---爬取csdn作者排行榜
Posted 拉不拉斯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了---爬取csdn作者排行榜相关的知识,希望对你有一定的参考价值。
上篇文章介绍了requests库获取数据的基本方法,本篇文章利用自动化测试工具selenium进行数据抓取,也会对代码部分进行详细解释,以便小伙伴们能够更加理解和上手。
一.selenium技术介绍
Selenium是最广泛使用的开源 Web UI(用户界面)自动化测试套件之一。Selenium 支持的语言包括C#,Java,Perl,php,Python 和 Ruby。目前,Selenium Web 驱动程序最受 Python 和 C#欢迎。 Selenium 测试脚本可以使用任何支持的编程语言进行编码,并且可以直接在大多数现代 Web 浏览器中运行。在爬虫领域 selenium 同样是一把利器,能够解决大部分的网页的反爬问题。下面就进入正式的 study 阶段。
二.思路分析及部分成果展示
1.正确到达排行榜页面
为了更好的上手selenium,这里选择从百度开始进行搜索
首先进入百度,然后抓取输入框,进行输入csdn进行搜索
再者需要注意的是窗口的切换问题,当网页切换时,web仍然在初始页,因此1需要调用相应方法调转窗口
web.switch_to_window(web.window_handles[-1])
此语句为调转到最后一个窗口,相应的selenium方法在前面相关文章已经提高,大家可以参考下面文章
https://blog.csdn.net/qqshenbaobao/article/details/118156004?spm=1001.2014.3001.5501
2.抓包工具xpath路径获取
利用抓包工具,复制所要抓取元素xpath路径进行数据获取
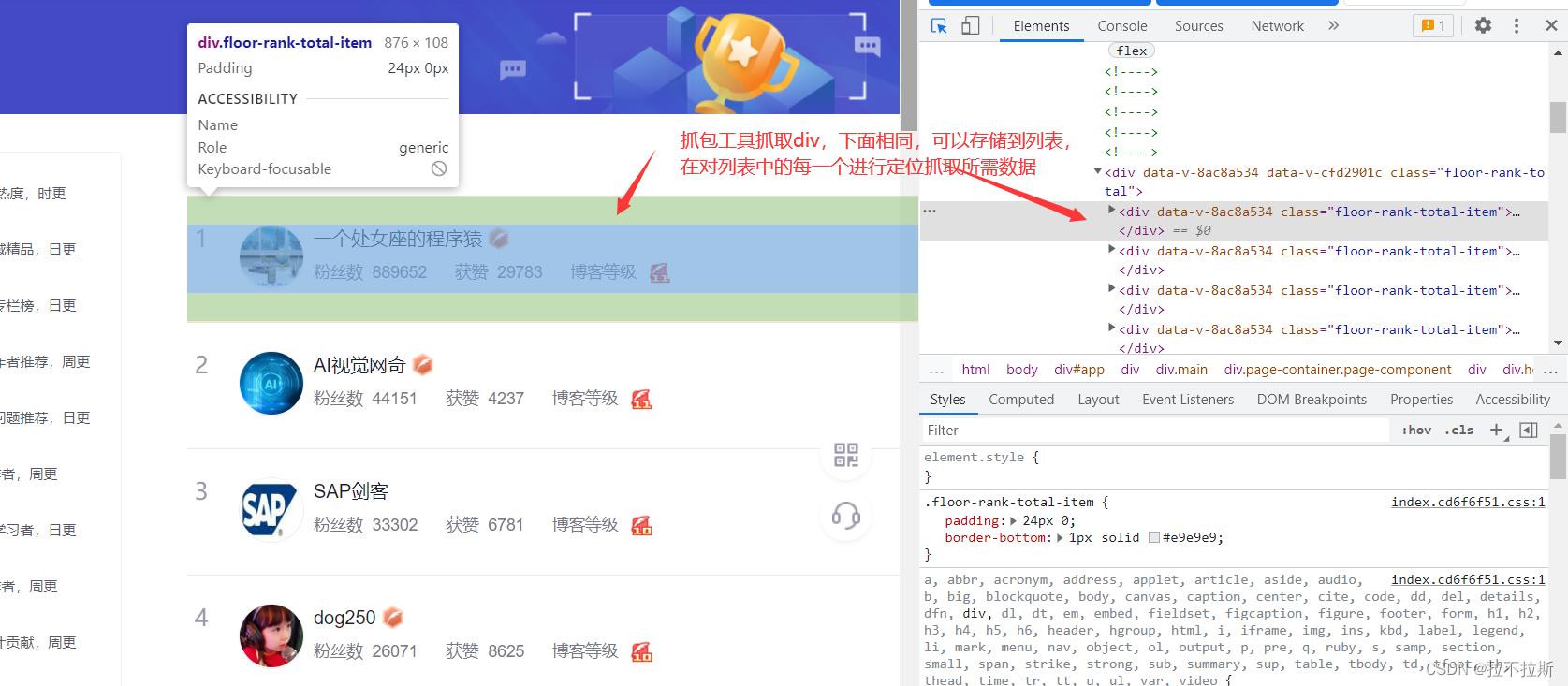
xpath路径获取方式:
3.数据提取
以第一个div为例,这里粘贴出第一个div的元素层次分级,并进行所需元素精准定位。
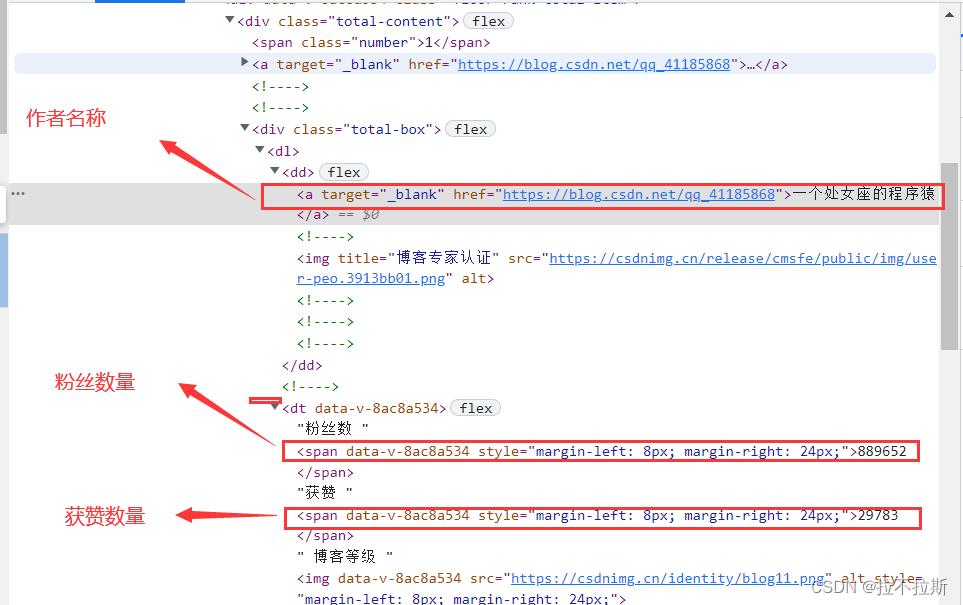
注意:若获取批量数据进行列表迭代,不能利用xpath进行复制粘贴,因为不同的div定位不同,故应该在该div对象中进行相对定位获取所需要元素.
定位作者名称:
nickName=div.find_element_by_xpath("./div/div/dl/dd/a").text
定位粉丝数量:
fscount=div.find_element_by_xpath("./div/div/dl/dt/span[1]").text
定位获赞数量:
hzcount=div.find_element_by_xpath("./div/div/dl/dt/span[2]").text
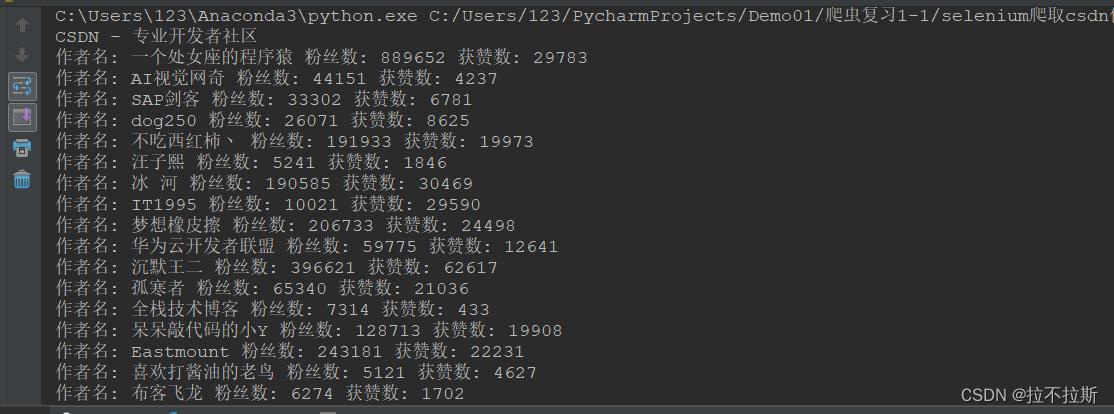
4.成果展示
5.完整代码
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
web=webdriver.Chrome()
web.get("https://www.baidu.com/")
web.find_element_by_xpath("//*[@id='kw']").send_keys("csdn",Keys.ENTER)
time.sleep(2)
web.find_element_by_xpath('//*[@id="1"]/div/div[1]/h3/a[1]').click()
web.switch_to_window(web.window_handles[-1])
print(web.title)
time.sleep(2)
web.find_element_by_xpath('//*[@id="floor-www-index_558"]/div/div[4]/div/div[1]/div/ul/li[5]/a').click()
time.sleep(1)
web.switch_to_window(web.window_handles[-1])
web.find_element_by_xpath('//*[@id="floor-rank_460"]/div[2]/div[1]/div/div[1]/ul/li[8]/div[2]').click()
time.sleep(1)
div_list=web.find_elements_by_xpath('//*[@id="floor-rank_460"]/div[2]/div[2]/div/div[2]/div')
for div in div_list:
nickName=div.find_element_by_xpath("./div/div/dl/dd/a").text
fscount=div.find_element_by_xpath("./div/div/dl/dt/span[1]").text
hzcount=div.find_element_by_xpath("./div/div/dl/dt/span[2]").text
print("作者名:",nickName,"粉丝数:",fscount,"获赞数:",hzcount)
6.后续安排
码字不易,希望大家可以动动小手点个赞,后续会出更多高质量的文章供大家参考学习,一起加油吧!
以上是关于---爬取csdn作者排行榜的主要内容,如果未能解决你的问题,请参考以下文章
steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
为揭秘CSDN谁有100万粉丝?我连夜研发了粉丝数排行榜插件,通过 dalao 一键即可唤醒