索引15连问
Posted 捡田螺的小男孩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了索引15连问相关的知识,希望对你有一定的参考价值。
前言
大家好,我是田螺。
金三银四很快就要来啦,准备了索引的15连问,相信大家看完肯定会有帮助的。
公众号:捡田螺的小男孩
1. 索引是什么?
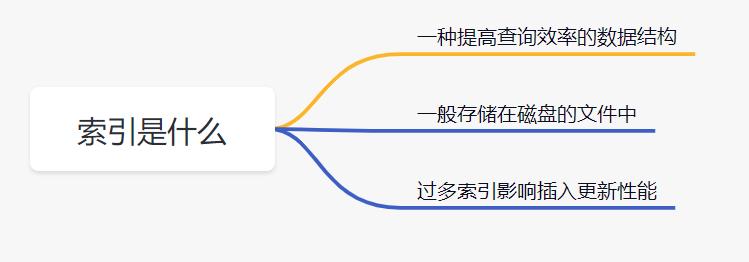
- 索引是一种能提高数据库查询效率的数据结构。它可以比作一本字典的目录,可以帮你快速找到对应的记录。
- 索引一般存储在磁盘的文件中,它是占用物理空间的。
- 正所谓水能载舟,也能覆舟。适当的索引能提高查询效率,过多的索引会影响数据库表的插入和更新功能。
2. mysql索引有哪些类型
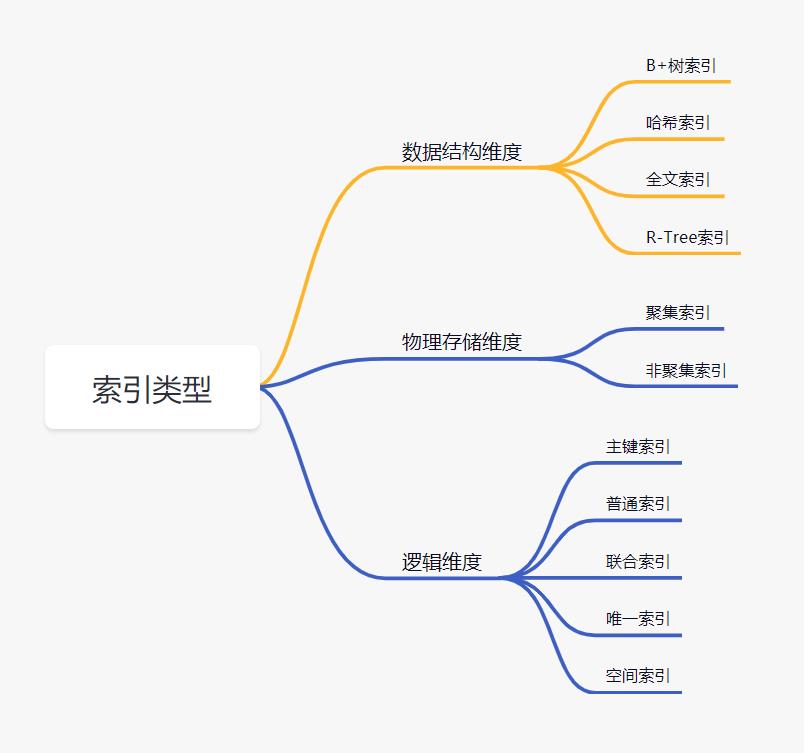
数据结构维度
- B+树索引:所有数据存储在叶子节点,复杂度为
O(logn),适合范围查询。 - 哈希索引: 适合等值查询,检索效率高,一次到位。
- 全文索引:
MyISAM和InnoDB中都支持使用全文索引,一般在文本类型char,text,varchar类型上创建。 R-Tree索引: 用来对GIS数据类型创建SPATIAL索引
物理存储维度
- 聚集索引:聚集索引就是以主键创建的索引,在叶子节点存储的是表中的数据。(
Innodb存储引擎) - 非聚集索引:非聚集索引就是以非主键创建的索引,在叶子节点存储的是主键和索引列。(
Innodb存储引擎)
逻辑维度
- 主键索引:一种特殊的唯一索引,不允许有空值。
- 普通索引:
MySQL中基本索引类型,允许空值和重复值。 - 联合索引:多个字段创建的索引,使用时遵循最左前缀原则。
- 唯一索引:索引列中的值必须是唯一的,但是允许为空值。
- 空间索引:
MySQL5.7之后支持空间索引,在空间索引这方面遵循OpenGIS几何数据模型规则。
3. 索引什么时候会失效?
- 查询条件包含
or,可能导致索引失效 - 如果字段类型是字符串,
where时一定用引号括起来,否则索引失效 like通配符可能导致索引失效。- 联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
- 在索引列上使用 mysql 的内置函数,索引失效。
- 对索引列运算(如,
+、-、*、/),索引失效。 - 索引字段上使用
(!= 或者 < >,not in)时,可能会导致索引失效。 - 索引字段上使用
is null, is not null,可能导致索引失效。 - 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
- mysql 估计使用全表扫描要比使用索引快,则不使用索引。
4. 哪些场景不适合建立索引?
- 数据量少的表,不适合加索引
- 更新比较频繁的也不适合加索引
- 区分度低的字段不适合加索引(如性别)
where、group by、order by等后面没有使用到的字段,不需要建立索引- 已经有冗余的索引的情况(比如已经有
a,b的联合索引,不需要再单独建立a索引)
5. 为什么要用 B+树,为什么不用二叉树?
可以从几个维度去看这个问题,查询是否够快,效率是否稳定,存储数据多少,
以及查找磁盘次数,为什么不是二叉树,为什么不是平衡二叉树,为什么不是
B 树,而偏偏是 B+树呢?
为什么不是一般二叉树?
如果二叉树特殊化为一个链表,相当于全表扫描。平衡二叉树相比于二叉查找 树来说,查找效率更稳定,总体的查找速度也更快。
为什么不是平衡二叉树呢?
我们知道,在内存比在磁盘的数据,查询效率快得多。如果树这种数据结构作
为索引,那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说
的一个磁盘块,但是平衡二叉树可是每个节点只存储一个键值和数据的,如果
是 B 树,可以存储更多的节点数据,树的高度也会降低,因此读取磁盘的次数
就降下来啦,查询效率就快啦。
那为什么不是 B 树而是 B+树呢?
- B+树非叶子节点上是不存储数据的,仅存储键值,而 B 树节点中不仅存储
键值,也会存储数据。innodb 中页的默认大小是 16KB,如果不存储数据,那 么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就 会更矮更胖,如此一来我们查找数据进行磁盘的 IO 次数有会再次减少,数据查
询的效率也会更快。 - B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的,链
表连着的。那么 B+树使得范围查找,排序查找,分组查找以及去重查找变得 异常简单。
6. 一次B+树索引树查找过程
假设有以下表结构,并且初始化了这几条数据
CREATE TABLE `employee` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`date` datetime DEFAULT NULL,
`sex` int(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_age` (`age`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into employee values(100,'小伦',43,'2021-01-20','0');
insert into employee values(200,'俊杰',48,'2021-01-21','0');
insert into employee values(300,'紫琪',36,'2020-01-21','1');
insert into employee values(400,'立红',32,'2020-01-21','0');
insert into employee values(500,'易迅',37,'2020-01-21','1');
insert into employee values(600,'小军',49,'2021-01-21','0');
insert into employee values(700,'小燕',28,'2021-01-21','1');
执行这条查询SQL,需要执行几次的树搜索操作?可以画下对应的索引树结构图~
select * from Temployee where age=32;
其实这个,这个大家可以先画出idx_age普通索引的索引结构图,大概如下:

再画出id主键索引,我们先画出聚族索引结构图,如下:
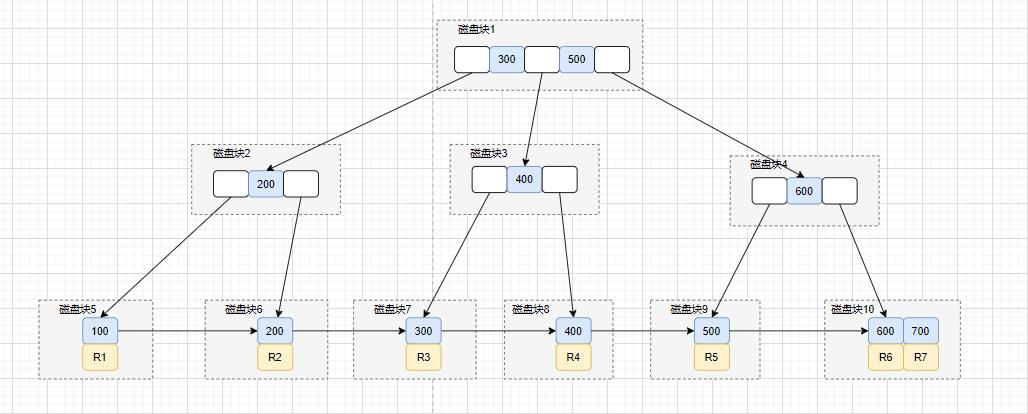
这条 SQL 查询语句执行大概流程是这样的:
- 搜索
idx_age索引树,将磁盘块1加载到内存,由于32<43,搜索左路分支,到磁盘寻址磁盘块2。 - 将
磁盘块2加载到内存中,由于32<36,搜索左路分支,到磁盘寻址磁盘块4。 - 将
磁盘块4加载到内存中,在内存继续遍历,找到age=32的记录,取得id = 400. - 拿到
id=400后,回到id主键索引树。 - 搜索
id主键索引树,将磁盘块1加载到内存,因为300<400<500,所以在选择中间分支,到磁盘寻址磁盘块3。 - 虽然在
磁盘块3,找到了id=400,但是它不是叶子节点,所以会继续往下找。 到磁盘寻址磁盘块8。 - 将
磁盘块8加载内存,在内存遍历,找到id=400的记录,拿到R4这一行的数据,好的,大功告成。
7. 什么是回表?如何减少回表?
当查询的数据在索引树中,找不到的时候,需要回到主键索引树中去获取,这个过程叫做回表。
比如在第6小节中,使用的查询SQL
select * from employee where age=32;
需要查询所有列的数据,idx_age普通索引不能满足,需要拿到主键id的值后,再回到id主键索引查找获取,这个过程就是回表。
8. 什么是覆盖索引?
如果我们查询SQL的select *修改为 select id, age的话,其实是不需要回表的。因为id和age的值,都在idx_age索引树的叶子节点上,这就涉及到覆盖索引的只是点了。
覆盖索引是
select的数据列只用从索引中就能够取得,不必回表,换句话说,查询列要被所建的索引覆盖。
9. 聊聊索引的最左前缀原则
索引的最左前缀原则,可以是联合索引的最左N个字段。比如你建立一个组合索引(a,b,c),其实可以相当于建了(a),(a,b),(a,b,c)三个索引,大大提高了索引复用能力。
当然,最左前缀也可以是字符串索引的最左M个字符。。 比如,你的普通索引树是酱紫:
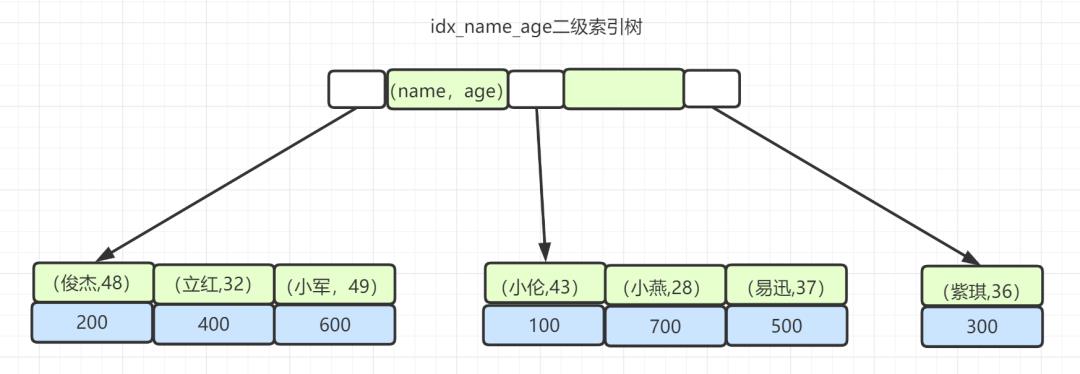
这个SQL:select * from employee where name like '小%' order by age desc;也是命中索引的。
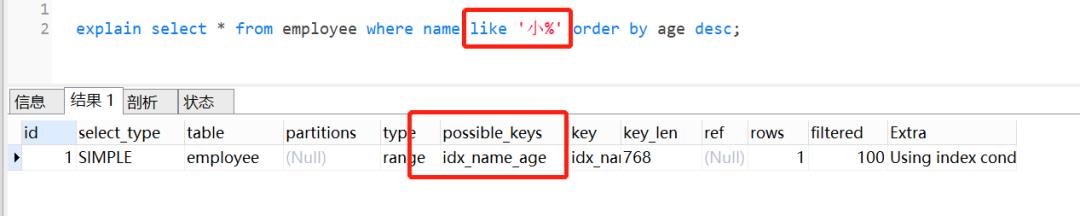
10. 索引下推了解过吗?什么事索引下推
给你这个SQL:
select * from employee where name like '小%' and age=28 and sex='0';
其中,name和age为联合索引(idx_name_age)。
如果是Mysql5.6之前,在idx_name_age索引树,找出所有名字第一个字是“小”的人,拿到它们的主键id,然后回表找出数据行,再去对比年龄和性别等其他字段。如图:
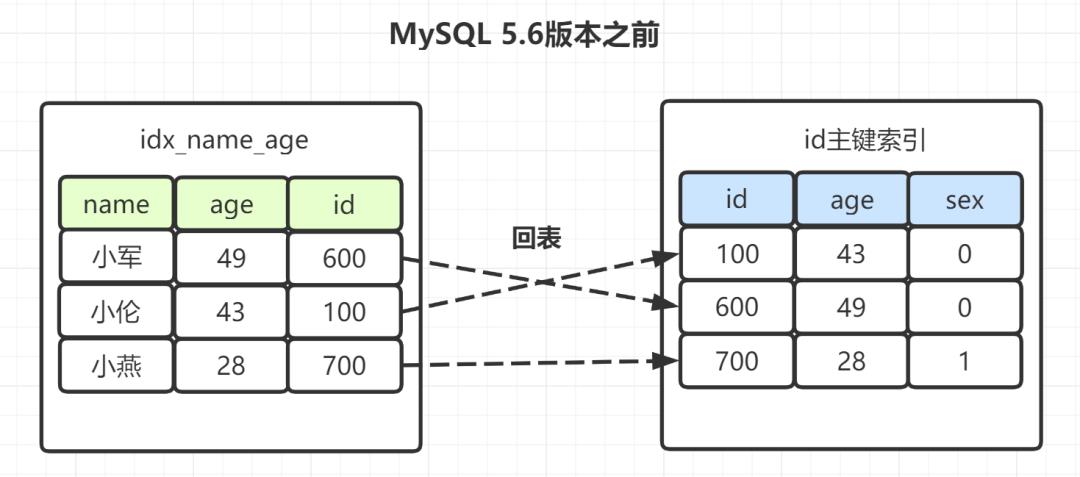
有些朋友可能觉得奇怪,idx_name_age(name,age)不是联合索引嘛?为什么选出包含“小”字后,不再顺便看下年龄age再回表呢,不是更高效嘛?所以呀,MySQL 5.6就引入了索引下推优化,可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
因此,MySQL5.6版本之后,选出包含“小”字后,顺表过滤age=28

11. 大表如何添加索引
如果一张表数据量级是千万级别以上的,那么,如何给这张表添加索引?
我们需要知道一点,给表添加索引的时候,是会对表加锁的。如果不谨慎操作,有可能出现生产事故的。可以参考以下方法:
- 先创建一张跟原表
A数据结构相同的新表B。 - 在新表
B添加需要加上的新索引。 - 把原表
A数据导到新表B rename新表B为原表的表名A,原表A换别的表名;
12. 如何知道语句是否走索引查询?
explain查看SQL的执行计划,这样就知道是否命中索引了。
当explain与SQL一起使用时,MySQL将显示来自优化器的有关语句执行计划的信息。

一般来说,我们需要重点关注type、rows、filtered、extra、key。
1.2.1 type
type表示连接类型,查看索引执行情况的一个重要指标。以下性能从好到坏依次:system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
- system:这种类型要求数据库表中只有一条数据,是
const类型的一个特例,一般情况下是不会出现的。 - const:通过一次索引就能找到数据,一般用于主键或唯一索引作为条件,这类扫描效率极高,,速度非常快。
- eq_ref:常用于主键或唯一索引扫描,一般指使用主键的关联查询
- ref : 常用于非主键和唯一索引扫描。
- ref_or_null:这种连接类型类似于
ref,区别在于MySQL会额外搜索包含NULL值的行 - index_merge:使用了索引合并优化方法,查询使用了两个以上的索引。
- unique_subquery:类似于
eq_ref,条件用了in子查询 - index_subquery:区别于
unique_subquery,用于非唯一索引,可以返回重复值。 - range:常用于范围查询,比如:between … and 或 In 等操作
- index:全索引扫描
- ALL:全表扫描
1.2.2 rows
该列表示MySQL估算要找到我们所需的记录,需要读取的行数。对于InnoDB表,此数字是估计值,并非一定是个准确值。
1.2.3 filtered
该列是一个百分比的值,表里符合条件的记录数的百分比。简单点说,这个字段表示存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例。
1.2.4 extra
该字段包含有关MySQL如何解析查询的其他信息,它一般会出现这几个值:
- Using filesort:表示按文件排序,一般是在指定的排序和索引排序不一致的情况才会出现。一般见于order by语句
- Using index :表示是否用了覆盖索引。
- Using temporary: 表示是否使用了临时表,性能特别差,需要重点优化。一般多见于group by语句,或者union语句。
- Using where : 表示使用了where条件过滤.
- Using index condition:MySQL5.6之后新增的索引下推。在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据。
1.2.5 key
该列表示实际用到的索引。一般配合possible_keys列一起看。
13.Hash 索引和 B+树区别是什么?你在设计索引是怎么抉择的?
- B+树可以进行范围查询,Hash 索引不能。
- B+树支持联合索引的最左侧原则,Hash 索引不支持。
- B+树支持 order by 排序,Hash 索引不支持。
- Hash 索引在等值查询上比 B+树效率更高。(但是索引列的重复值很多的话,Hash冲突,效率降低)。
- B+树使用 like 进行模糊查询的时候,like 后面(比如%开头)的话可以起到优化的作用,Hash 索引根本无法进行模糊查询。
14. 索引有哪些优缺点?
优点:
- 索引可以加快数据查询速度,减少查询时间
- 唯一索引可以保证数据库表中每一行的数据的唯一性
缺点:
- 创建索引和维护索引要耗费时间
- 索引需要占物理空间,除了数据表占用数据空间之外,每一个索引还要占用一定的物理空间
- 以表中的数据进行增、删、改的时候,索引也要动态的维护。
15. 聚簇索引与非聚簇索引的区别
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。它表示索引结构和数据一起存放的索引。非聚集索引是索引结构和数据分开存放的索引。
接下来,我们分不同存存储引擎去聊哈~
在MySQL的InnoDB存储引擎中, 聚簇索引与非聚簇索引最大的区别,在于叶节点是否存放一整行记录。聚簇索引叶子节点存储了一整行记录,而非聚簇索引叶子节点存储的是主键信息,因此,一般非聚簇索引还需要回表查询。
- 一个表中只能拥有一个聚集索引(因为一般聚簇索引就是主键索引),而非聚集索引一个表则可以存在多个。
- 一般来说,相对于非聚簇索引,聚簇索引查询效率更高,因为不用回表。
而在MyISM存储引擎中,它的主键索引,普通索引都是非聚簇索引,因为数据和索引是分开的,叶子节点都使用一个地址指向真正的表数据。
以上是关于索引15连问的主要内容,如果未能解决你的问题,请参考以下文章