任务指定不同的队列,这样就可以并发执行不同的任务。结果遇到的第一个问题就是资源如何去划分? 多个队列的资源划分都是采用不同的资源百分比来实现。整个资源分配的粒度不够细,不过还可以用。 结果到了Spark 1.2的时候Spark就开始声明在后期大版本要废弃对YARN alpha的支持,而CDH 4.3的YARN就是alpha版本。
于是到了Spark 1.3之后就面临了一个选择,后期所有的Spark版本必须自己修改去支持CDH 4.3,或者升级Hadoop到更新的版本(CDH 5.x),或者采用其他的资源调度方式。然而当下的Hadoop集群已有P级别的数据,带着数据升级是一个非常有风险的事情。于是我们开始考虑用Mesos来做资源的调度和管理。我们的计划是CDH 4.3不升级,新的机器都用新的Hadoop版本,然后用Mesos来统一调度。另外,都引入Tachyon作为缓存层,SSD作为shuffle的落地存储。如果用Mesos调度,我们对Hadoop版本的依赖就降低了。Hadoop升级风险有点高。这算是我们遇到的最大的一个坑了。我这里关于YARN的吐槽就这么多,其余的使用Spark的坑,后边有机会再说吧。
田毅——1.4.0中,Spark on YARN的classpath问题
最近遇到了一个说大不大,说小不小的坑,大致情况是提交的spark job遇到了各种各样的classpath问题——包括找不到class和不同版本class冲突。尤其是升级到spark 1.4.0以后,在YARN上运行时经常遇到这个问题,今天主要是和大家分享一下Spark on YARN环境下classpath的问题。总结了一下Spark在YARN上的class加载规则,供大家参考(以下内容针对Spark1.4.0版本YARN client模式)。
Spark通过spark-submit向YARN集群提交job,在不修改spark相关启动脚本的情况下,下列因素决定了spark-submit提交的任务的classpath(可能有遗漏,请补充)。
$SPARK_HOME/lib/datanucleus-*.jar
$SPARK_CLASSPATH
—driver-class-path
—jars
spark.executor.extraClassPath
spark.driver.extraClassPath
这是个非常麻烦的问题,Spark做了这么多的配置方式,各个版本加载机制也不太一样,使用起来非常头疼,具体来看看spark-submit命令的执行机制:
bin/spark-submit
执行bin/spark-class
执行bin/load-spark-env.sh
执行conf/spark-env.sh
执行java -cp … org.apache.spark.launcher.Main
生成Driver端的启动命令
其中第5步是最近才改过来的,之前这一步是在shell里面实现的,这一改,想了解实现逻辑就只能看scala源码,对于部分开发者又变成了黑盒……想了解详细过程的同学可以在spark-class命令里面加上set -x,通过观看org.apache.spark.launcher.Main的代码,可以得到Driver端classpath的加载顺序:
- $SPARK_CLASSPATH(废弃,不推荐)
- 配置—driver-class-path or spark.driver.extraClassPath
- $SPARK_HOME/conf
- $SPARK_HOME/lib/spark-assembly-xxx-hadoopxxx.jar
- $SPARK_HOME/lib/datanucleus-*.jar
- $HADOOP_CONF_DIR
- $YARN_CONF_
- $SPARK_DIST_CLASSPATHDIR
Executor的class加载远比Driver端要复杂,我这里不详细说了,有兴趣的同学可以去看看spark-yarn模块的代码。Executor端classpath加载顺序:
- spark.executor.extraClassPath
- $SPARK_HOME/lib/spark-assembly-xxx-hadoopxxx.jar
- $HADOOP_CONF_DIR
- `hadoop classpath`
- —jars
这里特别需要注意加载顺序,错误的顺序经常会导致包裹在不同jar包中的不同版本的class被加载,导致调用错误。了解了加载顺序以后,推荐大家配置classpath按照如下方式:
对Driver端,使用—driver-class-path来完成driver端classpath的控制,足够满足需求;对于Executor端,如果使用—jars命令的话,要注意和Hadoop中与spark-assembly的类冲突问题,如果需要优先加载,通过spark.executor.extraClassPath方式进行配置。这里稍微说一句题外话,我们这两天尝试了phoenix的4.4.0版本,对于Spark处理后的DataFrame数据可以非常的方便通过Phoenix加载到HBase。只需要一句话:
卢亿雷——YARN的资源管理机制
先看两张YARN资源管理的图,一个是RM的图,一个NodeManage的图:

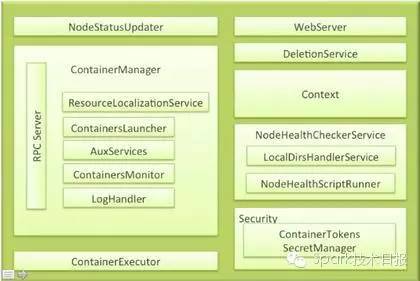
1. 多类型资源调度 ——主要采用DRF算法
2. 提供多种资源调度器 :
FIFO
Fair Scheduler
Capacity Scheduler
3. 多租户资源调度器:资源按比例分配、层级队列划分方式、以及资源抢占方式
这里举一个遇到的坑:
有一次发现RM不能分配资源,看集群状态都是正常的,CPU、内存、磁盘、带宽都比较低。但是任务分配非常慢,查了RM的日志好长时间后找到一个线索:

发现是org.apache.hadoop.yarn.api.ApplicationClientProtocolPB.get这个API由于在定期取集群状态,而由于集群的历史状态太多,导致每次取出状态的时候返回值太大,导致RM出现阻塞了。所以建议大家在检测集群状态的时候需要特别留意是否取值太大了。另外就是如果集群有任何的异常,建议一定要先看LOG,LOG基本上可以告诉我们所有的事情。接下来我简单介绍一下我们Hadoop应用的场景:
我们目前拥有由原来几十台机器到现在超过1500台的服务器集群,每天需要完成超过100亿的采集请求,每天有上千亿数据的离线、流式、实时分析和计算。所以对我们的集群非常有挑战。
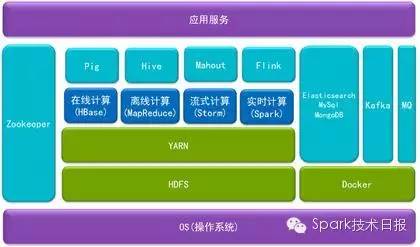
从这个架构图我们可以发现我们其实基本上用了整个Hadoop生态系统的很多技术和系统。大家一定会问我们为什么会把Flink和Spark一起用。在昨天发的Hadoop Summit 2015有一些简单介绍了。这里,先给大家透漏一下我们做的一个比较:是测试的K-Means,这个数据还是有一些吃惊的。
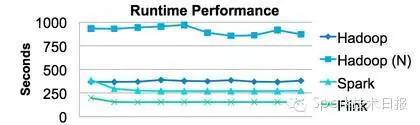
Flink除了兼容性外,性能竟然要比Spark要高。具体的分析报告下周我会给大家分享的。
夏俊鸾——Mesos特性和现状
其实,Mesos在国外用得比较多,国内不是太多。从目前Mesos官网上看,比较大的就是airbnb和yelp。Mesos在spark 0.8版本的时候就有了,和standalone差不多一起诞生,YARN差不多到1.0才可用。其实在Spark 出来的时候Mesos远比YARN稳定,而且也是伯克利自己的东西,支持的力度很大。
目前Spark里面Mesos和YARN都支持两种调度模式,client和cluster。其中Mesos还支持粗力度和细力度两种模式,细力度的模式下,在提交task的时候直接跟mesos master通信,使得Spark作业和其他框架作业共享资源。当然也包括其它的Spark作业,资源不独占。但是这样方式的坏处就是调度overhead比较大,不适合交互式作业。粗力度的调度方式其实和目前YARN是一样的,有利于低延迟的作业。两种模式的测试数据我有的,下次可以分享一下。由于不在Hadoop的生态内,Mesos还是比较悲剧的。
Q(CSDN用户):Spark生成parquet格式一般建议每个parquet多大?
田毅:这个我的建议是别弄太大,数据(压缩前)最好别超过128M,这个数不是绝对的,要看你的列数和压缩比。
阎志涛:我们的都在几百兆,parquet主要还是看你读取出多少列来。如果读出的列很多,性能就不一定好了。
Q(CSDN用户):千万数据的join或者reduce过程中总是有任务节点丢失的情况?
田毅:这个是经常出现的问题,最常见原因还是GC导致的长时间卡住,导致心跳超时。可以参考intel他们最近在summit上分享的GC调优方面的实践。GC问题在1.4版本中已经得到改善,比如大量数据查重。
直播&提问方式
1.扫码加入Spark微信讨论组2。(注:直接扫码加入已满,后续需要邀请加入。请大家先扫这个)
以上是关于YARN & Mesos,论集群资源管理所面临的挑战的主要内容,如果未能解决你的问题,请参考以下文章