Yarnlabel-based scheduling实战总结
Posted 大数据和云计算技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Yarnlabel-based scheduling实战总结相关的知识,希望对你有一定的参考价值。
1.1 Label-based scheduling介绍
故名思议,Label based scheduling是一种调度策略,就像priority-based scheduling一样,是调度器调度众多调度策略中的一种,可以跟其他调度策略混合使用,实际上,hadoop也是这样做的。但是,相比于其他调度策略,基于标签的调度策略则复杂的多,这个feature的代码量非常大,基本上需要修改YARN的各个模块,包括API, ResourceManager,Scheduler等。该策略的基本思想是:用户可以为每个nodemanager标注几个标签,比如highmem,highdisk等,以表明该nodemanager的特性;同时,用户可以为调度器中每个队列标注几个标签,这样,提交到某个队列中的作业,只会使用标注有对应标签的节点上的资源。举个例子:
比如最初你们的hadoop集群共有20个节点,硬件资源是32GB内存,4TB磁盘;后来,随着spark地流行,公司希望引入spark计算框架,而为了更好地运行spark程序,公司特地买了10个大内存节点,比如内存是64GB,为了让spark程序与mapreduce等其他程序更加和谐地运行在一个集群中,你们希望spark程序只运行在后来的10个大内存节点上,而之前的mapreduce程序既可以运行在之前的20个节点上,也可以运行在后来的10个大内存节点上,怎么办?有了label-based scheduling后,这是一件非常easy的事情,你需要按一以下步骤操作:
步骤1:为旧的20个节点打上normal标签,为新的10个节点打上highmem标签;
步骤2:在capacity scheduler中,创建两个队列,分别是hadoop和spark,其中hadoop队列可使用的标签是nornal和highmem,而spark则是highmem,并配置两个队列的capacity和maxcapacity。
参考资料:
hortonworks的官网介绍:
或者apache的官网介绍:
1.2 Label-based scheduling相关指令
(1) yarn rmadmin-addToClusterNodeLabels"part_A(exclusive=true),part_B(exclusive=true)" 为Yarn创建part_A与part_B两个exclusive分区(Yarn中叫partition)
(2) yarn cluster --list-node-labels
查看Yarn集群的所有标签,如下所示:
这就是命令(1)创建的两个标签,此时的标签还未打到相应的节点(NodeManager)上
(3) yarn rmadmin-replaceLabelsOnNode "slave4=part_A slave3=part_B"
将标签part_A与part_B分别打在slave4与slave3节点上;在Yarn中也将标签叫做partition,当执行完(1)与(3)时,我们可以从Yarn的UI界面中看到如下信息:
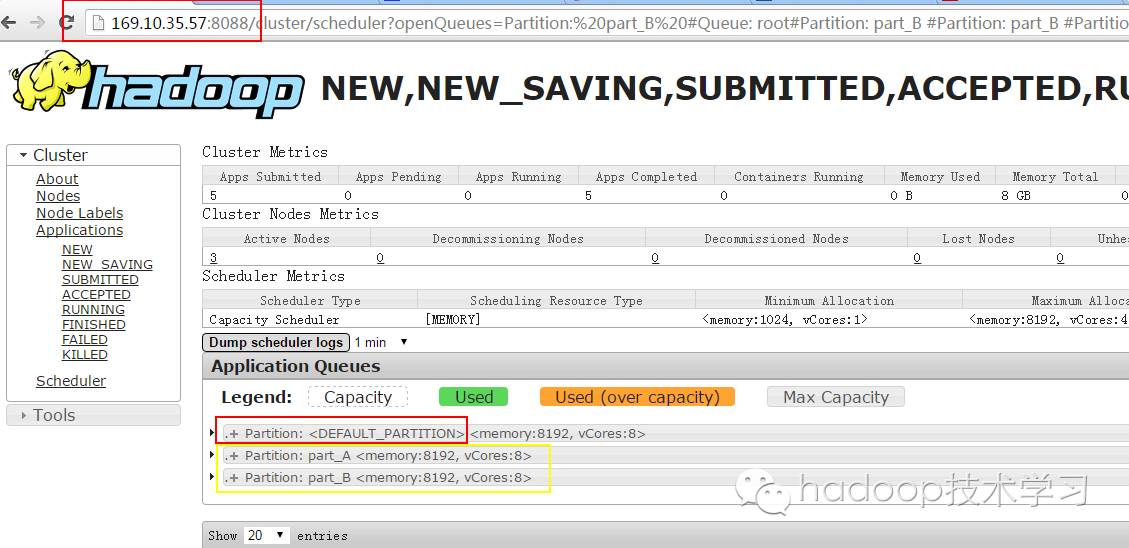
这就是我上面提到为什么Yarn中将标签叫做partition了。
删除节点上的labelpartition:
yarn rmadmin -replaceLabelsOnNode "slave3" //该命令删除了slave3节点上的labelpartition
(4) 按需求修改配置文件capacity-scheduler.xml
在该配置文件中主要配置哪些队列(queue)能访问相应的partition,例如:
<property>
<name>yarn.scheduler.capacity.root.queue_A.accessible-node-labels</name>
<value>part_A</value>
</property>
该配置项指定queue_A能访问part_A分区(partition),而part_A分区又是打在slave4上的,即指定运行在queue_A队列上的任务(例如Mapreduce作业)就会运行在slave4节点上。
capacity-scheduler.xml文件中的其他配置项,这里就不一一讲解了。
(5) Yarn重新加载capacity-scheduler.xml文件
在修改了capacity-scheduler.xml配置文件之后,需要使Yarn重新加载该文件,使用以下命令加载:
yarn rmadmin –refreshQueues
当然也可以重启Yarn集群来重新加载配置文件。
(6) yarn node –list
查看Yarn集群节点信息,如下所示:

(7) yarn node –status <NodeId>
查看某一个节点的详细信息(包括其标签信息),例如: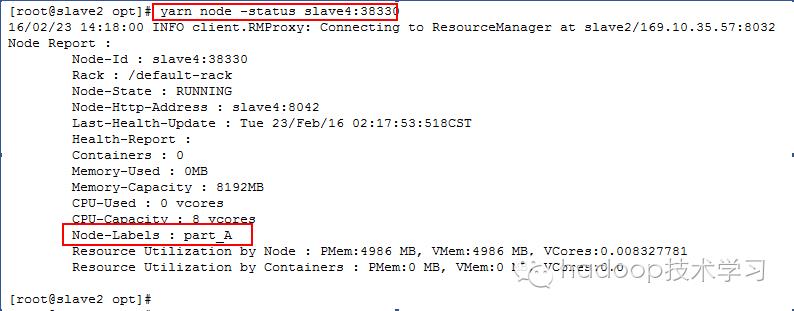
(8) 命令帮助查询
yarn rmadmin 回车
yarn node 回车
则可以查询到Yarn的各种相关命令帮助信息,如下示例所示:
1.3 Label-based scheduling实战
在(2)中我们已经为Yarn创建了partition,并为各partition指定了归属于它的节点,所以我们只要在Yarn的配置文件capacity-scheduler.xml中设置好队列(queue)与partition的对应关系,就可以进行label-based scheduling实战了。
一个配置好的capacity-scheduler.xml文件在Yarn UI界面的呈现如下:


从上图可以看出,queue_A队列可以访问part_A分区,而queue_B队列可以访问part_B分区,下面我们来看看capacity-scheduler.xml文件中的重要配置项:
(1) 分区共享配置
上图的1处表示part_A分区的资源可以被part_B分区使用(当part_B分区的资源不够用时),上图的2处表示part_B分区的资源不共享给任务其他分区,即使自己完全未被使用。
(2) 队列(queue)配置
队列整体配置:

该处指出Yarn中配置了queue_A、queue_B与default三个队列,root队列是Yarn的顶级队列,其他的均为root队列的子队列。
队列容量配置:
Default队列容量:

Queue_A队列容量:
Queue_B队列容量:
所有队列容量占比的和应为1
(3) 队列与partition的匹配
如下所示:

分别指定队列queue_A可以访问part_A分区,队列part_B可以访问part_B分区
(4) Mapreduce验证
经过上面的(1)、(2)与(3)步,我们主要做了两件事:
1、 配置了queue_B队列可访问part_B分区,queue_A队列可访问part_A分区
2、 配置了part_B分区资源不够用时可以访问part_A的资源,而part_A分区资源
不够用时不可以访问part_B的资源。
下面我们通过运行一个Mapreduce程序来验证上面的1与2结论。
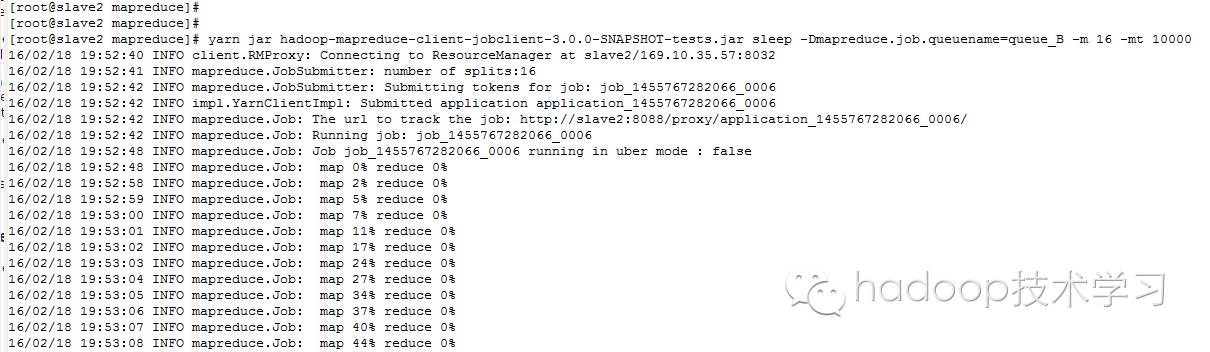
运行的Mapreduce指令如下:
yarn jarhadoop-mapreduce-client-jobclient-3.0.0-SNAPSHOT-tests.jar sleep -Dmapreduce.job.queuename=queue_B -m 16 -mt 10000
-m numMapper
-mt mapSleepTime (msec)
该命令指定一个Mapreduce程序运行在queue_B队列中,而队列queue_B使用的是part_B分区,并且part_B分区资源不够用时可以访问part_A分区的资源,下面我们来看看运行情况:
运行图1(linux command line):
运行图2(Yarn的UI界面):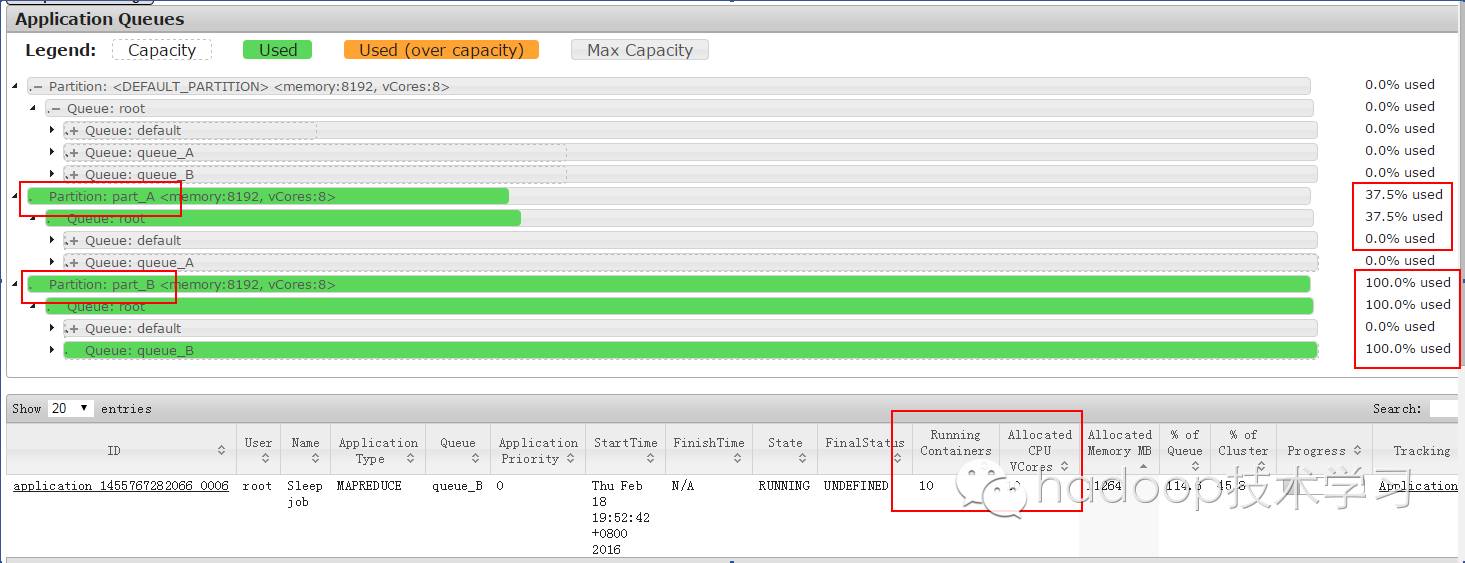
从运行图2中可以看出,part_B分区的资源被用完了,而且还用了part_A分区37.5%的资源。
那接下来我们将同样一个Mapreduce程序运行在queue_A队列中,queue_A队列使用的part_A分区,且分区part_A资源不够用时不可以访问part_B的资源,运行命令如下:
yarn jarhadoop-mapreduce-client-jobclient-3.0.0-SNAPSHOT-tests.jar sleep -Dmapreduce.job.queuename=queue_A -m 16 -mt 10000
运行图1(linux command line):
运行图2(Yarn的UI界面):
从运行图2可知,该Mapreduce程序只使用了part_A分区的资源,即使资源用到了100%,分区part_B还是闲着的。
以上是关于Yarnlabel-based scheduling实战总结的主要内容,如果未能解决你的问题,请参考以下文章