Yarn模式下的监控界面介绍
Posted 人工智能与大数据生态
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Yarn模式下的监控界面介绍相关的知识,希望对你有一定的参考价值。

Yarn模式概述
Spark客户端可以直接连接Yarn,不需要额外构建Spark集群。
有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点不同。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到APP的输出。
yarn-cluster:Driver程序运行在RM(ResourceManager)启动的AM(AplicationMaster)上,适用于生产环境。
Yarn是一个资源调度平台,负责为运算程序提供服务器计算资源,方便我们编写的Spark、flink、MapReduce这些应用在它上面运行。
资源的具体分配和调度不需要人们手动去操作,这种情况下,我们怎么能看到Yarn机器有多少资源呢?内存、CPU等。还有我们提交到Yarn的这些应用,他们的运行状态是什么,占用率多少资源,哪个节点在计算,执行时间等等,都是我们需要关注的问题。
修改Hadoop配置文件,进行访问,下面就是Yarn的界面。
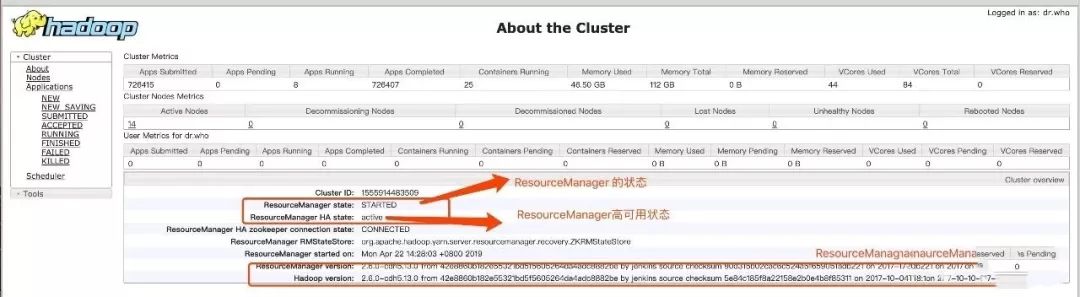
about the cluster界面可以看到Yarn的ResourceManager的状态、是否是HA、以及版本的信息。
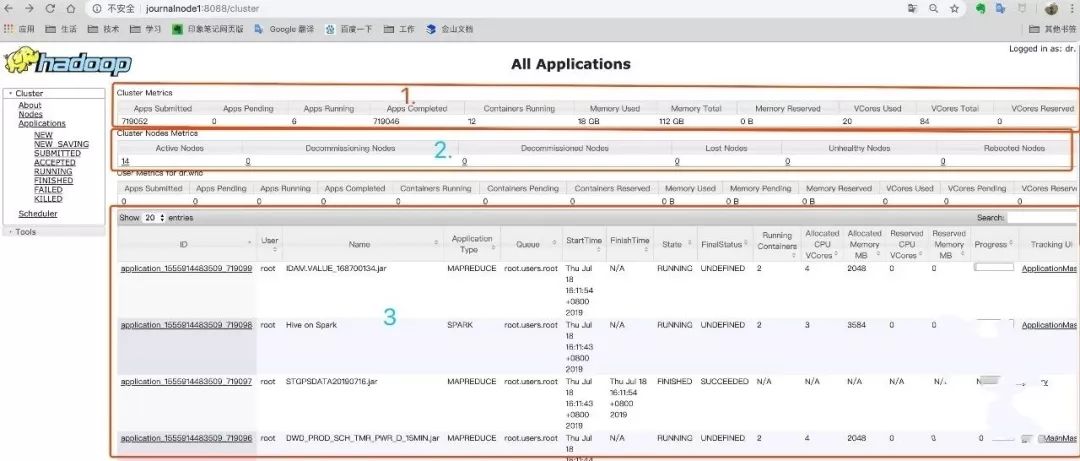
上面编号为1区域的是整个集群的监控信息:
Apps Submitted:已提交的应用。
Apps Completed:已经完成的应用。
Apps Running:正在运行的应用。
Containers Running:正在运行的应用。
在yarn运行任务之前,会先创建一个容器。
Memory Total:集群的总内存。
Memory Used:集群已使用的内存。
VCores Used:已经使用CPU的核数。
VCores Total:集群的CPU总的核数。
Memory Reserved:预留的内存。
VCores Reserved:预留的CPU的核数。
yarn为了防止分配一个容器到NodeManager的时候,NodeManager当前不能满足。
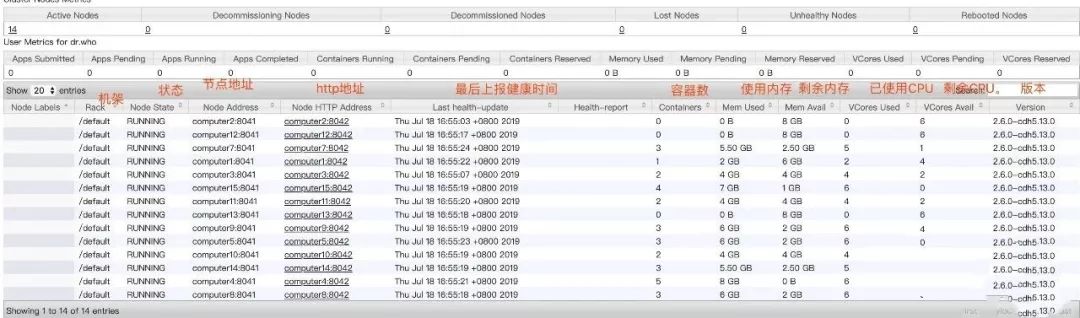
集群节点信息
应用列表信息
上图编号为3的是yarn任务执行的具体情况。
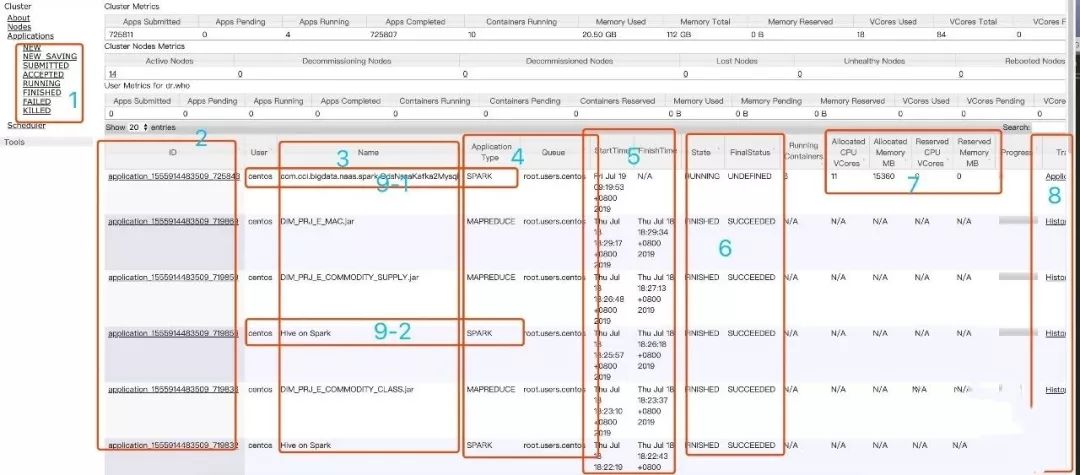
将上面的页面分为8块,每一块的介绍如下:
可以根据任务的不同状态去筛选,点击后,可以再点击ID进去查看日志。
任务的ID。
任务的名字,这里的名称是提交spark任务的主类名。hive on spark,使用hive的脚本跑的,执行引擎是spark。MapReduce任务,是用来sqoop进行数据抽取,底层是MapReduce。Flink session cluster,是Flink任务。
应用的类型,常见的类型有spark、MapReduce、Flink。这些队列有默认的,也有自己在提交时通过--queue进行队列指定。如果没指定,会以提交任务时使用的那个账户进行提交。
任务的时间和结束的时间。
当前任务的状态和最终的状态。
任务占用的相关资源情况。
某个应用详情页
在上面的页面中点击ID,就会跳转到下面这个详情页。
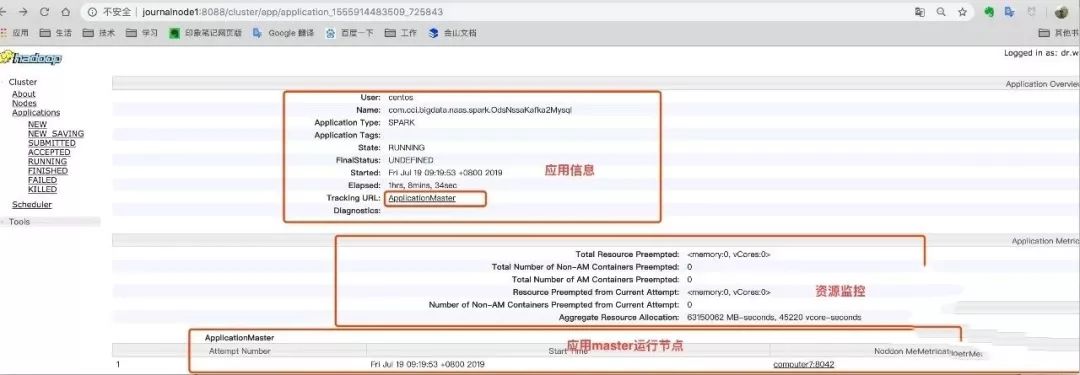
查看日志
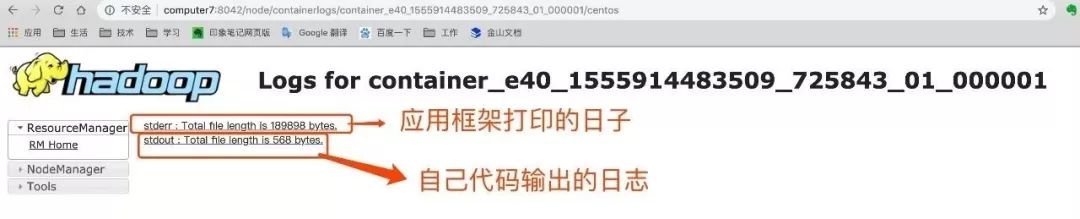
在详情页ApplicationMaster中,点击log,就会跳转到下面的页面,有应用运行框架打印的日志,有代码打印的日志。
应用框架的监控页面
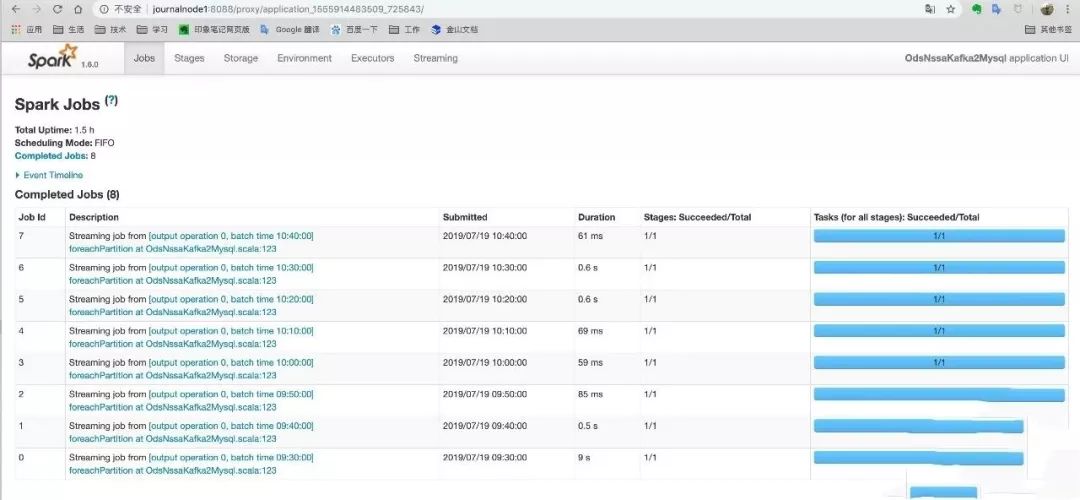
在上面的详情页面中点击,Tracking URL后边的ApplicationMaster,进入下面页面。
查看yarn的队列
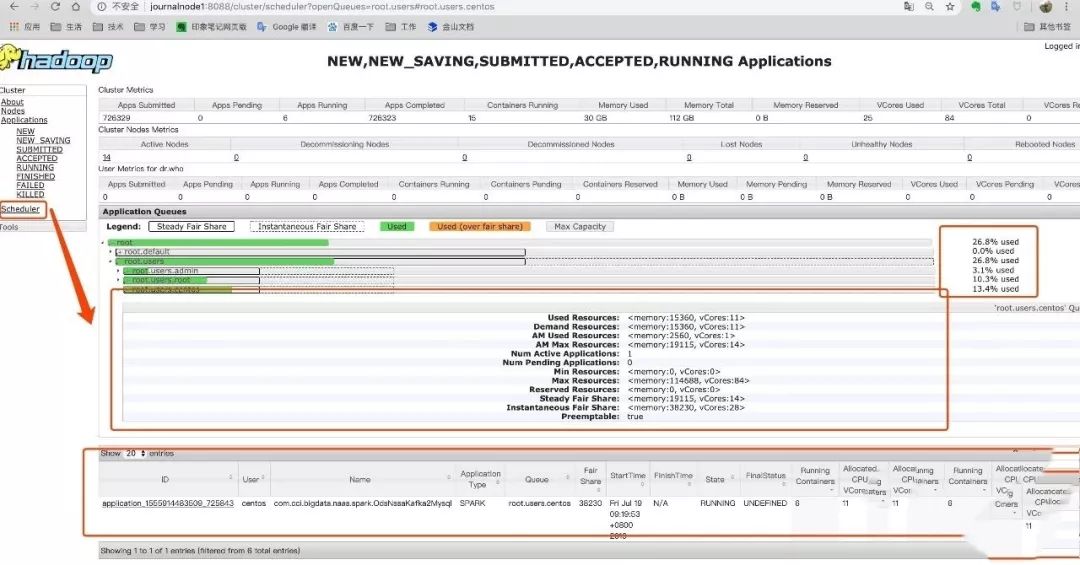
在下面页面点击左侧的调度(Scheduler)的菜单,里边可以看到yarn的队列信息。
Yarn的日志
如果发现yarn有什么问题,我们可以点击上面页面中的左边有个Tools,然后点击Local logs,可以看到yarn的日志信息:
yarn的服务监控
如果使用CDH,CDH对Yarn其实有监控的作用。那么如果是自己搭建的服务器,可以点击左侧Tools然后点击Server metrics。
下面是CDH对yarn部分监控界面:
--end--
以上是关于Yarn模式下的监控界面介绍的主要内容,如果未能解决你的问题,请参考以下文章
FlinkFlink CDH6.3.2 下的yarn per job模式 savepoint和checkpoint,卡住,没有保存成功文件