芯片设计|FPGA 设计的指导原则
Posted IC观察者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了芯片设计|FPGA 设计的指导原则相关的知识,希望对你有一定的参考价值。
我们接上一期的[FPGA 设计的指导原则(一)给大家讲解FPGA 设计的指导原则。
当评估完系统的流水线时间余量后,发现整个流水线有 16 个时钟周期,而 FHT 模块的频率很高,加法本身仅仅消耗 1 个时钟周期,加上数据的选择和分配所消耗时间,也能完全满足频率要求,所以将单步 FHT 运算复用 4 次,就能大幅度节约所消耗的资源。这种复用单步算法的 FHT 实现框图如图 1-2 所示,由输入选择寄存、单步 FHT 模块、输出选择寄存、计数器构成。

代码如下:
//复用单步算法的 FHT 运算模块
module wch_fht(Clk,Reset,
PreFhtStar,
In0,In1,In2,In3,In4,In5,In6,In7,
In8,In9,In10,In11,In12,In13,In14,In15,
Out0,Out1,Out2,Out3,Out4,Out5,Out6,Out7,Out8,
Out9,Out10,Out11,Out12,Out13,Out14,Out15
);
input Clk; //设计的主时钟
input Reset; //异步复位信号
input PreFhtStar; //FHT 运算指示信号,和上级模块运算关联
input [11:0] In0,In1,In2,In3,In4,In5,In6,In7;
input [11:0] In8,In9,In10,In11,In12,In13,In14,In15; //FHT 的 16 个输入
output [15:0] Out0,Out1,Out2,Out3,Out4,Out5,Out6,Out7;
output [15:0] Out8,Out9,Out10,Out11,Out12,Out13,Out14,Out15; //FHT 的 16 个输出
//FHT 输出寄存信号
reg [15:0] Out0,Out1,Out2,Out3,Out4,Out5,Out6,Out7;
reg [15:0] Out8,Out9,Out10,Out11,Out12,Out13,Out14,Out15;
//FHT 的中间结果
wire [15:0] Temp0,Temp1,Temp2,Temp3,Temp4,Temp5,Temp6,Temp7;
wire [15:0] Temp8,Temp9,Temp10,Temp11,Temp12,Temp13,Temp14,Temp15;
//FHT 运算控制计数器,和前一级流水线模块配合
reg [2:0] Cnt3;//count from 0 to 4,when Reset Cnt3=7;
reg FhtEn;//Enable fht culculate
always @(posedge Clk or negedge Reset)
begin
if (!Reset)
Cnt3<= #1 3'b111;
else
begin if(PreFhtStar)
Cnt3<= #1 3'b100;
else
Cnt3<= #1 Cnt3-1;
end
end
always @(posedge Clk or negedge Reset)
if (!Reset)
FhtEn<= #1 0;
else
begin
if (PreFhtStar)
FhtEn<= #1 1;
if (Cnt3==1)
FhtEn<= #1 0;
end
//补码运算,复制符号位
assign Temp0=(Cnt3==4)?4In0[11],In0:Out0;
assign Temp1=(Cnt3==4)?4In1[11],In1:Out1;
assign Temp2=(Cnt3==4)?4In2[11],In2:Out2;
assign Temp3=(Cnt3==4)?4In3[11],In3:Out3;
assign Temp4=(Cnt3==4)?4In4[11],In4:Out4;
assign Temp5=(Cnt3==4)?4In5[11],In5:Out5;
assign Temp6=(Cnt3==4)?4In6[11],In6:Out6;
assign Temp7=(Cnt3==4)?4In7[11],In7:Out7;
assign Temp8=(Cnt3==4)?4In8[11],In8:Out8;
assign Temp9=(Cnt3==4)?4In9[11],In9:Out9;
assign Temp10=(Cnt3==4)?4In10[11],In10:Out10;
assign Temp11=(Cnt3==4)?4In11[11],In11:Out11;
assign Temp12=(Cnt3==4)?4In12[11],In12:Out12; assign Temp13=(Cnt3==4)?4In13[11],In13:Out13;
assign Temp14=(Cnt3==4)?4In14[11],In14:Out14;
assign Temp15=(Cnt3==4)?4In15[11],In15:Out15;
always @(posedge Clk or negedge Reset)
begin
if (!Reset)
begin
Out0<=0;Out1<=0;Out2<=0;Out3<=0;
Out4<=0;Out5<=0;Out6<=0;Out7<=0;
Out8<=0;Out9<=0;Out10<=0;Out11<=0;
Out12<=0;Out13<=0;Out14<=0;Out15<=0;
end
else
begin
if ((Cnt3<=4) && Cnt3>=0 && FhtEn)
begin
Out0[15:0]<= #1 Temp0[15:0]+Temp8[15:0];
Out1[15:0]<= #1 Temp0[15:0]-Temp8[15:0];
Out2[15:0]<= #1 Temp1[15:0]+Temp9[15:0];
Out3[15:0]<= #1 Temp1[15:0]-Temp9[15:0];
Out4[15:0]<= #1 Temp2[15:0]+Temp10[15:0];
Out5[15:0]<= #1 Temp2[15:0]-Temp10[15:0];
Out6[15:0]<= #1 Temp3[15:0]+Temp11[15:0];
Out7[15:0]<= #1 Temp3[15:0]-Temp11[15:0];
Out8[15:0]<= #1 Temp4[15:0]+Temp12[15:0];
Out9[15:0]<= #1 Temp4[15:0]-Temp12[15:0];
Out10[15:0]<= #1 Temp5[15:0]+Temp13[15:0];
Out11[15:0]<= #1 Temp5[15:0]-Temp13[15:0];
Out12[15:0]<= #1 Temp6[15:0]+Temp14[15:0];
Out13[15:0]<= #1 Temp6[15:0]-Temp14[15:0]; Out14[15:0]<= #1 Temp7[15:0]+Temp15[15:0];
Out15[15:0]<= #1 Temp7[15:0]-Temp15[15:0];
end
end
end
endmodule
为了便于对比两种实现方式的资源消耗,我在 Synplify Pro 对两种实现方法分别做了综合。两次综合选用的参数都完全一致,器件类型为:Xilinx Virtex-E XCV100E -6 BG352,出于仅仅考察设计所消耗的寄存器和逻辑资源,Enable“Disable I/O Insertion”选项,不插入 IO,取消 Synplify Pro 中诸如“FSM Compiler”、“FSM Explorer”、“Resource Sharing”、“Retiming”、“Pipelining”等综合优化选项。两次综合的结果如图 1-3,图 1-4 所示。
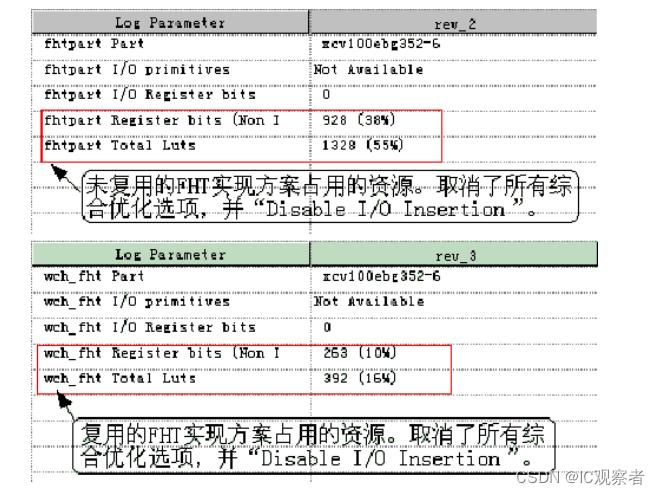
通过对比可以清晰的观察到,采样复用实现方案所占面积约为原方案的 1/4,而得到这个好处的代价是:完成整个 FHT 运算的周期为原来的 4 倍。这个例子通过运算周期的加长,换取了消耗芯片面积的减少,是前面所述的用频率换面积的一种体现。https://ic.coachip.cn/resource/detail/99 这块也给大家详细介绍过。本例所述“频率换面积”的前提是:FHT 模块频率较高,运算周期的余量较大,采用 4 步复用后,仍然能够满足系统流水线设计的要求。其实,如果流水线时序允许,FHT 运算甚至可以采用 1bit 全串行方案实现,该方案所消耗的芯片面积资源更少!
例 2:如何使用“面积复制换速度提高”?
举一个路由器设计的一个例子。假设输入数据流的速率是 350Mb/s,在而 FPGA 上设计的数据处理模块的处理速度最大为 150Mb/s,由于处理模块的数据吞吐量满足不了要求,看起来直接在 FPGA 上实现是一个“impossible mission”。这种情况下,就应该利用“面积换速度”的思想,至少复制 3 个处理模块,首先将输入数据进行串并转换,然后利用这三个模块并行处理分配的数据,然后将处理结果“并串变换”,就完成数据速率的要求。我们在整个处理模块的两端看,数据速率是 350Mb/s,而在 FPGA 的内部看,每个子模块处理的数据速率是 150Mb/s,其实整个数据的吞吐量的保障是依赖于 3 个子模块并行处理完成的,也就是说占用了更多的芯片面积,实现了高速处理,通过“面积的复制换取处理速度的提高”的思想实现了设计。设计的示意框图如图 1-5 所示。
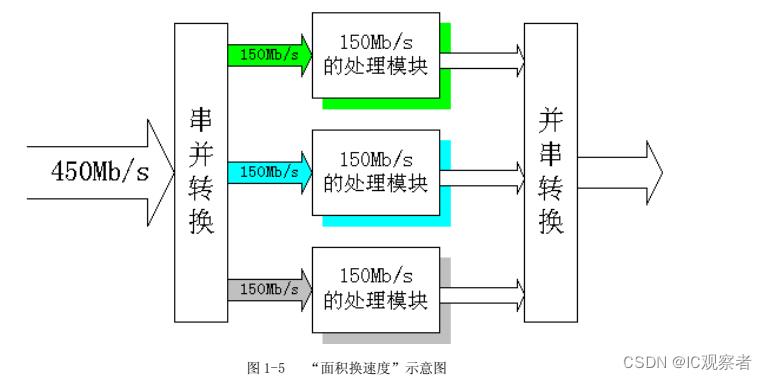
上面仅仅是对“面积换速度”思想的一个简单的举例,其实具体操作过程中还涉及很多的方法和技巧,例如,对高速数据流进行串并转换,采用“乒乓操作”方法提高数据处理速率等。希望读者通过平时的应用进一步积累。
如果大家比较感兴趣,下期会给大家更新基本原则之二:硬件原则。
以上是关于芯片设计|FPGA 设计的指导原则的主要内容,如果未能解决你的问题,请参考以下文章