React . js 是怎样炼成的?
Posted 前端教程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了React . js 是怎样炼成的?相关的知识,希望对你有一定的参考价值。
https://segmentfault.com/a/1190000013365426
本文主要讲述 React 的诞生过程和优化思路。
内容整理自 2014 年的 OSCON - React Architecture by vjeux(https://speakerdeck.com/vjeux/oscon-react-architecture),虽然从今天(2018)来看可能会有点历史感,但仍然值得学习了解。以史为鉴,从中也可以管窥 Facebook 优秀的工程管理文化。
字符拼接时代 - 2004
时间回到 2004 年,Mark Zuckerberg 当时还在宿舍捣鼓最初版的 Facebook 。
这一年,大家都在用 php 的字符串拼接(String Concatenation)功能来开发网站。
$str = '<ul>';
foreach ($talks as $talk) {
$str += '<li>' . $talk->name . '</li>';
}
$str += '</ul>';
这种网站开发方式在当时看来是非常正确的,因为不管是后端开发还是前端开发,甚至根本没有开发经验,都可以使用这种方式搭建一个大型网站。
唯一不足的是,这种开发方式容易造成 XSS 注入等安全问题。如果 $talk->name 中包含恶意代码,而又没有做任何防护措施的话,那么攻击者就可以注入任意 JS 代码。于是就催生了“永远不要相信用户的输入”的安全守则。
最简单的应对方法是对用户的任何输入都进行转义(Escape)。然而这也带来了其他麻烦,如果对字符串进行多次转义,那么反转义的次数也必须是相同的,否则会无法得到原内容。如果又不小心把 html 标签(Markup)给转义了,那么 HTML 标签会直接显示给用户,从而导致很差的用户体验。
XHP 时代 - 2010
到了 2010 年,为了更加高效的编码,同时也避免转义 HTML 标签的错误,Facebook 开发了 XHP 。XHP 是对 PHP 的语法拓展,它允许开发者直接在 PHP 中使用 HTML 标签,而不再使用字符串。
$content = <ul />;
foreach ($talks as $talk) {
$content->appendChild(<li>{$talk->name}</li>);
}
这样的话,所有的 HTML 标签都使用不同于 PHP 的语法,我们可以轻易的分辨哪些需要转义哪些不需要转义。
不久的后来,Facebook 的工程师又发现他们还可以创建自定义标签,而且通过组合自定义标签有助于构建大型应用。
而这恰恰是 Semantic Web 和 Web Components 概念的一种实现方式。
$content = <talk:list />;
foreach ($talks as $talk) {
$content->appendChild(<talk talk={$talk} />);
}
之后,Facebook 在 JS 中尝试了更多的新技术方式以减小客户端和服务端之间的延时。比如跨浏览器 DOM 库和数据绑定,但是都不是很理想。
JSX - 2013
等到 2013 年,突然有一天,前端工程师 Jordan Walke 向他的经理提出了一个大胆的想法:把 XHP 的拓展功能迁移到 JS 中。最开始大家都以为他疯了,因为这与当时大家都看好的 JS 框架格格不入。不过他最终还是执着地说服了经理,允许他用 6 个月的时间来验证这个想法。这里不得不说 Facebook 良好的工程师管理哲学让人敬佩,值得借鉴。
附:Lee Byron 谈 Facebook 工程师文化:Why Invest in Tools(https://medium.com/@leeb/why-invest-in-tools-3240ce289930)
要想把 XHP 的拓展功能迁移到 JS ,首要任务是需要一个拓展来让 JS 支持 XML 语法,该拓展称为 JSX 。当时,随着 Node.js 的兴起,Facebook 内部对于转换 JS 已经有相当多的工程实践了。所以实现 JSX 简直轻而易举,仅仅花费了大概一周的时间。
const content = (
<TalkList>
{ talks.map(talk => <Talk talk={talk} />)}
</TalkList>
);
React
自此,开始了 React 的万里长征,更大的困难还在后头。其中,最棘手的是如何再现 PHP 中的更新机制。
在 PHP 中,每当有数据改变时,只需要跳到一个由 PHP 全新渲染的新页面即可。
从开发者的角度来看的话,这种方式开发应用是非常简单的,因为它不需要担心变更,且界面上用户数据改变时所有内容都是同步的。
只要有数据变更,就重新渲染整个页面。
虽然简单粗暴,但是这种方式的缺点也尤为突出,那就是它非常慢。
“You need to be right before being good”,意思是说,为了验证迁移方案的可行性,开发者必须快速实现一个可用版本,暂时不考虑性能问题。
DOM
取自于 PHP 的灵感,在 JS 中实现重新渲染的最简单办法是:当任何内容改变时,都重新构建整个 DOM,然后用新 DOM 取代旧 DOM 。
这种方式是可以工作的,但在有些场景下不适用。
比如它会失去当前聚焦的元素和光标,以及文本选择和页面滚动位置,这些都是页面的当前状态。
换句话来说,DOM 节点是包含状态的。

既然包含状态,那么记下旧 DOM 的状态然后在新 DOM 上还原不就行了么?
但是非常不幸,这种方式不仅实现起来复杂而且也无法覆盖所有情况。
在 OSX 电脑上滚动页面时,会伴随着一定的滚动惯性。但是 JS 并没有提供相应的 API 来读取或者写入滚动惯性。
对包含 iframe 的页面来说,情况则更复杂。如果它来自其他域,那么浏览器安全策略限制根本不会允许我们查看其内部的内容,更不用说还原了。
因此可以看出,DOM 不仅仅有状态,它还包含隐藏的、无法触达的状态。
既然还原状态行不通,那就换一种方式绕过去。
对于没有改变的 DOM 节点,让它保持原样不动,仅仅创建并替换变更过的 DOM 节点。
这种方式实现了 DOM 节点复用(Reuse)。
至此,只要能够识别出哪些节点改变了,那么就可以实现对 DOM 的更新。于是问题就转化为如何比对两个 DOM 的差异。
Diff
说到对比差异,相信大家马上就能联想到版本控制(Version Control)。它的原理很简单,记录多个代码快照,然后使用 diff 算法比对前后两个快照,从而生成一系列诸如“删除 5 行”、“新增 3 行”、“替换单词”等的改动;通过把这一系列的改动应用到先前的代码快照就可以得到之后的代码快照。
而这正是 React 所需要的,只不过它的处理对象是 DOM 而不是文本文件。
难怪有人说:“I tend to think of React as Version Control for the DOM” 。
DOM 是树形结构,所以 diff 算法必须是针对树形结构的。目前已知的完整树形结构 diff 算法复杂度为 O(n^3) 。
假如页面中有 10,000 个 DOM 节点,这个数字看起来很庞大,但其实并不是不可想象。为了计算该复杂度的数量级大小,我们还假设在一个 CPU 周期我们可以完成单次对比操作(虽然不可能完成),且 CPU 主频为 1 GHz 。这种情况下,diff 要花费的时间如下:
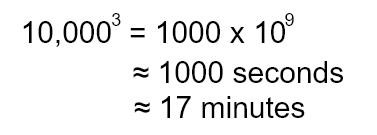
整整有 17 分钟之长,简直无法想象!
虽然说验证阶段暂不考虑性能问题,但是我们还是可以简单了解下该算法是如何实现的。
附:完整的 Tree diff 实现算法(https://grfia.dlsi.ua.es/ml/algorithms/references/editsurvey_bille.pdf)。

新树上的每个节点与旧树上的每个节点对比
如果父节点相同,继续循环对比子树
在上图的树中,依据最小操作原则,可以找到三个嵌套的循环对比。
但如果认真思考下,其实在 Web 应用中,很少有移动一个元素到另一个地方的场景。一个例子可能的是拖拽(Drag)并放置(Drop)元素到另一个地方,但它并不常见。
唯一的常用场景是在子元素之间移动元素,例如在列表中新增、删除和移动元素。既然如此,那可以仅仅对比同层级的节点。
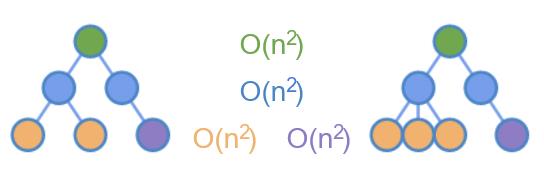
如上图所示,仅对相同颜色的节点做 diff ,这样能把时间复杂度降到了 O(n^2) 。
key

针对同级元素的比较,又引入了另一个问题。
同层级元素名称不同时,可以直接识别为不匹配;相同时,却没那么简单了。
假如在某个节点下,上一次渲染了三个 <input/>,然后下一次渲染变成了两个。此时 diff 的结果会是什么呢?
最直观的结果是前面两个保持不变,删除第三个。
当然,也可以删除第一个同时保持最后两个。
如果不嫌麻烦,还可以把旧的三个都删除,然后新增两个新元素。
这说明,对于相同标签名称的节点,我们没有足够信息来对比前后差异。
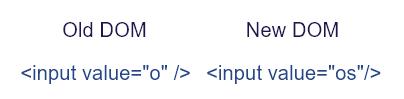
如果再加上元素的属性呢?比如 value ,如果前后两次标签名称和 value 属性都相同,那么就认为元素匹配中,无须改动。但现实是这行不通,因为用户输入时值总是在变,会导致元素一直被替换,导致失去焦点;;更糟糕的是,并不是所有 HTML 元素都有这个属性。

那使用所有元素都有的 id 属性呢?这是可以的,如上图,我们可以容易的识别出前后 DOM 的差异。考虑表单情况,表单模型的输入通常跟 id 关联,但如果使用 AJAX 来提交表单的话,我们通常不会给 input设置 id 属性。因此,更好的办法是引入一个新的属性名称,专门用来辅助 diff 算法。这个属性最终确定为 key 。这也是为什么在 React 中使用列表时会要求给子元素设置 key属性的原因。

结合 key ,再加上哈希表,diff 算法最终实现了 O(n) 的最优复杂度。
至此,可以看到从 XHP 迁移到 JS 的方案可行的。接下来就可以针对各个环节进行逐步优化。
附:详细的 diff 理解:不可思议的 react diff(https://zhuanlan.zhihu.com/p/20346379) 。
持续优化
Virtual DOM
前面说到,React 其实实现了对 DOM 节点的版本控制。
做过 JS 应用优化的人可能都知道,DOM 是复杂的,对它的操作(尤其是查询和创建)是非常慢非常耗费资源的。看下面的例子,仅创建一个空白的 div,其实例属性就达到 231 个。
// Chrome v63
const div = document.createElement('div');
let m = 0;
for (let k in div) {
m++;
}
console.log(m); // 231
之所以有这么多属性,是因为 DOM 节点被用于浏览器渲染管道的很多过程中。
浏览器首先根据 CSS 规则查找匹配的节点,这个过程会缓存很多元信息,例如它维护着一个对应 DOM 节点的 id 映射表。
然后,根据样式计算节点布局,这里又会缓存位置和屏幕定位信息,以及其他很多的元信息,浏览器会尽量避免重新计算布局,所以这些数据都会被缓存。
可以看出,整个渲染过程会耗费大量的内存和 CPU 资源。
现在回过头来想想 React ,其实它只在 diff 算法中用到了 DOM 节点,而且只用到了标签名称和部分属性。
如果用更轻量级的 JS 对象来代替复杂的 DOM 节点,然后把对 DOM 的 diff 操作转移到 JS 对象,就可以避免大量对 DOM 的查询操作。这种方式称为 Virtual DOM 。
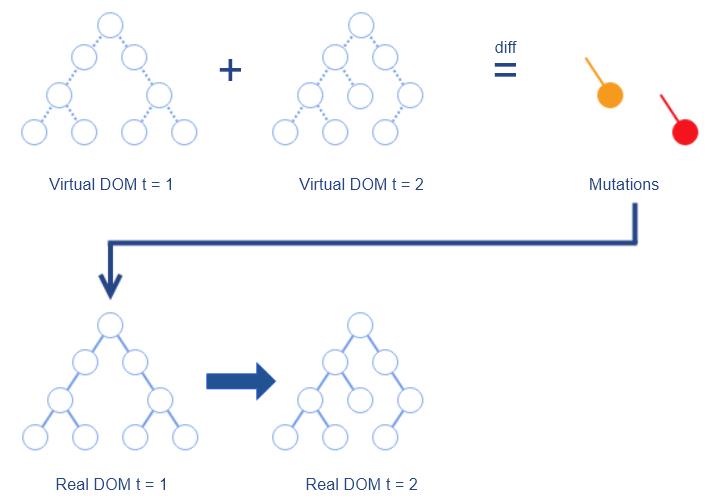
其过程如下:
维护一个使用 JS 对象表示的 Virtual DOM,与真实 DOM 一一对应
对前后两个 Virtual DOM 做 diff ,生成变更(Mutation)
把变更应用于真实 DOM,生成最新的真实 DOM
可以看出,因为要把变更应用到真实 DOM 上,所以还是避免不了要直接操作 DOM ,但是 React 的 diff 算法会把 DOM 改动次数降到最低。
至此,React 的两大优化:diff 算法和 Virtual DOM ,均已完成。再加上 XHP 时代尝试的数据绑定,已经算是一个可用版本了。
这个时候 Facebook 做了个重大的决定,那就是把 React 开源!
React 的开源可谓是一石激起千层浪,社区开发者都被这种全新的 Web 开发方式所吸引,React 因此迅速占领了 JS 开源库的榜首。
很多大公司也把 React 应用到生产环境,同时也有大批社区开发者为 React 贡献了代码。
接下来要说的两大优化就是来自于开源社区。
批处理(Batching)
著名浏览器厂商 Opera 把重排和重绘(Reflow and Repaint)列为影响页面性能的三大原因之一。
我们说 DOM 是很慢的,除了前面说到的它的复杂和庞大,还有另一个原因就是重排和重绘。
当 DOM 被修改后,浏览器必须更新元素的位置和真实像素;
当尝试从 DOM 读取属性时,为了保证读取的值是正确的,浏览器也会触发重排和重绘。
因此,反复的“读取、修改、读取、修改...”操作,将会触发大量的重排和重绘。
另外,由于浏览器本身对 DOM 操作进行了优化,比如把两次很近的“修改”操作合并成一个“修改”操作。
所以如果把“读取、修改、读取、修改...”重新排列为“读取、读取...”和“修改、修改...”,会有助于减小重排和重绘的次数。但是这种刻意的、手动的级联写法是不安全的。
与此同时,常规的 JS 写法又很容易触发重排和重绘。
在减小重排和重绘的道路上,React 陷入了尴尬的处境。
最终,社区贡献者 Ben Alpert 使用批处理的方式拯救了这个尴尬的处境。
在 React 中,开发者通过调用组件的 setState 方法告诉 React 当前组件要变更了。
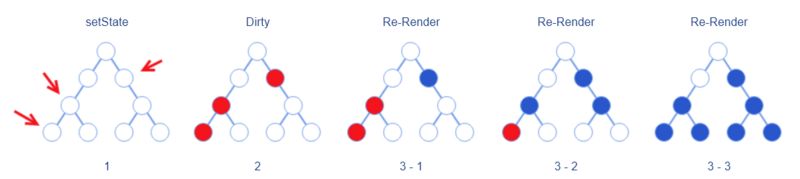
Ben Alpert 的做法是,调用 setState 时不立即把变更同步到 Virtual DOM,而是仅仅把对应元素打上“待更新”的标记。如果组件内调用多次 setState ,那么都会进行相同的打标操作。
等到初始化事件被完全广播开以后,就开始进行从顶部到底部的重新渲染(Re-Render)过程。这就确保了 React 只对元素进行了一次渲染。
这里要注意两点:
此处的重新渲染是指把
setState变更同步到 Virtual DOM ;在这之后才进行 diff 操作生成真实的 DOM 变更。与前文提到的“重新渲染整个 DOM ”不同的是,真实的重新渲染仅渲染被标记的元素及其子元素,也就是说上图中仅蓝色圆圈代表的元素会被重新渲染
这也提醒开发者,应该让拥有状态的组件尽量靠近叶子节点,这样可以缩小重新渲染的范围。
裁剪(Pruning)
随着应用越来越大,React 管理的组件状态也会越来越多,这就意味着重新渲染的范围也会越来越大。
认真观察上面批处理的过程可以发现,该 Virtual DOM 右下角的三个元素其实是没有变更的,但是因为其父节点的变更也导致了它们的重新渲染,多做了无用操作。
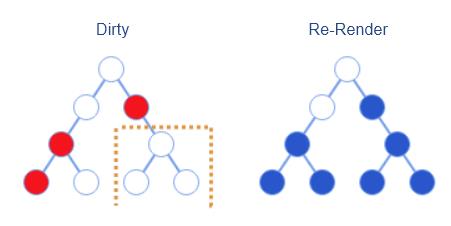
对于这种情况,React 本身已经考虑到了,为此它提供了 boolshouldComponentUpdate(nextProps,nextState) 接口。开发者可以手动实现该接口来对比前后状态和属性,以判断是否需要重新渲染。这样的话,重新渲染就变成如下图所示过程。
当时,React 虽然提供了 shouldComponentUpdate 接口,但是并没有提供一个默认的实现方案(总是渲染),开发者必须自己手动实现才能达到预期效果。
其原因是,在 JS 中,我们通常使用对象来保存状态,修改状态时是直接修改该状态对象的。也就是说,修改前后的两个不同状态指向了同一个对象,所以当直接比较两个对象是否变更时,它们是相同的,即使状态已经改变。
对此,David Nolen 提出了基于不可变数据结构(Immutable Data Structure)的解决方案。
该方案的灵感来自于 ClojureScript ,在 ClojureScript 中,大部分的值都是不可变的。换句话说就是,当需要更新一个值时,程序不是去修改原来的值,而是基于原来的值创建一个新值,然后使用新值进行赋值。
David 使用 ClojureScript 写了一个针对 React 的不可变数据结构方案:Om(https://github.com/omcljs/om) ,为 shouldComponentUpdate 提供了默认实现。
不过,由于不可变数据结构并未被 Web 工程师广为接受,所以当时并未把这项功能合并进 React 。
遗憾的是,截止到目前, shouldComponentUpdate 也仍然未提供默认实现。
但是 David 却为广大开发者开启了一个很好的研究方向。
如果真想利用不可变数据结构来提高 React 性能,可以参考与 React 师出同门的 Facebook Immutable.js(https://facebook.github.io/immutable-js/),它是 React 好搭档!
结束语
React 的优化仍在继续,比如 React 16 中新引入 Fiber(https://github.com/acdlite/react-fiber-architecture),它是对核心算法的一次重构,即重新设计了检测变更的方法和时机,允许渲染过程可以分段完成,而不必一次性完成。
受篇幅限制,本文不会深入介绍 Fiber ,有兴趣的可以参考:React Fiber 是什么(https://zhuanlan.zhihu.com/p/26027085) 。
最后,感谢 Facebook 给开源社区带来了如此优秀的项目!
推荐阅读:
1.
觉得本文对你有帮助?请分享给更多人
关注==>>「」,一起提升前端技能!
以上是关于React . js 是怎样炼成的?的主要内容,如果未能解决你的问题,请参考以下文章