套现了十五亿得叫多少人才能安全搬回家-YARN
Posted Jianpan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了套现了十五亿得叫多少人才能安全搬回家-YARN相关的知识,希望对你有一定的参考价值。
照旧,开始今天的分享之前先来说个小故事,小时候看三国,认为最潇洒的就是诸葛亮,所谓运筹帷幄决胜千里,所谓神机妙算足智多谋,但是诸葛亮是个事必躬亲的人,事无巨细,不懂得放权,活活给累死的,活活给累死的,活活给累死的,重要的事说 3 遍。结论是:管的宽,挂的快。
YARN产生的背景
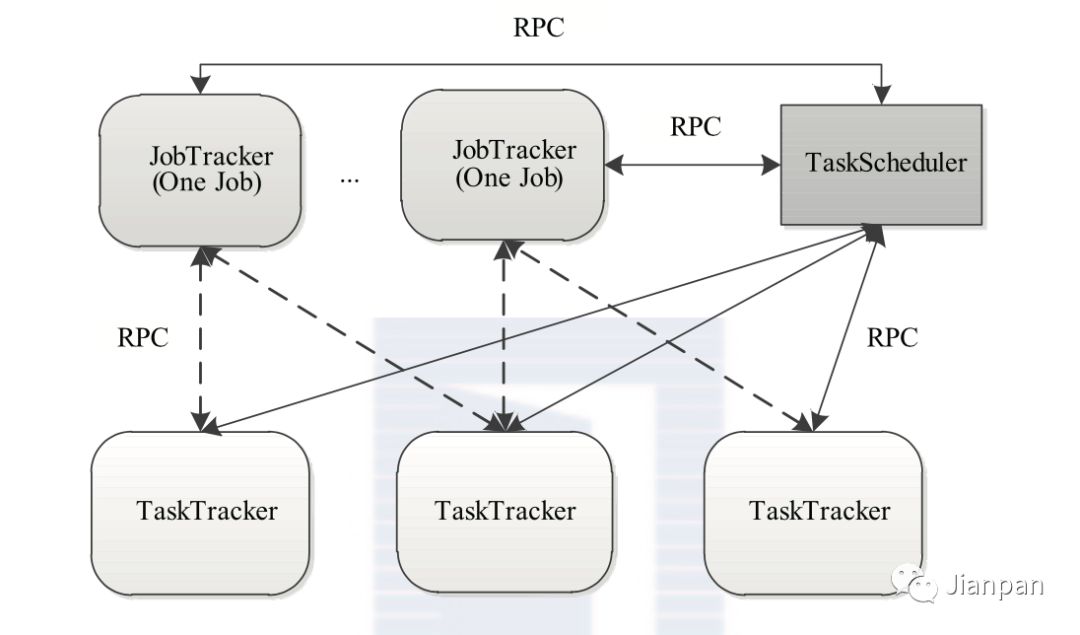
没有YARN之前,MapReduce1.x架构图
如图所示:Master / Slave架构,1 个 JobTracker 带多个 TaskTracker,JobTracker 是整个框架的核心,我们根据图来看下JobTracker 到底要做什么事:
1.JobTracker 接收客户端提交的 job;
3.JobTracker 要确定 job 的执行计划:确定执行 job 的 Map Reduce 的 task 数量,并分配到离数据块最近的节点上,这就 JobTracker 要确定哪些机器是活的,资源还剩多少;另外根据他们和数据分布的情况作出分配策略;
4.JobTracker 提交所有 task 到每个 TaskTracker 节点,TaskTracker 会定时的向 JobTracker 发送心跳,若一定时间没有收到心跳,JobTracker 就默认这个 TaskTracker 节点挂了要做资源回收,并把这个节点上的 task 重新分配到其他节点上;
5.监听 task 的执行情况,执行完成,JobTracker 会更新 job 的状态为完成,若是一定数量的 task 执行失败,这个 job 就会被标记为失败;
6.JobTracker 将发送 job 的运行状态信息给 Client 端;
综合来说,JobTracker 既当爹又当妈,既要管理资源又要做任务调度,这不得活活把自己给累死。
1.1 MapReduce1.x 版本存在的问题:单点故障&节点压力大不易扩展&不支持除了 MapReduce 之外的处理框架。
1.2 资源利用率低&运维成本高。
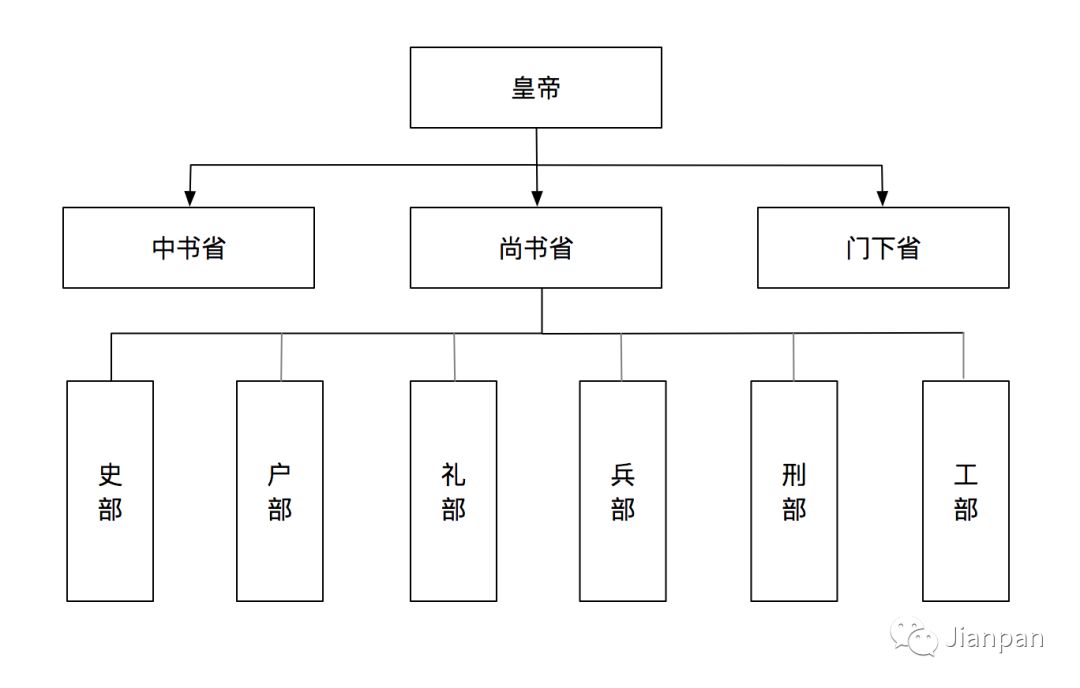
再来说说诸葛亮,他要是懂的简政放权,也不至于英年早逝,太悲催了。我们再来看看隋唐时期的三省六部制,皇帝逍遥快活还能把国力发展的很鼎盛,唐朝存活了289年。那是为什么呢?因为他们只负责统筹协调,具体事情有下面的每个机构来做。
下一代 MapReduce 框架的基本设计思想就是将 JobTracker 的两个主要功能,即资源管理和作业控制(包括作业监控,容错等)拆分成两个独立的进程,如下图所示资源管理进程与具体应用程序分离,它只负责集群的资源(内存,CPU,磁盘)管理,而作业控制进程是直接与应用程序相关的模块,且每个作业控制进程只负责管理一个作业。这样通过将原有的 JobTracker 中与应用程序相关和无关的模块分开,不仅减轻了 JobTracker 的负载,也使得 Hadoop 支持其他的计算框架。
下一代 MapReduce 框架基本架构
YARN概述
从资源管理角度看,下一代 MapReduce 框架实际上衍生出了一个资源统一管理平台YARN,YARN 的基本思想是将资源管理和作业调度/监控的功能分解为单独的守护进程。这个包括 2 个部分,一个全局的资源调度 ResourceManager(RM)和针对每个应用程序的ApplicationMaster(AM)。应用程序可以只是一个工作也可以是一个 DAG(有向无环图)工作。它使得 Hadoop 不再局限于仅支持 MapReduce 一种计算模型,而是可无限融入多种计算框架,且对这些框架进行统一管理和调度。
YARN 基本架构
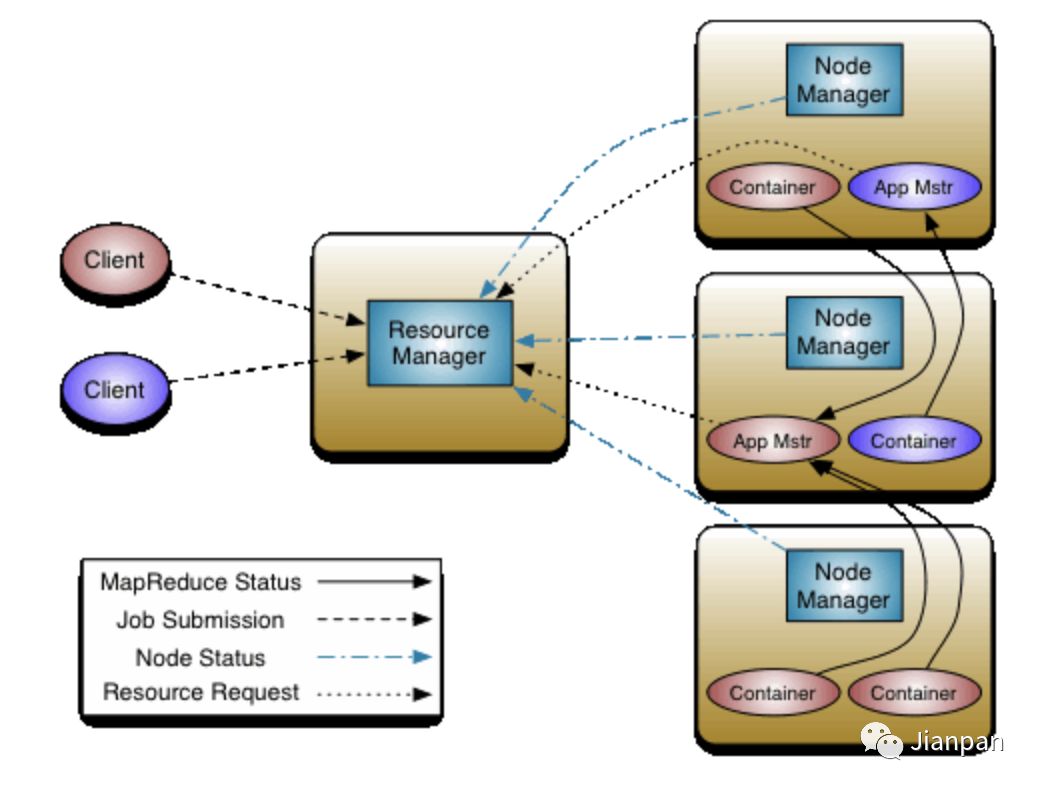
如图 ResourceManager (RM)和 NodeManager(NM) 组成了整个数据计算框架,在整个系统中,所有的应用程序所需的资源都由RM说了算,RM在这拥有至高无上的权利。NM是每台机器分配资源的代理人,NM负责监听资源的使用个情况包括(CPU,内存,磁盘,网络),并实时向NM汇报。每个应用程序的ApplicationMaster(AM)实际上是一个特别的框架,AM的任务是负责向NM申请所需资源,获取资源后跟NM一起合作执行并监督任务的完成情况。我们来分别详细的介绍一下各个模块的功能作用:
ResourceManager:全局的资源管理者,整个集群只有唯一的一个,负责集群的资源统一管理和分配调度:
1.处理客户端的请求
2.启动监控 ApplicationMaster
3.监控 NodeManager
4.资源分配调度
NodeManager:整个集群中有多个,负责自己本身节点的资源管理使用:
1.定时向RM汇报本节点的资源情况
2.单个节点上的资源任务管理
3.执行 NodeManager 的命令:启动 Container
4.协助 ApplicationMaster处理任务
5.管理着抽象的资源容器,这些容器代表着一个应用程序针对每个节点上的资源
ApplicationMaster:管理应用程序在yarn上的每个实例:
1.每个应用程序对应一个:MR、Spark,负责应用程序的管理
2.为应用程序向RM申请资源(core、memory),分配给内部task
3.需要与 NM 通信:启动/停止 task,task 是运行在 container 里面,AM 也是运行在 container 里面
Container:YARN 中的资源抽象,封装了该节点上的多维度资源:
1.封装了 CPU、Memory 等资源的一个容器
2.是一个任务运行环境的抽象,且该任务只能使用该 container 中描述的资源
那么 YARN 框架相对于老的 MapReduce 框架有什么优势呢?
YARN 作为一个资源管理系统,其最重要的两个功能就是资源调度和资源隔离,通过 RM 实现资源调度,隔离则由各个 NM 实现。
资源调度指的是 RM 可以将某个 NM 上的资源分配给任务,而资源隔离则是 NM 按照任务需要提供相应的资源,保证这些资源的独占性,为任务运行提供保证。具体来说就是老的框架中 JobTracker 很大的一个负担就是要监控 job 中 task 的运行情况,现在这部分有 ApplicationMaster来完成。
补充一点:ResourceManager 有两个主要组件:Scheduler 和 ApplicationsManager。ApplicationsManager 用来监控 ApplicationMaster的运行情况,如果出问题会在其他机器上重启。
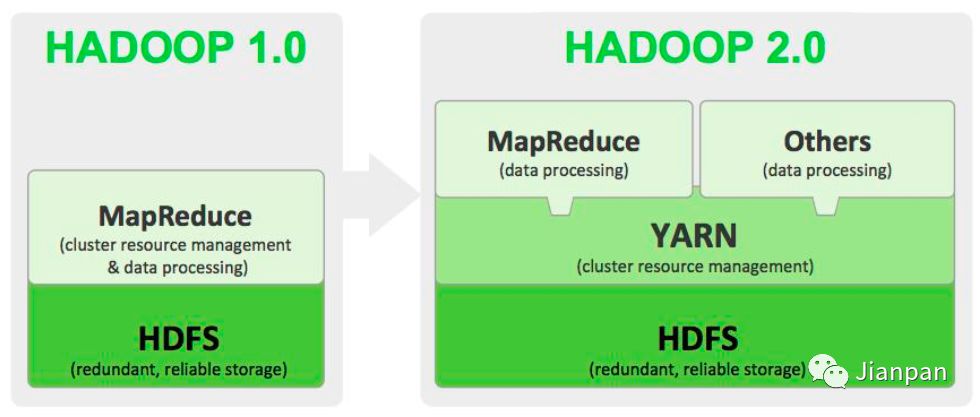
如上图所示,hadoop1.0 版本只支持 MapReduce 计算,而2.0多了 yarn 这个集群资源管理框架,这样的好处就是不同的计算框架(Spark/MapReduce/Storm/Flink)可以共享一个hdfs集群上的数据,享受整体的资源调度,按需分配,进而提高集群资源的利用率。这就好比yarn成为了 hadoop 的操作系统,只要你符合我的标准,就可以安装不同的软件。
YARN执行流程
1.客户端向yarn提交作业,首先找 RM 分配资源;
2.RM 接收到作业以后,会与对应的 NM 建立通信;
3.RM 要求 NM 创建一个 Container 来运行 ApplicationMaster 实例;
4.ApplicationMaster 会向 RM 注册并申请所需资源,这样 Client 就可以通过 RM 获知作业运行情况;
5.RM 分配给 ApplicationMaster 所需资源,ApplicationMaster 在对应的 NM 上启动 Container;
6.Container 启动后开始执行任务,ApplicationMaster 监控各个任务的执行情况并反馈给 RM;
其中 ApplicationMaster 是可插拔的,可以替换为不同的应用程序。
如果觉得文章不错,欢迎转发点赞,另外有错误欢迎留言指出,谢谢。
更多好文,敬请期待!
以上是关于套现了十五亿得叫多少人才能安全搬回家-YARN的主要内容,如果未能解决你的问题,请参考以下文章