领域驱动设计(DDD)实践之路(第二篇)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了领域驱动设计(DDD)实践之路(第二篇)相关的知识,希望对你有一定的参考价值。
参考技术A 在领域驱动里面,infrastructure作为基础设施,是提供技术细节的模块。需要强调的是,很多人会误以为infrastructure就是传统的DAO层,其实infrastructure包括但不限于DAO层,比如文件处理,三方调用,使用缓存,发送异步消息等具体的技术细节实现都存在于infrastructure层。那么技术细节是什么呢。在我们看来,技术细节包含以下特征案例1:我们的实体需要持久化(存储),所以我们需要提供存储的实现。领域层的repository.save等方法提供了持久化接口约定,对于infrastructure来说,如何实现这个方法的代码,就是技术细节。那么我们如何实现这个过程呢?自然是选择缓存,OSS存或者数据库存。如果选择数据库,则进而需要选择orm框架,配置...,实现repository.save的接口,这些都属于持久化所需的技术细节代码。
案例2:我们的应用需要导出资产包相关的excel形式数据,那么当导出资产包数据时,文件领域模块提供了导出的统一接口,资产领域模块提供了资产包的适配接口,而导出excel的代码需要使用easyExcel或者POI等第三方框架,属于技术细节代码。
案例3: 接案例2,为了实现导出时所需的excel排版格式,排版本身的格式与业务有关,比如在我们的业务场景下,我们导出调解明细(我们项目特定的一个领域模型)的时候,只需要按照常见的导出方式即可,而导出资产明细(我们项目特定的一个领域模型)则需要解析拼接所有的动态数据列,合并显示每条数据不同的动态列,而这一切是由业务决定的。根据业务不同有不同的排版要求这一点体现了资产域需要提供文件域的导出策略,调解域也需要实现文件域的导出策略。这些都属于描述业务信息的约定,而这些约定的具体实现比如怎么把实体的那一个属性映射到excel的哪一行哪一列,则属于技术细节。这种区分方式显性化了业务的概念,同时又将实现放在了基础设施层,提供了一定的解耦性。
说完了infrastructure的技术细节的定义,我们接下来聊几个在采用DDD研发模式下,infrastructure层开发过程中经常会遇到的一些问题及我们的解决方案。
为了让业务逻辑和代码实现解耦,在repository的约定中,我们通常用“save保存”代替我们通常说的“insert(插入)“,”update(更新)”这样的技术术语,以屏蔽技术细节。这样带来的一个副作用是,在save时就需要根据策略判断调用insert还是update,我们使用的策略是根据id是否是空决定,即我们所有的实体对象都有一个属性,类型为Id类的子类,id对象的属性(数据库里面实际存放的id值)可能为null,但是id对象,本身不会为null,根据这个对象可以判断当前实体id是否为空。
对于聚合场景,子实体是需要知道聚合根的id的,因为在存储到数据库时可能需要以外键的方式存储对象间的映射关系。
然而,在具体实现中,我们认为,实体之间的对象关系才是标识两个实体之间关系的方式,而不是id,所以生成实体时,先通过对象引用关联对象,表明聚合和实体之间的关系,在保存到数据库的时候,通过实体生成数据库映射类的时候就可以知道当前数据的id是否为空,同时又能知道当前数据之间的关系。
对象之间的关系在1:1聚合保存的时候可能体现不明显,但是当1:N或者N:N批量保存聚合的时候,作用就比较明显了。在我们的系统中发起调解业务就需要批量保存调解批次。代码如下(欢迎吐槽,拥抱进步)
通过这种方式就解决了批量插入不能返回id,同时又能继续复用id.isNew()判断是否为新数据的方式(这里我们没有创建entity基类,所以判断放在了Id上)。
以上方法提供了批量保存时如何区分是新增还是更新。下面我们来谈谈我们项目内提供的插入和更新模板代码。
对于领域来说,save是基本的保存代码。方法传入的参数往往是一个存在于内存中的聚合根对象,有时包含全量的子实体,VO和全量的字段,而在插入场景,对批量请求我们希望支持批量插入,减少对数据库的IO频率,在更新场景下,我们希望减少update时的更新字段的数量(只更新需要更新的字段),这有助于减少数据库IO次数、binlog大小和mysql数据库索引变更带来的开销,所以是非常有必要的。因此对于infrastructure来说,可以提供统一的定制化模板方便repository定制化更新字段的方法快速实现。
由于我们的系统使用的是mybatisplus的ORM方案,所以我们根据api和mysql的批量语句开关提供了一个批量插入和批量更新的Mapper基类,其中insertBatchSomColumn是mybatisplus自带的,updateBatchById则是我们实现的,文档链接如下https://mp.toutiao.com/profile_v4/graphic/preview?pgc_id=7062223527654916621通过这种方式可以轻松地提供定制化更新某几列的sql,减轻sql编写负担。
这一次要讲的其实就是上面提到过的excel导入导出的案例。对于我们的系统来说,具有资产域,文件域,调解域等。其中资产域、调节域等三个域需要导入导出excel。但是我们在设计的时候认为文件的操作属于文件域的概念,所以应当由文件的domain提供功能。但是很明显,具体的导入导出的策略根据数据的不同是可以变化的。所以针对这种情况,我们回归到领域驱动的实现的本质------面向对象技术来思考这个问题的优雅解法。以导入为例
代码如下
上面4份代码是domain的,最下面的是infrastructure的,这里我们只讲infrastructure的(但是我个人认为领域分层后还是需要整体考虑的,所以才会贴上domain的代码)。
这是我们对于跨域业务逻辑的处理办法。
为了保证各领域模型间的解耦,我们经常通过最轻量级的领域事件的方式实现,而不是类似metaq,msgbroker这样的异步分布式消息中间件。领域事件的发送有很多的实现方案,我们倾向于直接使用spring的功能,因为我们需要同步保证事务。但是spring的event发送需要继承ApplicationEvent而领域事件我们又希望独立于spring的event体系,所以我们通过对spring的了解发现了spring已经提供了 PayloadApplicationEvent 可以实现这种功能实现上和其他的spring的event一致,获取我们自己定义的event的方法如下
这里的getPayload()可以获取到我们放进去的领域事件TimeoutEvent
在任何系统中都会有批处理的业务。可能是批处理聚合,可能是批处理聚合内的实体类。这里说一下我之前遇到的一个帖子(jdon)上的讨论。帖子上说的是有一个排班业务,一条班表数据作为聚合存在着每日排班子实体,每日排班下又存在着排班明细子实体,当日期逐渐增加时一条排班需要加载好几年的数据用于生成聚合,而实际上则仅仅只需要计算最近几周的数据。这里存在两点问题
第一点自然不用多说,技术实现以提供业务功能为核心是我一直以来的主张。所以当数据量可能会不断增大的情况下不用加载完整自然是必须的(哪怕内存存储的下也应当尽可能少的消耗)。第二点来说帖子的一位回复者倾向于DomainService提供专门的适配方法,用于加载几周的数据。
我们的系统中存在一个有一些类似的业务。我们的系统需要每隔几分钟就运行一次批处理任务,获取所有已经过期的调解明细,并且设置为过期。调解明细属于调解批次的聚合,所以我们有同样的需求。
我们在此提供一种我们的实现,供参考。
repository的实现根据面向对象原则,仅仅提供如何查询过滤数据库数据
迭代器的实现提供了迭代职责实现
至此实现了批处理加载聚合的逻辑,同时可以提供聚合的部分加载(需要注意业务的正确性不会因为聚合的不完全加载而产生问题)。
最后总结一下
DDD领域驱动设计实践 —— Application层实现
本文是DDD框架实现讲解的第二篇,主要介绍了DDD的Application层的实现,详细讲解了service、assemble的职责和实现。文末附有github地址。相比于《领域驱动设计》原书中的航运系统例子,社交服务系统的业务场景对于大家更加熟悉,相信更好理解。本文是【DDD】系列文章的其中一篇,其他可参考:使用领域驱动设计思想实现业务系统
Application层
在DDD设计思想中,Application层主要职责为组装domain层各个组件及基础设施层的公共组件,完成具体的业务服务。Application层可以理解为粘合各个组件的胶水,使得零散的组件组合在一起提供完整的业务服务。在复杂的业务场景下,一个业务case通常需要多个domain实体参与进来,所以Application的粘合效用正好有了用武之地。
Application层主要由:service、assembler组成,下面分别对其做讲解。
Service
service是组件粘合剂
这里的Service区别于domain层的domain service,是应用服务。它是组件的粘合剂,组合domain层的各个组件和 infrastructure层的持久化组件、消息组件等等,完成具体的业务逻辑,提供完整的业务服务。
通过不断的实践,我们发现:通过DDD实现业务服务时,检验业务模型的质量的一个标准便是 —— service方法中不要有if/else。如果存在if/else,要么就是系统用例存在耦合,要么就是业务模型不够友好,导致部分业务逻辑泄漏到service了。
通常意义上,一个业务case在service层便会对应一个service方法,这样确保case实现的独立性。拿社区服务中的“帖子”模块来讲,我们有如下几个明显的case:发帖(posting)、删帖(deletePost)、查询帖子详情(queryPostDetail),这些case在service层都对应独立的业务方法。
思考
对于较为复杂的case:查询帖子列表,可能需要根据不同的tag过滤帖子,或者查询不同类型的帖子,或者查询热门帖子,这个时候应当用一个service方法实现呢?还是多个呢?
考虑这个问题,主要从这两方面入手:domain的一致性,数据存储的一致性;如果两个一致性都满足,那么我们可以在一个业务方法中完成,否则就要在独立的业务方法中完成。
例如:根据帖子运营标签查询帖子 和 查询全部帖子列表 这两个case我们可以放到一个service方法中实现,因为前一个case只是在后一个case的基础上加了一个过滤条件,这个过滤条件完全可以交给dao层的sql where条件处理掉,除此之外,domain和repository都完全一样;
而“查询热门帖子” 这个case就不能和上面的两个case共用一个service方法了,因为热门帖子列表的数据源并不在数据库中,而是存在于缓存中,因此repository的取数逻辑存在很大差异,如果共用一个service方法,势必要在service层出现if/else判定,这是不友好的。
类图
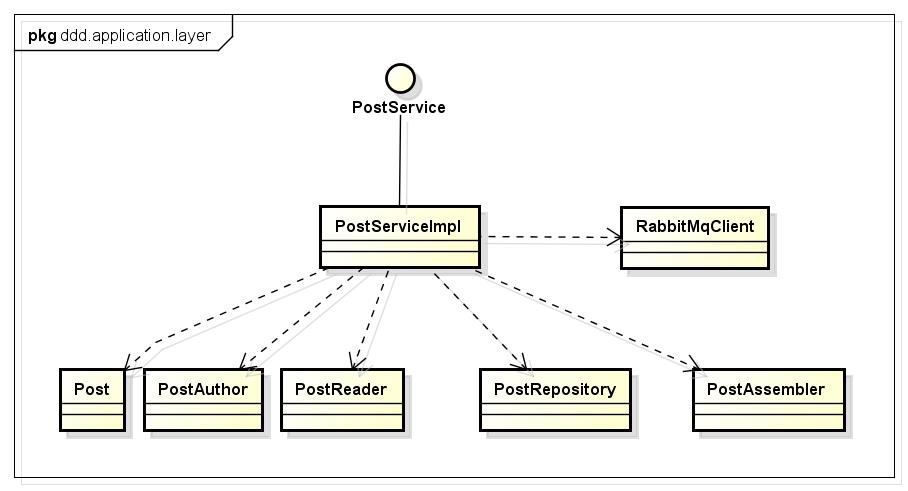
代码示例
1 @Service 2 public class PostServiceImpl implements PostService { 3 4 @Autowired 5 private IPostRepository postRepository; 6 7 @Autowired 8 private PostAssembler postAssembler; 9 10 11 12 public PostingRespBody posting(RequestDto<PostingReqBody> requestDto) throws BusinessException { 13 PostingReqBody postingReqBody = requestDto.getBody(); 14 /** 15 *NOTE: 请求参数校验交给了validation,这里无需校验userId和postId是否为空 16 */ 17 String userId = postingReqBody.getUserId(); 18 String title = postingReqBody.getTitle(); 19 String sourceContent = postingReqBody.getSourceContent(); 20 21 long userIdInLong = Long.valueOf(userId); 22 23 /** 24 * 组装domain model entity 25 * NOTE:这里的PostAuthor不需要从repository重载,原因在于:deletePost场景需要用户登录后才能操作, 26 * 在进入service之前,已经在controller层完成了用户身份鉴权,故到达这里的userId肯定是合法的用户 27 */ 28 PostAuthor postAuthor = new PostAuthor(userIdInLong); 29 Post post = postAuthor.posting(title, sourceContent); 30 31 /** 32 * NOTE:使用repository将model entity 写入存储 33 */ 34 postRepository.save(post); 35 36 /** 37 * NOTE:使用postAssembler将Post model组装成dto返回。 38 */ 39 return postAssembler.assemblePostingRespBody(post); 40 } 41 42 43 public DeletePostRespBody delete(RequestDto<DeletePostReqBody> requestDto) throws BusinessException { 44 DeletePostReqBody deletePostReqBody = requestDto.getBody(); 45 46 /** 47 *NOTE: 请求参数校验交给了validation,这里无需校验userId和postId是否为空 48 */ 49 String userId = deletePostReqBody.getUserId(); 50 String postId = deletePostReqBody.getPostId(); 51 52 long userIdInLong = Long.valueOf(userId); 53 long postIdInLong = Long.valueOf(postId); 54 55 /** 56 * 组装domain model entity 57 * NOTE:这里的PostAuthor不需要从repository重载,原因在于:deletePost场景需要用户登录后才能操作, 58 * 在进入service之前,已经在controller层完成了用户身份鉴权,故到达这里的userId肯定是合法的用户 59 */ 60 PostAuthor postAuthor = new PostAuthor(userIdInLong); 61 /** 62 * 从repository中重载domain model entity 63 * 借此判断该postId是否真的存在帖子 64 */ 65 Post post = postRepository.query(postIdInLong); 66 67 postAuthor.deletePost(post); 68 69 postRepository.delete(post); 70 71 return null; 72 } 73 74 75 @Override 76 public QueryPostDetailRespBody queryPostDetail(RequestDto<QueryPostDetailReqBody> requestDto) 77 throws BusinessException { 78 QueryPostDetailReqBody queryPostDetailReqBody = requestDto.getBody(); 79 80 String readerId = queryPostDetailReqBody.getReaderId(); 81 String postId = queryPostDetailReqBody.getPostId(); 82 83 long readerIdInLong = Long.valueOf(readerId); 84 long postIdInLong = Long.valueOf(postId); 85 86 //TODO 可能有一些权限校验,比如:判定该读者是否有查看作者帖子的权限等。这里暂且不展开讨论。 87 PostReader postReader = new PostReader(readerIdInLong); 88 89 Post post = postRepository.query(postIdInLong); 90 91 /** 92 * NOTE: 使用postAssembler将domain层的model组装成dto,组装过程: 93 * 1、完成类型转换、数据格式化; 94 * 2、将多个model组合成一个dto,一并返回。 95 */ 96 return postAssembler.assembleQueryPostDetailRespBody(post); 97 } 98 99 }
Assembler
Assembler是组装器
Assembler是组装器,负责完成domain model对象到dto的转换,组装职责包括:
- 完成类型转换、数据格式化;如日志格式化,状态enum装换为前端认识的string;
- 将多个domain领域对象组装为需要的dto对象,比如查询帖子列表,需要从Post(帖子)领域对象中获取帖子的详情,还需要从User(用户)领域对象中获取用户的社交信息(昵称、简介、头像等);
- 将domain领域对象属性裁剪并组装为dto;某些场景下,可能并不需要所有domain领域对象的属性,比如User领域对象的password属性属于隐私相关属性,在“查询用户信息”case中不需要返回,需要裁剪掉。
示例代码
1 /** 2 * Post模块的组装器,完成domain model对象到dto的转换,组装职责包括: 3 * 1、完成类型转换、数据格式化;如日志格式化,状态enum装换为前端认识的string; 4 * 2、将多个model组合成一个dto,一并返回。 5 * TODO: 不太好的地方每个assemble方法都需要先判断入参对象是否为空。 6 * @author daoqidelv 7 * @createdate 2017年9月24日 8 */ 9 @Component 10 public class PostAssembler { 11 12 private final static String POSTING_TIME_STRING_DATE_FORMAT = "yyyy-MM-dd hh:mm:ss"; 13 14 @Autowired 15 private ApplicationUtil applicationUtil; 16 17 public PostingRespBody assemblePostingRespBody(Post post) { 18 if(post == null) { 19 return null; 20 } 21 PostingRespBody postingRespBody = new PostingRespBody(); 22 postingRespBody.setPostId(String.valueOf(post.getId())); 23 return postingRespBody; 24 } 25 26 public QueryPostDetailRespBody assembleQueryPostDetailRespBody(Post post) { 27 /** 28 * NOTE: 判定入参post是否为null 29 */ 30 if(post == null) { 31 return null; 32 } 33 QueryPostDetailRespBody queryPostDetailRespBody = new QueryPostDetailRespBody(); 34 queryPostDetailRespBody.setAuthorId(String.valueOf(post.getAuthorId())); //完成类型转换 35 queryPostDetailRespBody.setPostId(String.valueOf(post.getId()));//完成类型转换 36 queryPostDetailRespBody.setPostingTime( 37 applicationUtil.convertTimestampToString(post.getPostingTime(), POSTING_TIME_STRING_DATE_FORMAT));//完成日期格式化 38 queryPostDetailRespBody.setSourceContent(post.getSourceContent()); 39 queryPostDetailRespBody.setTitle(post.getTitle()); 40 return queryPostDetailRespBody; 41 } 42 43 }
思考
上述代码实现中,每一个assemble方法都需要校验入参对象是否为空,实践中发现,这一个关键点很容易遗漏,没有想到好的办法解决。
类图
demo
此demo的代码已上传至github,欢迎下载和讨论,但拒绝被用于任何商业用途。
github地址:https://github.com/daoqidelv/community-ddd-demo/tree/master
branch:master
以上是关于领域驱动设计(DDD)实践之路(第二篇)的主要内容,如果未能解决你的问题,请参考以下文章