基于centos7的hadoop2.7zookeeper3.5hbase1.3spark2.3scala2.11kafka2.11hive3.1flume1.8sqoop1.4组件部署
Posted luoz_python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于centos7的hadoop2.7zookeeper3.5hbase1.3spark2.3scala2.11kafka2.11hive3.1flume1.8sqoop1.4组件部署相关的知识,希望对你有一定的参考价值。
部署前准备
修改主机名
1、修改主机名(6台机器都要操作,以Master为举例)
hostnamectl set-hostname Master(永久修改主机名)
reboot(重启系统)
修改hosts
将第一行127.0.0.1 xxxx注释掉,加上:
195.168.2.127 master
195.168.2.128 slave1
195.168.2.129 slave2
确认网卡信息
vi /etc/sysconfig/network-scripts/ifcfg.ens0
BOOTRPROTO=static
IPADDR=192.168.2.127
NETMASK=255.255.255.0
GATEWAY=192.168.2.1
DNS1=192.168.2.1
DNS2=8.8.8.8
NAME=ens32
ONBOOT=yes
DEVICE=ens32
systemctl restart network
修改以上三个后> reboot
重启后确认IP是否都是设置那样了
ssh
1、 ssh生成密钥(6台机器都要操作)
ssh-keygen -t rsa (连续三次回车)
2、将3台的id_rsa_pub合并到一个authorized_keys上
分别登陆slave1、slave2,输入:
> scp .ssh/id_rsa.pub master:/home/kfs/.ssh/id_rsa_slave1
> scp .ssh/id_rsa.pub master:/home/kfs/.ssh/id_rsa_slave2
在master输入:
> cat ~/.ssh/id_rsa* >> authorized_keys
> scp .ssh/ authorized_keys slave1:/home/kfs/.ssh/
> scp .ssh/ authorized_keys slave2:/home/kfs/.ssh/
每台都修改权限:
> chmod 600 authorized_keys
- 每台各自登陆
(首次ssh会输入yes,所以需要进行这一步)
slave1、salve2同样进行以上步骤
防火墙
systemctl stop firewalld.service
安装jdk
卸载原来的jdk
1、安装jdk之前,先检查是否已经安装了open的jdk,有的话需要先卸载(6台机器都要卸载)
java -version
2、查看有jdk的存在,需要先卸载然后再安装oracle的jdk
rpm -qa | grep java (查询java版本)
3、rpm -e --nodeps xxx (逐个删除完)
解压配置新的JDK
1、登陆kfs用户,解压到/home/kfs/下
> tar- zxvf jdk-8u144-linux-x64.tar.gz -C ~/
2、.jdk的环境变量配置(使用的是在root目录下的全局配置文件/etc/profile,6台机器都要配置,master举例)
> vi ~/.bashrc
export JAVA_HOME=/home/kfs/jdk1.8.0_141
export PATH=$PATH:$JAVA_HOME/bin
保存退出之后使用命令让配置生效
> source /etc/profile
验证版本
>java -version
安装架构
安装的软件明细
| JDK | scala | hadoop | hive | sqoop | zookeeper | hbase | flume | spark | kafka | ||
| Master | √ | √ | √ | √ | √ | √ | √ | √ | |||
| Slave1 | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ | √ |
| Slave2 | √ | √ | √ | √ | √ | √ | √ | √ |
安装的软Hadoop HA件明细
| QuorumPeerMain | journalnode | namenode | nodemanager | DFSZKFailover | datanode | resourcemanager | |
| master | √ | √ | √ | √ | √ | √ | |
| slave1 | √ | √ | √ | √ | √ | √ | √ |
| slave2 | √ | √ | √ | √ | √ |
服务说明
QuorumPeerMain
是zookeeper集群的启动类,用于加载配置启动QuorumPeer线程,确定了基于paxos算法的zookeeper集群数量;QuorumPeer线程是zookeeper的Laeder选举的启动类,负责选举算法、zk数据恢复、启动leader选举等。
在zookeeper/conf/zoo.cfg server.x个数确定;
启动不起来,根据报错信息排查zoo.cfg的server.x=master:2888:3888、dataDir=xx是否包含myid(从1开始)。
Journalnode
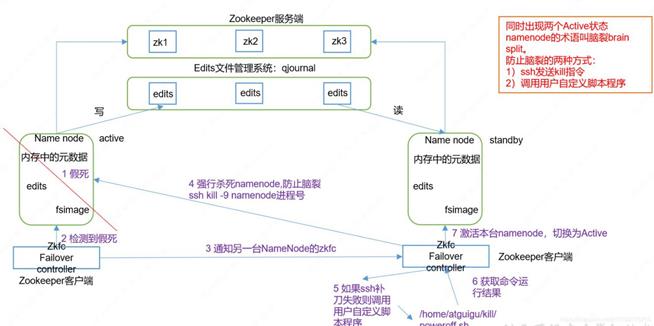
实现两个NameNode之间的数据同步,通过一组JournalNodes(JNs)的独立进程进行相互通信,当active状态的namenode的命名空间有变化,会通知大部分的JournalNode进程。Standby的namenode有能力读取JNs的变更信息,并监控edit log的变化,同时将变化应用于自己的命名空间,保证了集群出错时,acitive和standby的空间状态是一致的。
Namenode
负责客户端(web)请求的相应;元数据的管理、查询。
启动时,将fsimage(镜像)载入到内存,并执行(replay)编辑日志editlog的各项操作;一旦在内存建立文件系统元数据映射,则创建一个新的fsimage文件(元数据镜像文件:保存文件系统的目录树)、一个空的editlog(元数据操作日志:针对目录树的修改操作)文件;
开始监听RPC和HTTP请求。
DFSZKFailover
Failover故障转移需要两个组件:Zookeeper quorum(仲裁:驱动ZKFC的运转)、ZKFCFailoverController进程(ZKFC)。
ZKFC:每个NameNode上运行的zookeeper一个zookeeper进程,主要是监控namenode的健康状态、zookeeper会话管理、基于zookeeper的选举。
Datanode
负责管理所在节点上存储的数据读写,及存储数据;每三秒datanode节点向namenode发送心跳信号和文件块状态报告;执行数据的流水线复制。

Resourcemanager & Nodemanager & ApplicationMasters
1、ResourceManager(RM),是集群资源的仲裁者,它包括两部分:一个是可插拔式的调度Scheduler,一个是ApplicationManager,用于管理集群中的用户作业。
2、NodeManagers (NMs)从ResourceManager获取指令并管理本节点的可用资源(Container使用情况)
3、ApplicationMasters (AMs)的职责是从ResourceManager谈判资源(Containers),为NodeManagers启动容器,并且和NodeManager交互来执行和监控具体的task。
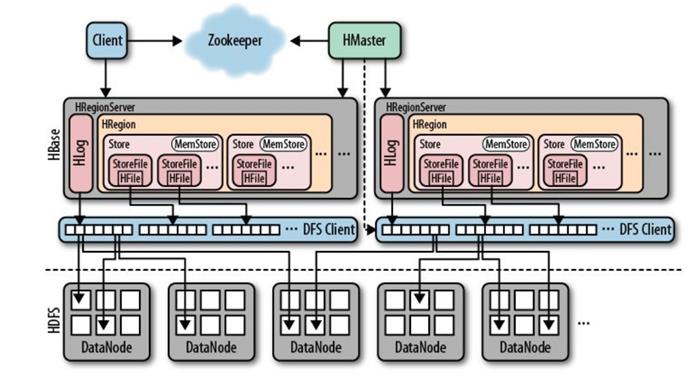
Hmaster & HRegionserver
Hmaster 作用:管理用户对table表的增删改查;管理HRegion服务器的负载均衡,调整HRegion的分布;在HRgion分裂后,负责新的HRegion的分配;HRegion停机后,负责失效HRegion服务器上HRegion的迁移。
HRegionsServer一般和DataNode在同台机器运行,实现数据的本地行。HRegionsServer包含多个HRegion,由HLog(副本机制,防止hbase宕机)、BlockCache(读缓存,默认 on-heap LRUBlockCache 和 BucketCache)、HStore(HBase的存储核心,memStore和storeFile组成)、HFile(HbasekeyValue数据、Hadoop的二进制)组成。
jobhistory & historyServer
historyServer同时启动两个定时任务线程,分别解析eventLog和清理过期的eventLog日志文件,默认18080.
Runjar(metadata、metastore、hiveserver2)
metadata(需要初始化):hive元数据定义的表名,一般存在mysql中,在测试阶段也可以用hive内置Derby数据库。
metastore:hivestore服务端。主要提供将DDL,DML等语句转换为MapReduce,提交到hdfs中。默认监听端口是:9083
hiveserver2:hive服务端,提供hive服务,可以通过beeline、jdbc(java代码连接)等多种方式多客户端连接到hive。基于Thrift RPC的实现是HiveServer的改进版本。默认10002端口,可以master:10002/jmx获取指标。
端口列表
| 组件 | Daemon | 端口 | 配置 | 说明 |
| HDFS | DataNode | 50010 | dfs.datanode.address | datanode服务端口,用于数据传输 |
| 50075 | dfs.datanode.http.address | http服务的端口 | ||
| 50475 | dfs.datanode.https.address | https服务的端口 | ||
| 50020 | dfs.datanode.ipc.address | ipc服务的端口 | ||
| NameNode | 50070 | dfs.namenode.http-address | http服务的端口 | |
| 50470 | dfs.namenode.https-address | https服务的端口 | ||
| 8020 | fs.defaultFS | 接收Client连接的RPC端口,用于获取文件系统metadata信息。 | ||
| journalnode | 8485 | dfs.journalnode.rpc-address | RPC服务 | |
| 8480 | dfs.journalnode.http-address | HTTP服务 | ||
| ZKFC | 8019 | dfs.ha.zkfc.port | ZooKeeper FailoverController,用于NN HA | |
| YARN | ResourceManager | 8032 | yarn.resourcemanager.address | RM的applications manager(ASM)端口 |
| 8030 | yarn.resourcemanager.scheduler.address | scheduler组件的IPC端口 | ||
| 8031 | yarn.resourcemanager.resource-tracker.address | IPC | ||
| 8033 | yarn.resourcemanager.admin.address | IPC | ||
| 8088 | yarn.resourcemanager.webapp.address | http服务端口 | ||
| NodeManager | 8040 | yarn.nodemanager.localizer.address | localizer IPC | |
| 8042 | yarn.nodemanager.webapp.address | http服务端口 | ||
| 8041 | yarn.nodemanager.address | NM中container manager的端口 | ||
| JobHistory Server | 10020 | mapreduce.jobhistory.address | IPC | |
| 19888 | mapreduce.jobhistory.webapp.address | http服务端口 | ||
| HBase | Master | 60000 | hbase.master.port | IPC |
| 60010 | hbase.master.info.port | http服务端口 | ||
| RegionServer | 60020 | hbase.regionserver.port | IPC | |
| 60030 | hbase.regionserver.info.port | http服务端口 | ||
| HQuorumPeer | 2181 | hbase.zookeeper.property.clientPort | HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 | |
| Hive | Metastore | 9083 | /etc/default/hive-metastore中export PORT=<port>来更新默认端口 | |
| HiveServe2r | 10002 | /etc/hive/conf/hive-env.sh中export HIVE_SERVER2_THRIFT_PORT=<port>来更新默认端口 | ||
| ZooKeeper | Server | 2181 | /etc/zookeeper/conf/zoo.cfg中clientPort=<port> | 对客户端提供服务的端口 |
| 2888 | /etc/zookeeper/conf/zoo.cfg中server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 | follower用来连接到leader,只在leader上监听该端口。 | ||
| 3888 | /etc/zookeeper/conf/zoo.cfg中server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 | 用于leader选举的。只在electionAlg是1,2或3(默认)时需要。 |
安装zookeeper
单数台10-3、20-5,选举的半数机制保证运行
解压、配置一个配置文件conf/下cp zoo_sample.cfg zoo.cfg、根目录下新建两个文件夹data log、data下新建文件myid内容为1或2(不同主机不同myid)..
dataDir=/home/kfs/zookeeper-3.4.5/data
dataLogDir=/home/kfs/zookeeper-3.4.5/log
clientPort=2181
server.1=master:2888:3888
server.2=salve1:2888:3888
server.3=salve1:2888:3888
> echo “1” > data/myid
不用在profile增加环境变量,运行都是bin/zkServer.sh start
安装hadoop
先对一个进行配制好,然后scp到集群每台上运行
四个配置文件core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves
在hadoop-2.8.4/etc/hadoop下
core-site.xml

hdfs-site.xml
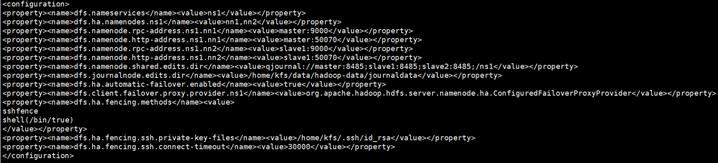

mapred-site.xml


yarn-site.xml
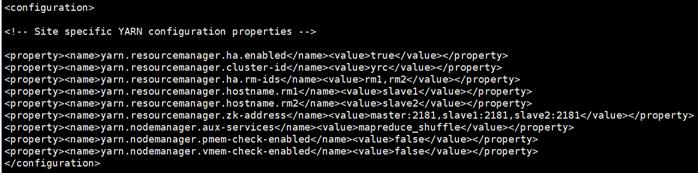
yarn.nodemanager.aux-services mapreduce_shuffle
yarn.resourcemanager.recovery.enabled true
yarn.resourcemanager.store.class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.nodemanager.resource.memory-mb 8192
yarn.nodemanager.resource.cpu-vcores 8
yarn.scheduler.maximum-allocation-mb 8192
yarn.scheduler.maximum-allocation-vcores 4
slaves
两个脚本文件设置java环境:hadoop-env.sh、yarn-env.sh

需要主要windows复制过去的话,换行符的格式的问题。
vi **.sh
set ff=unix
sed -i “s/\\r//” **.sh
kfs用户修改/home/kfs/.bashrc文件

> source /home/kfs/.bashrc
新建文件夹hadoop.tmp.dir、dfs.journalnode.edits.dir的目录
> mkdir /home/kfs/data/hadoop-data/tmp
> mkdir /home/kfs/data/hadoop-data/journaldata
启动(包括zookeeper)
首次启动
1、首先启动各个节点的Zookeeper,在各个节点上执行以下命令:
> bin/zkServer.sh start
2、在每个journalnode节点用如下命令启动journalnode
> sbin/hadoop-daemon.sh start journalnode
3、在主namenode节点格式化namenode和journalnode目录
> hdfs namenode -format ns
4、在主namenode节点启动namenode进程
> sbin/hadoop-daemon.sh start namenode
5、在备namenode节点执行第一行命令,这个是把备namenode节点的目录格式化并把元数据从主namenode节点copy过来,并且这个命令不会把journalnode目录再格式化了!然后用第二个命令启动备namenode进程!
> hdfs namenode -bootstrapStandby
> sbin/hadoop-daemon.sh start namenode
6、在某一个namenode节点执行如下命令,创建命名空间
> hdfs zkfc -formatZK
7、在两个namenode节点都执行以下命令
> sbin/hadoop-daemon.sh start zkfc
8、启动dfs
> sbin/start-all.sh
9、启动备regionserver
> sbin/yarn-daemon.sh start resourcemanager
用jps查看一下起的进程是否正确
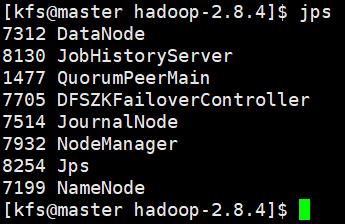

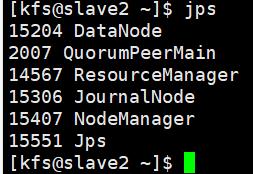
后续启动
(zookeeper)节点启动:zookeeper/bin/zkServer.sh start
(yarn)两个rm节点分别运行:hadoop-2.8.4/sbin/yarn-daemon.sh start resourcemanager
(yarn)在主或者备节点启动:hadoop-2.8.4/sbin/start-yarn.sh
(zkfc namenode datanode)所有:hadoop-2.8.4/sbin/start-all.sh
确保每个zookeeper集群启动成功后,再启动dfs,这个步骤可能需要多次;
停止stop-dfs.sh、stop- yarn.sh、stop-all.sh
(Historyserver)Historyserver:sbin/mr-jobhistory-daemon.sh start/stop historyserver
可访问的地址
Hadoop hdfs:http:// slave1:50070/dfshealth.html#tab-overview
一个active,一个standy
Hadoop hdfs datanode : http://slave1:50075/datanode.html
Hadoop yarn resourcemanager:http://master:8088
如果配置了mapreduce的historyserver
则通过./sbin/mr-jobhistory-daemon.sh start/stop historyserver

实操
hadoop fs(使用范围最广,对象:可任何对象);hdfs dfs(只HDFS文件系统相关,常用),下面测试两者一样。
创建三个测试文件

创建目录,将测试文本Put到目录上
#本地的/home/hdfs/input/文件夹下有多个txt文件,每个单词单独一行
hadoop fs -mkdir -p /hadoop/test
hadoop fs -ls /hadoop/test/
hadoop fs -put test/* /hadoop/test/
运行测试(testout不能存在)
hadoop-mapreduce-examples-2.7.0.jar在路径share/hadoop/mapreduce下
yarn jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.4.jar wordcount /hadoop/test /hadoop/testout
hadoop dfs -ls /hadoop/testout
hadoop dfs -cat /hadoop/testout/part-r-00000
hadoop fs -rm -r -skipTrash /hadoop/testout

原理
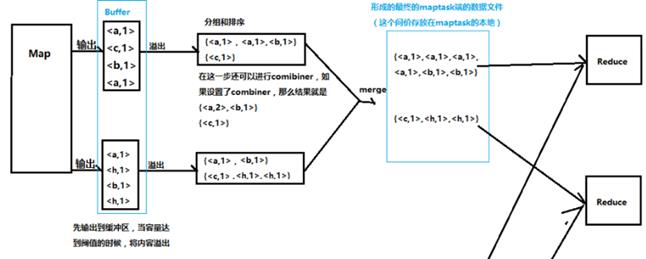
Yarn

Hdfs
mapreduce.map.java.opts控制maptask堆内存大小。(不够会报错 java.lang.outofmemoryerror)
安装hbase(scp每台都需要启动)
/home/data目录下创建hbase-data存放hbase的数据 data和log、pids、tmp

修改hbase-site.xml、hbase-env.sh、regionservers
hbase-site.xml
