YARN 架构学习总结
Posted 柳年思水
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YARN 架构学习总结相关的知识,希望对你有一定的参考价值。
关于 Hadoop 的介绍,这里就不再多说,可以简答来说 Hadoop 的出现真正让更多的互联网公司开始有能力解决大数据场景下的问题,其中的 HDFS 和 YARN 已经成为大数据场景下存储和资源调度的统一解决方案(MR 现在正在被 Spark 所取代,Spark 在计算这块的地位也开始受到其他框架的冲击,流计算上有 Flink,AI 上有 Tensorflow,两面夹击,但是 Spark 的生态建设得很好,其他框架想要在生产环境立马取代还有很长的路要走)。本篇文章就是关于 YARN 框架学习的简单总结,目的是希望自己能对分布式调度这块有更深入的了解,当然也希望也这篇文章能够对初学者有所帮助,文章的主要内容来自 《Hadoop 技术内幕:深入解析 YARN 架构设计与实现原理》[1] 和 《大数据日知录:架构与算法》[2]。
Yarn 背景
关于 YARN 出现的背景,还是得从 Hadoop1.0 说起,在 Hadoop1.0 中,MR 作业的调度还是有两个重要的组件:JobTracker 和 TaskTracker,其基础的架构如下图所示,从下图中可以大概看出原 MR 作业启动流程:
1.首先用户程序 (Client) 提交了一个 job,job 的信息会发送到 JobTracker 中,JobTracker 是 Map-Reduce 框架的中心,它需要与集群中的机器定时通信 (心跳:heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作;2.TaskTracker 是 Map-Reduce 集群中每台机器都有的一个组件,它做的事情主要是监视自己所在机器的资源使用情况;3.TaskTracker 同时监视当前机器的 tasks 运行状况。TaskTracker 需要把这些信息通过 heartbeat 发送给 JobTracker,JobTracker 会搜集这些信息以便处理新提交的 job,来决定其应该分配运行在哪些机器上。
可以看出原来的调度框架实现非常简答明了,在 Hadoop 推出的最初几年,也获得业界的认可,但是随着集群规模的增大,很多的弊端开始显露出来,主要有以下几点:
1.JobTracker 是 Map-Reduce 的集中处理点,存在单点故障;2.JobTracker 赋予的功能太多,导致负载过重,1.0 时未将资源管理与作业控制(包括:作业监控、容错等)分开,导致负载重而且无法支撑更多的计算框架,当集群的作业非常多时,会有很大的内存开销,潜在来说,也增加了 JobTracker fail 的风险,这也是业界普遍总结出 Hadoop1.0 的 Map-Reduce 只能支持 4000 节点主机上限的原因;3.在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一个节点上,很容易出现 OOM;4.在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题。
Hadoop 2.0 中下一代 MR 框架的基本设计思想就是将 JobTracker 的两个主要功能,资源管理和作业控制(包括作业监控、容错等),分拆成两个独立的进程。资源管理与具体的应用程序无关,它负责整个集群的资源(内存、CPU、磁盘等)管理,而作业控制进程则是直接与应用程序相关的模块,且每个作业控制进程只负责管理一个作业,这样就是 YARN 诞生的背景,它是在 MapReduce 框架上衍生出的一个资源统一的管理平台。
Yarn 架构
YARN 的全称是 Yet Another Resource Negotiator,YARN 整体上是 Master/Slave 结构,在整个框架中,ResourceManager 为 Master,NodeManager 为 Slave,如下图所示:
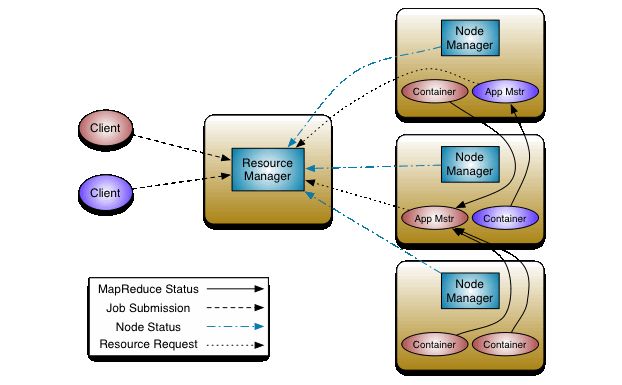
ResourceManager(RM)
RM 是一个全局的资源管理器,负责整个系统的资源管理和分配,它主要有两个组件构成:
1.调度器:Scheduler;2.应用程序管理器:Applications Manager,ASM。
调度器
调度器根据容量、
以上是关于YARN 架构学习总结的主要内容,如果未能解决你的问题,请参考以下文章