[streamlit]数据科学科研工作者的神器,必须要推荐一下
Posted 刘炫320
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[streamlit]数据科学科研工作者的神器,必须要推荐一下相关的知识,希望对你有一定的参考价值。
1. 前言
做科研当然要有过硬的专业知识,但是也少不了一些辅助,才能最大程度发挥我们的能力。因此,除去我们模型性能优秀,结果良好以外,如何进行一个好的展示,也是非常有必要的。那么今天,我们就隆重介绍,这个几乎可以替代掉Flask作为构建demo首选的streamlit。(这次不是chatGPT了,毕竟chatGPT只会描述,不会感受。)
2. streamlit能干什么
我们为什么要用streamlit呢?
第一,我们想要做个展示我们模型的Demo页面。
第二,自己就只会python,不懂啥三剑客(html,css,js),但我就想自己去做个界面,怎么整?
第三,不能太复杂,太复杂的光学起来就很吃力了,我就想要个简单的Demo就行。
于是,于是streamlit来了,不仅可以完全满足以上要求,而且还能更加的强大。完全可以由python编写的网页,你想象过长什么样吗?
再给你看看它的一些组件,你就大概知道它能够做什么了。
2.1 普通输出
首先它是可以输出普通文本的,而且支持部分Markdown语法,即使你啥都不写,你就想做一个纯文本的BLOG,它也能够完全满足你。
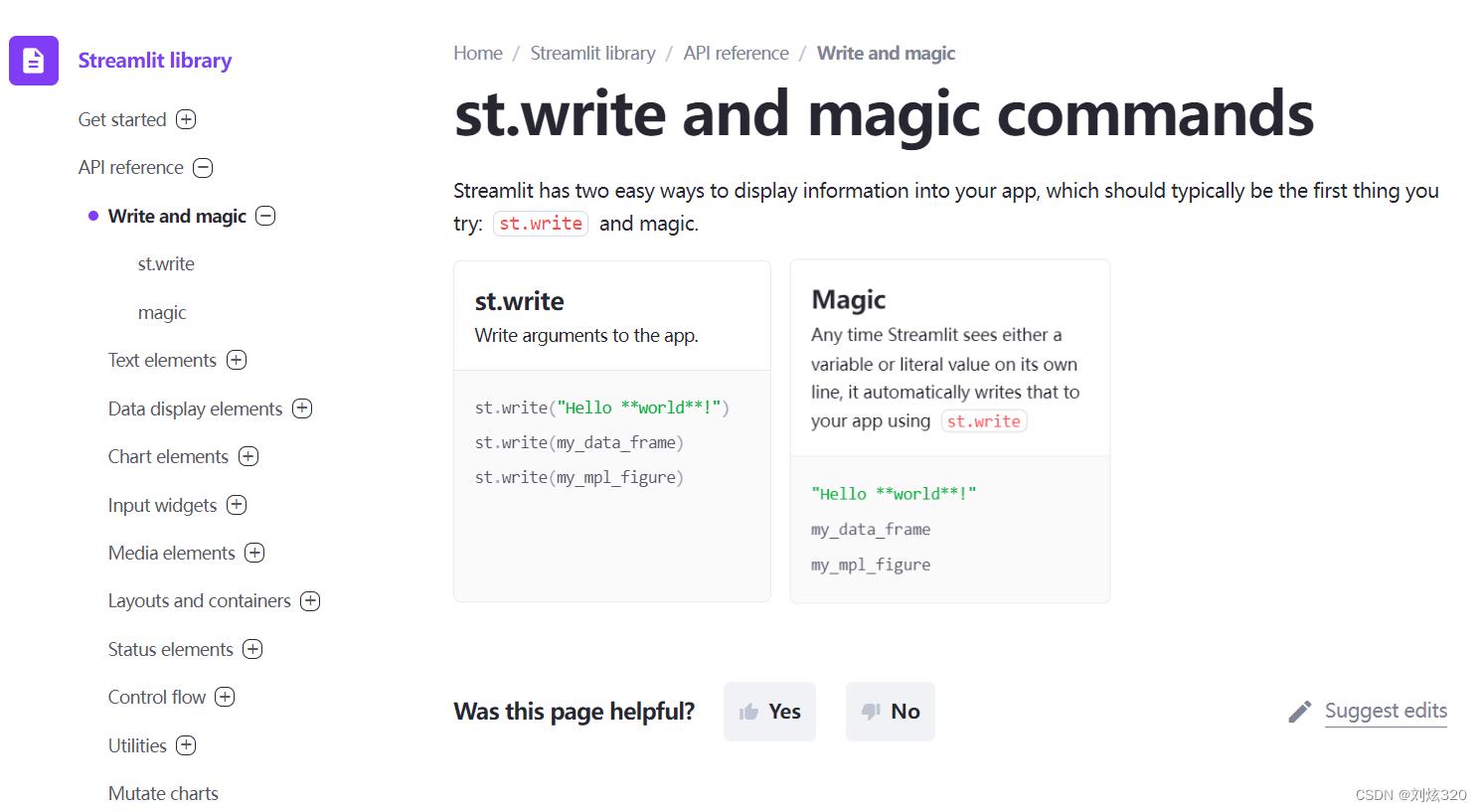
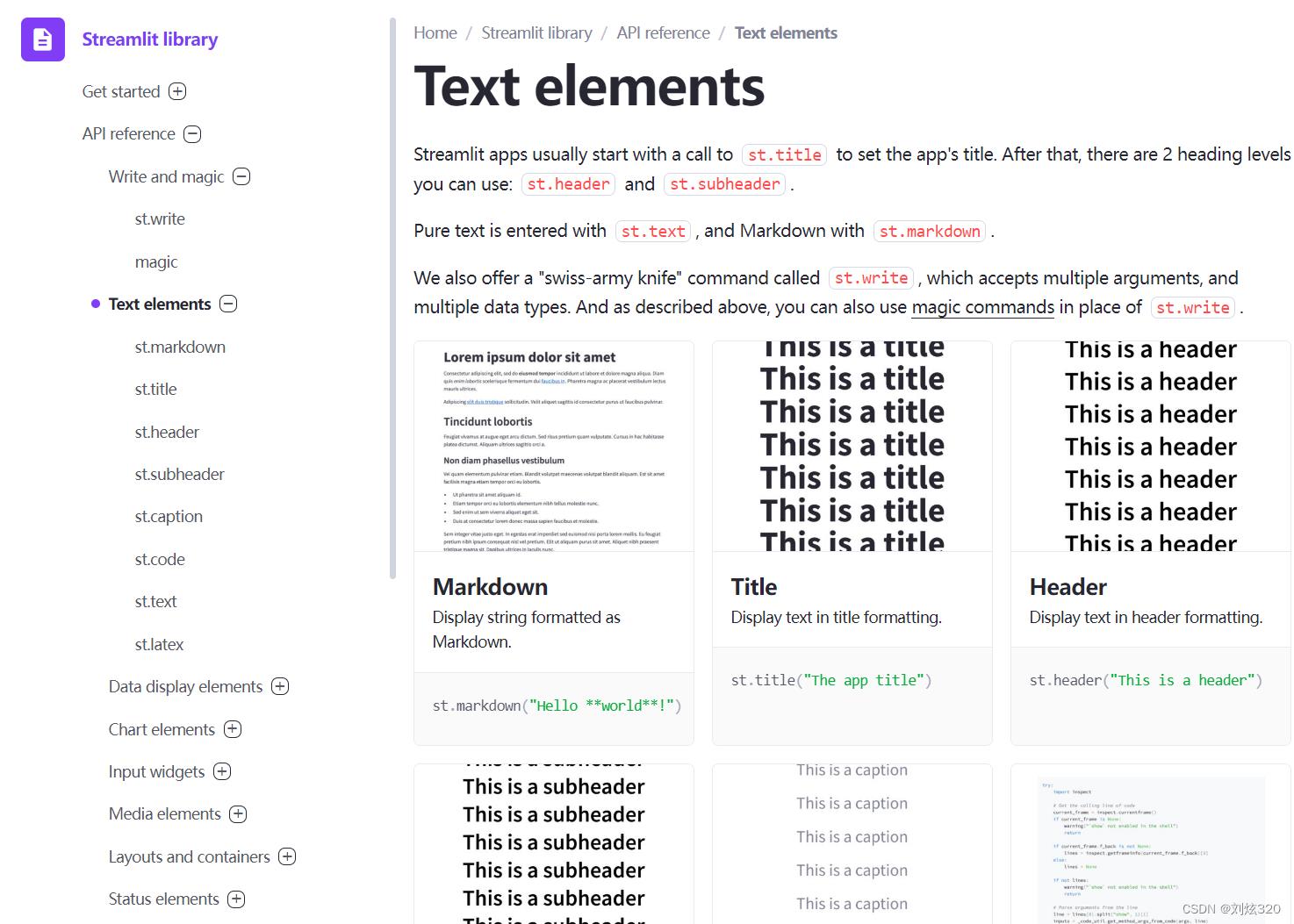
2.2 数据展示
如果你有一堆数据要展示,但是想展示的好看点,Streamlit也可以满足你,比如列表、或者评价指标,甚至是json也可以很好看的展示出来。
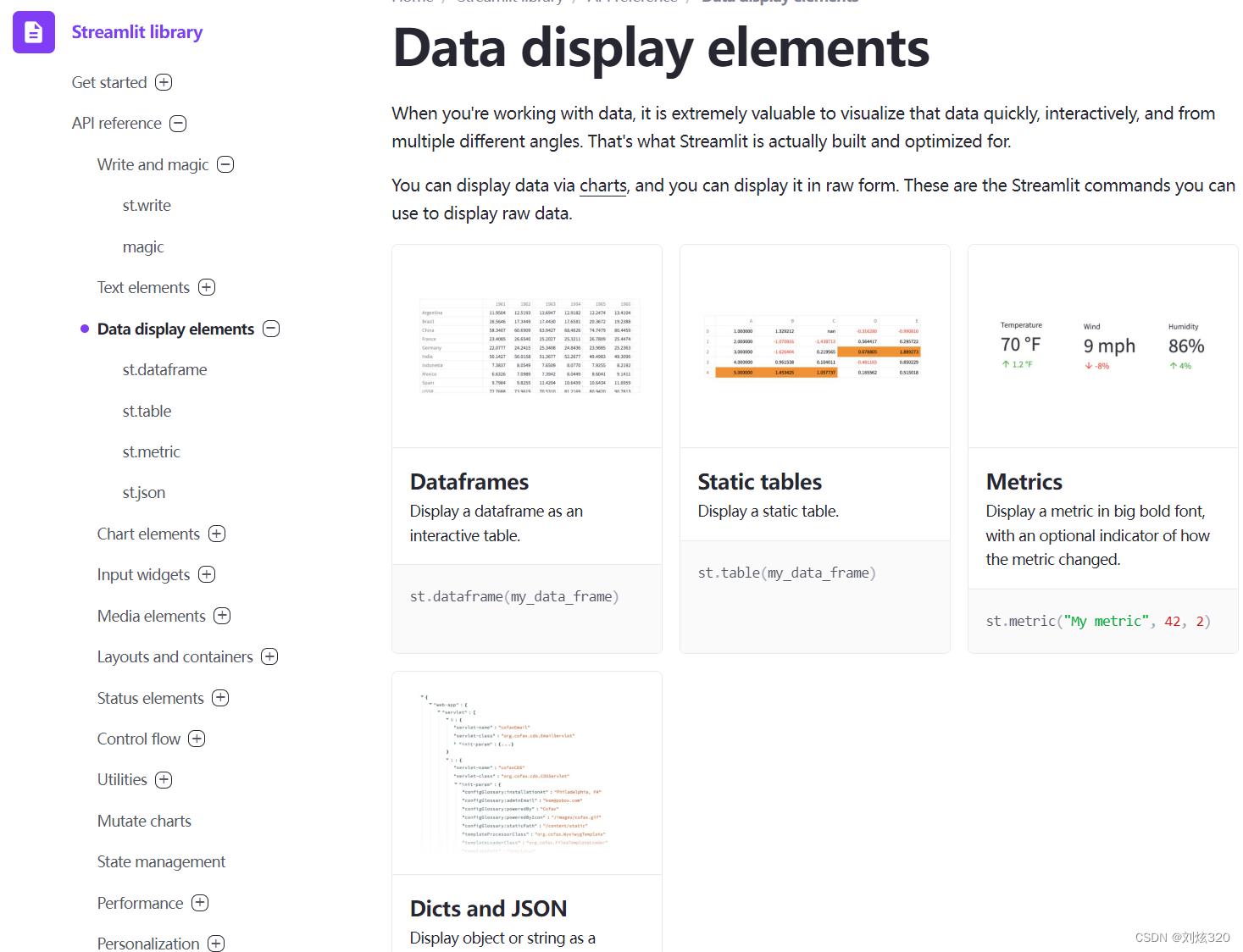
2.3 展示图片
光展示文字或者表格不太直观啊,我们最终还是希望能够用图来展示我们的结果,哦对了,图有两种,一种是Picture一种是Chart,streamlit都可以完美支持,甚至是音频或者视频都可以完美的嵌套在这里面。
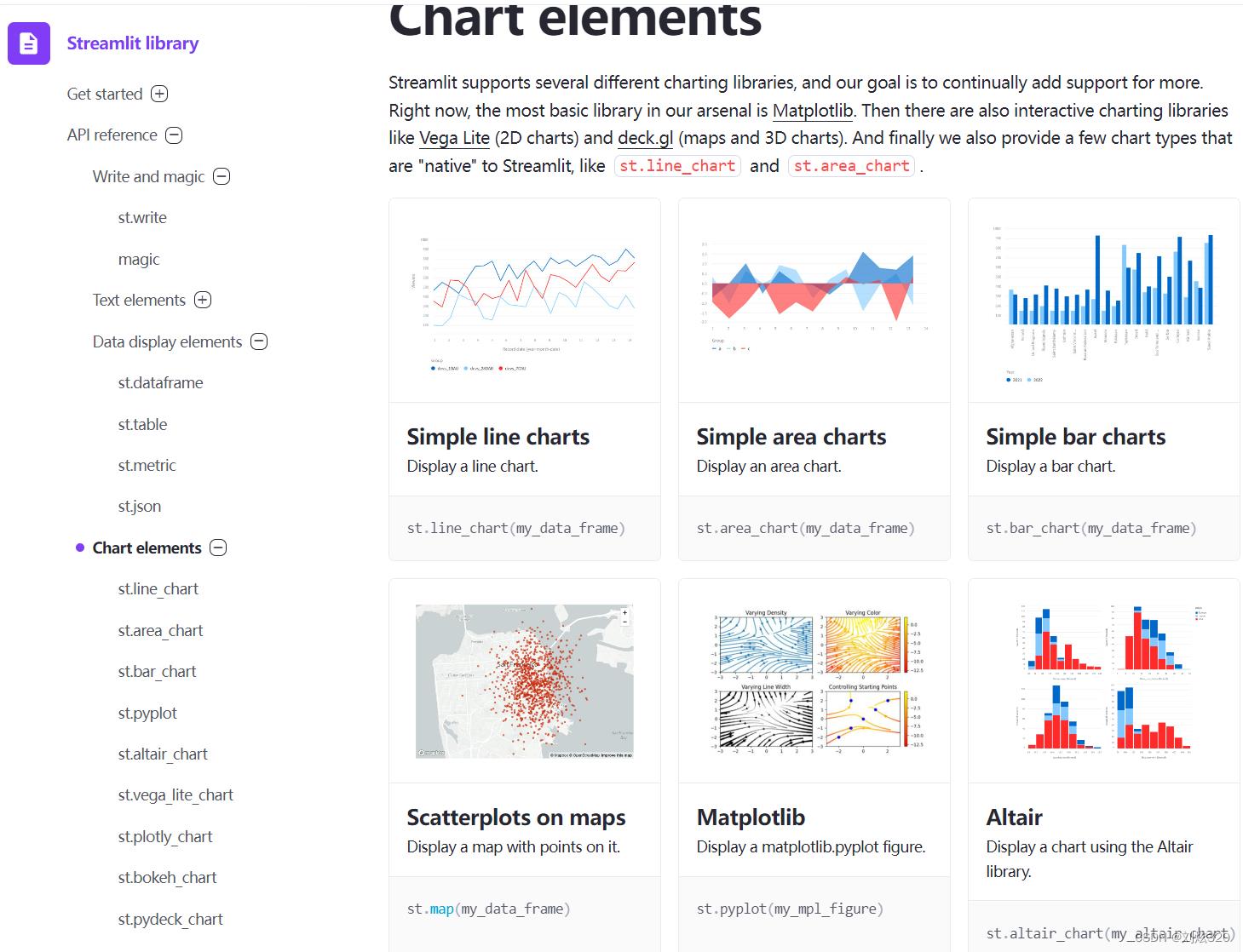
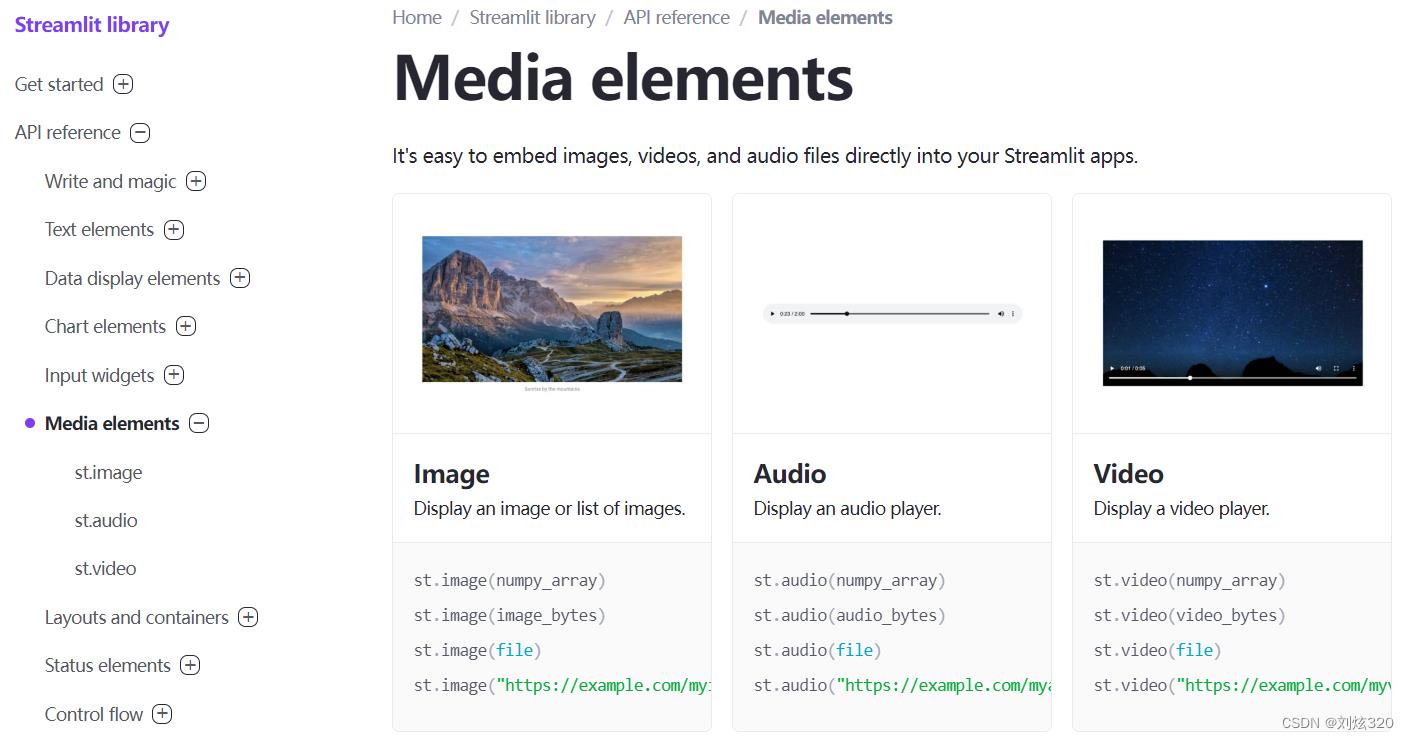
2.4 交互控件
是的是的,如果你说这上面不就是个静态展示页面么,我用个jekyll更能轻量式的搭建啊,但是下面的交互控件,则是我最看重的地方。话不多说,大家可以看一看效果。从普通的点击按钮,到上传下载文件,甚至是直接调用摄像头拍摄照片都能够很轻松的使用,看起来是不是心动了。
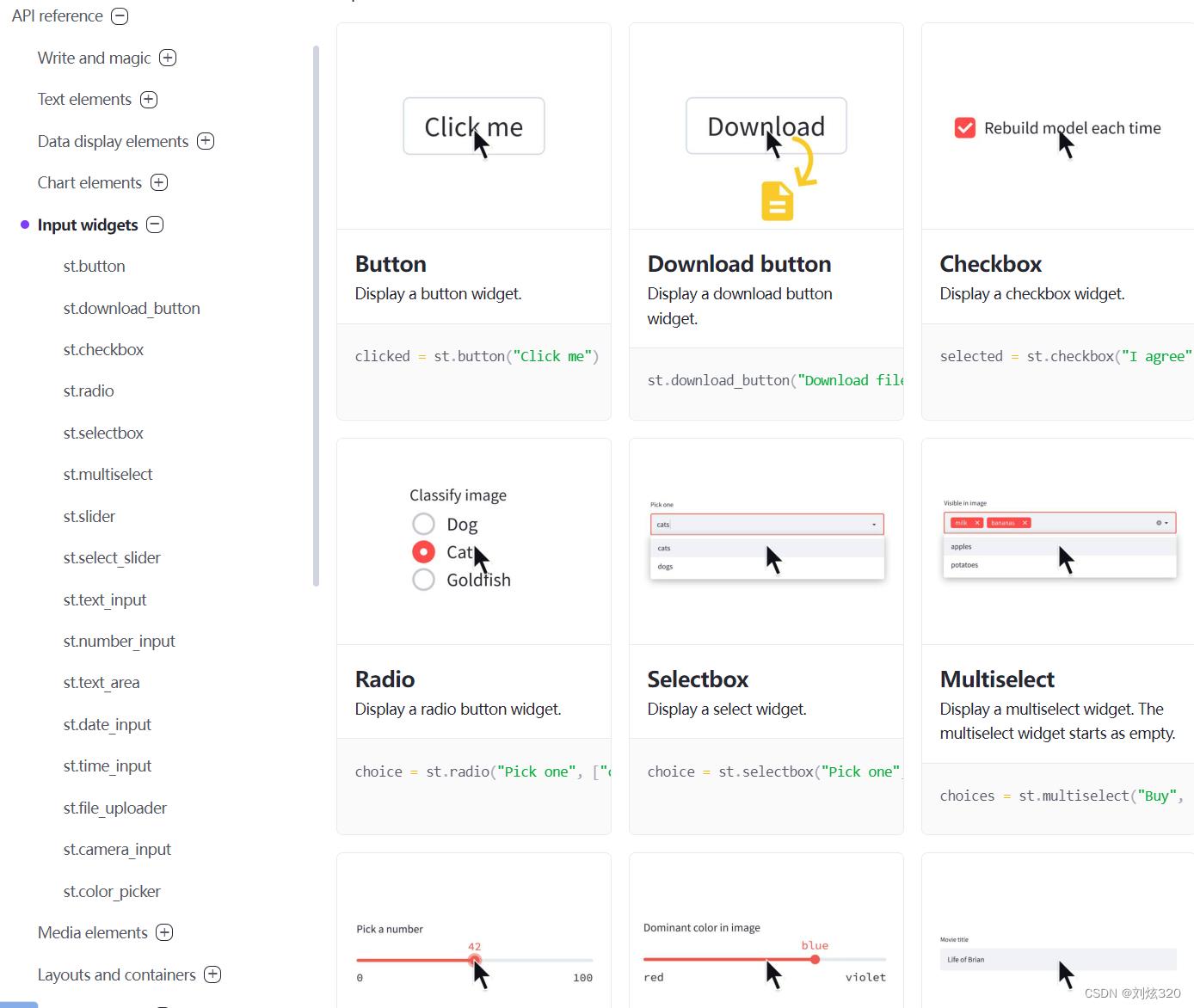
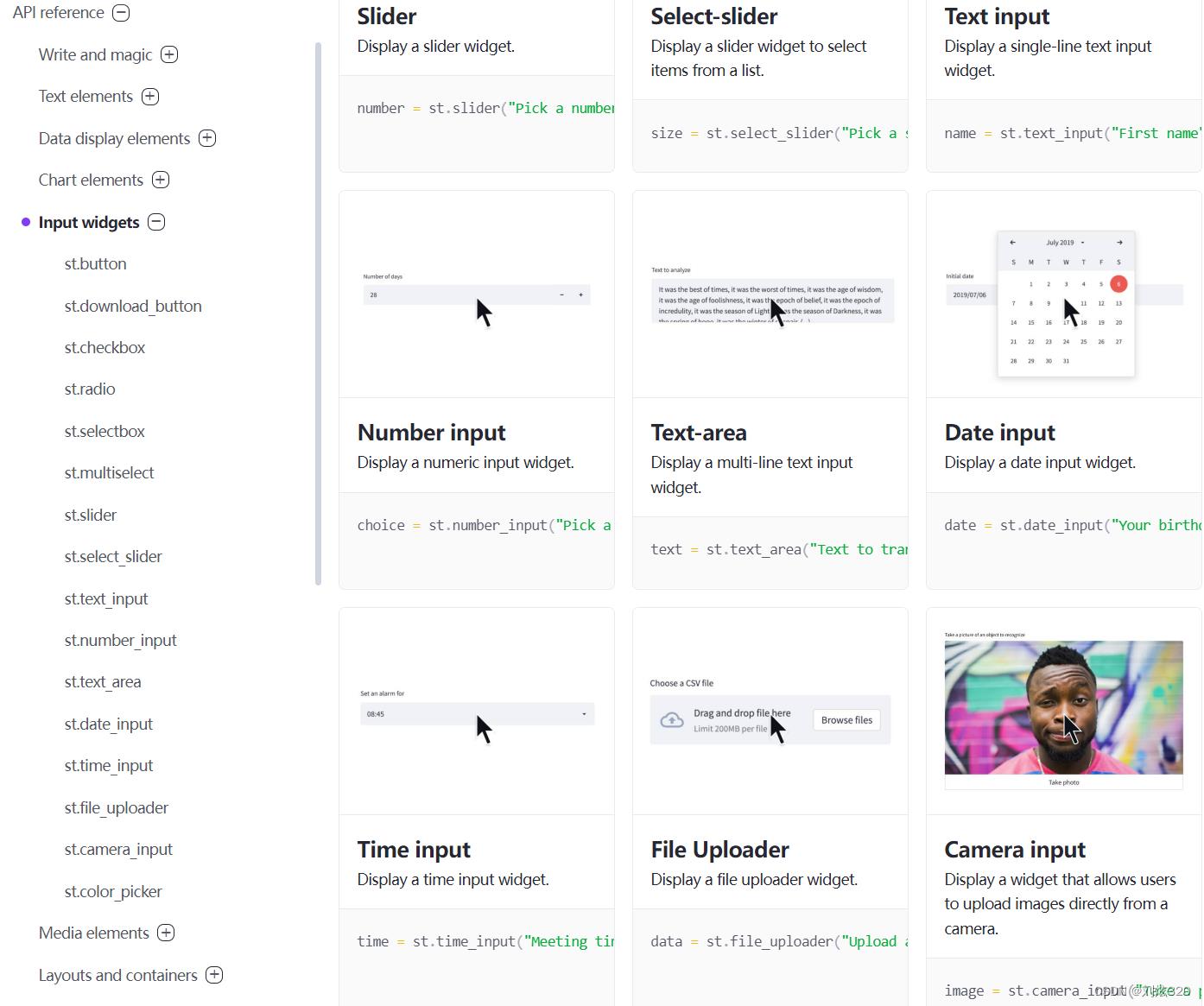
2.4 布局
作为网页好不好看,最重要的是布局,streamlit也帮助我们快速搭建美观的布局了。
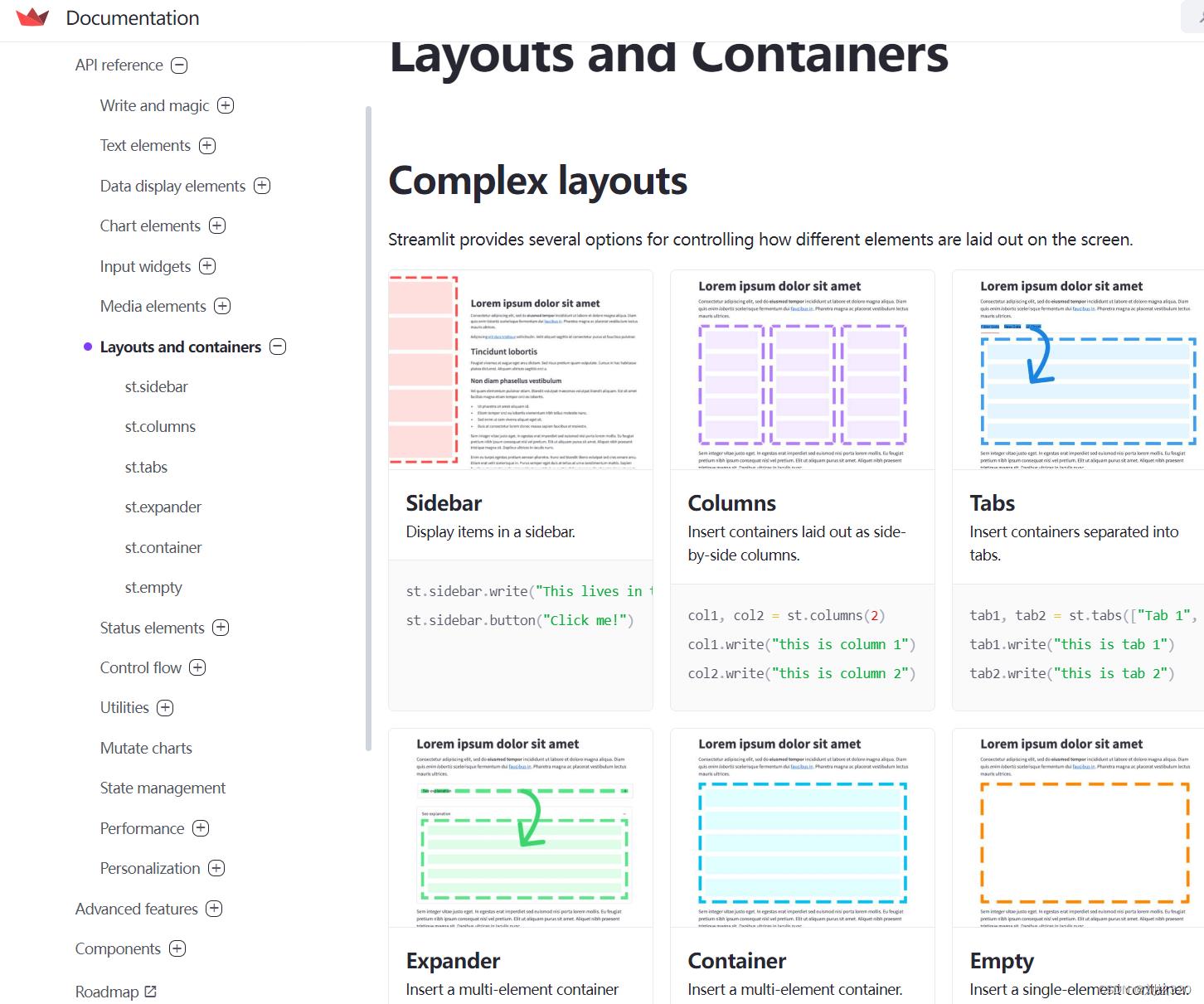
2.5 高级功能
当然,streamlit的功能远不于此,还有一个高级功能等待我们去探索,例如使用命令行,主题啊,或者性能优化等等。

2.6 云发布
最重要的是,streamlit可以有偿云发布,这才是重点,也就是它为什么能够一直做下去的原因,是因为它有盈利点,也有开放性。
streamlit自己构建了关于自己展示的一个demo,其样子和其他网站看起来没什么区别,甚至更好看一些。(不过有一点我自己偷偷吐槽一下,就是构建复杂的网站后,它的响应速度还是需要一定的耐心的。)
3. streamlit该怎么做
光说不练假把式,既然都能吸引我到半夜还在倒腾的东西,那肯定要真正能实践起来才行。当然,我就做了一些简单的demo,主要是为了呈现功能,具体细节还需要进行二次加工。这次,我主要实践了两个比较重要的也比较有用的功能,至于绘图功能,大家可以参考官方文档,讲述的很细致哦。
因此如果想使用streamlit的话,也非常容易,只需要遵循以下3步就可以了。
- 使用命令安装streamlit
pip install streamlit
- 在自己的项目里增加一个app.py(其实叫啥名字都行),负责整个界面的设计和渲染,大致只包含4个部分。
# 导入包
# 设定运行环境
# 写一个主函数writer()
# 执行函数main
- 通过下面命令启动它:
streamlit run app.py # 默认端口8501
or
streamlit run app.py --server.port your_port # 指定端口
- 打开浏览器,就可以享用了
http://localhost:8501
3.1 模型demo
我们做人工智能的,模型做的那肯定都是非常优秀的,但是很难让别人能够感受到我们模型的优越性,这是因为我们没有让别人所见即所得,让他们感受一下模型的性能比冷冰冰的数字更加有效。但是我们之前的技能点都点在了科研上了,而如何展示我们的工作则成为我们头疼的事情,因为这是一个偏工程而非科研的工作。
不过好在,streamlit能够帮助我们快速构建一个看起来还可以的demo,大家可以先看一下效果。
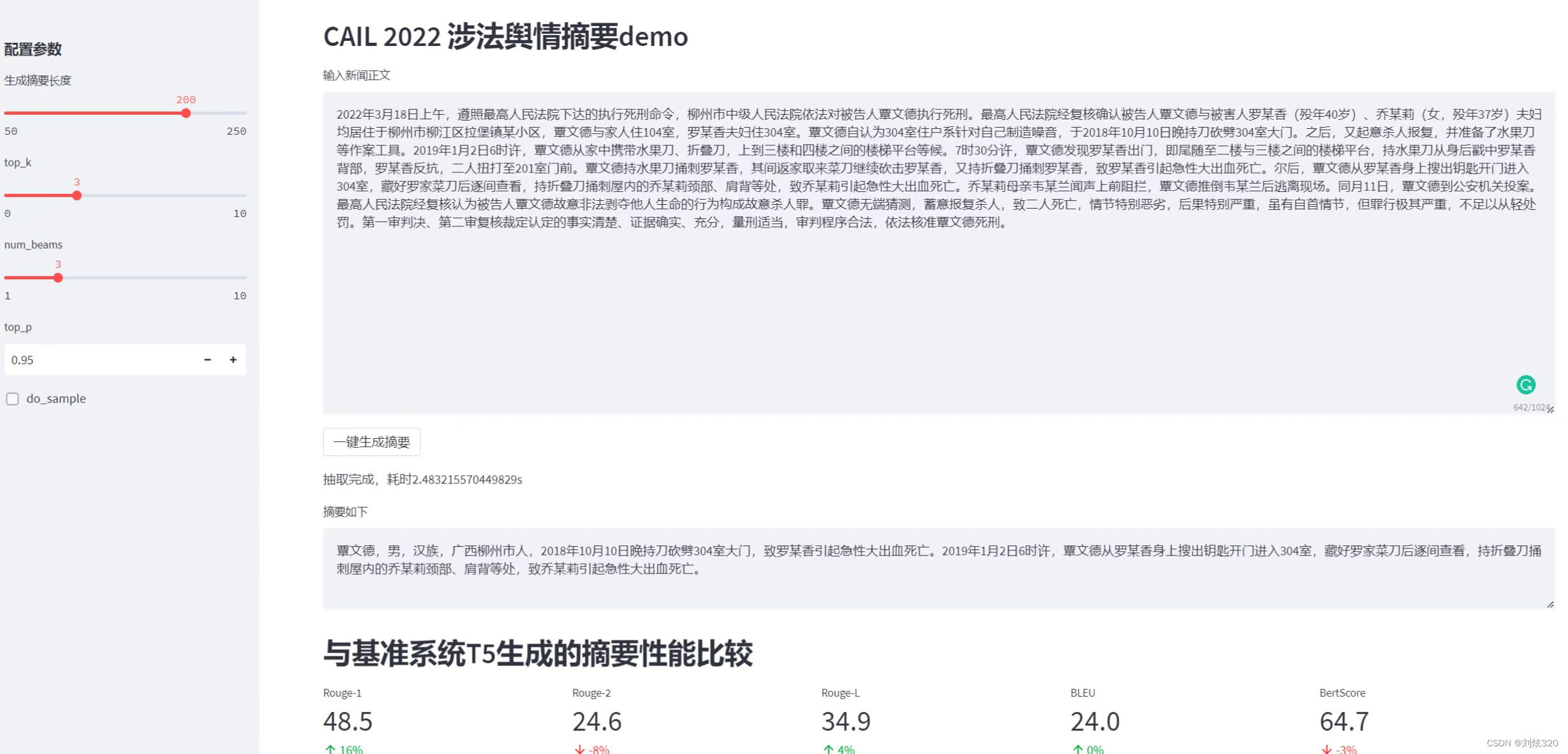
可以看到,很容易生成了一个看起来还可以的界面。左边菜单是用来调节一些模型的参数的,而右边则是主界面。主界面上面是我们的输入栏,下面有一个一键生成摘要按钮,点击后,我们就能够通过我们的模型生成相应的摘要了。最下面还有一些和基准系统的性能比较,看起来是不是美观多了?
如果要从头开始构建这样一个界面,那必然是非常复杂的一个工程。但是streamlit让我们一个py文件就可以解决,主要代码如下:
import streamlit as st
import os
import torch
import time
from e2e import predict_one_sample
from module.model import MT5PForSequenceClassification
from module.tokenizer import T5PegasusTokenizer
st.set_page_config(page_title="Demo", initial_sidebar_state="auto", layout="wide")
@st.cache(allow_output_mutation=True)
def get_model(device, vocab_path, model_path):
tokenizer = T5PegasusTokenizer.from_pretrained(vocab_path)
model = MT5PForSequenceClassification(model_path)
#model.load_state_dict(torch.load(model_path))
model.to(device)
model.eval()
return tokenizer, model
device_ids = 7
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = str(device_ids)
device = torch.device("cuda" if torch.cuda.is_available() and int(device_ids) >= 0 else "cpu")
tokenizer, model = get_model(device, "t5_pegasus_torch/vocab.txt", "t5_pegasus_torch/")
def writer():
st.markdown(
"""
## CAIL 2022 涉法舆情摘要demo
"""
)
st.sidebar.subheader("配置参数")
max_length = st.sidebar.slider("生成摘要长度", min_value=50, max_value=250, value=200, step=1)
top_k = st.sidebar.slider("top_k", min_value=0, max_value=10, value=3, step=1)
num_beams = st.sidebar.slider("num_beams", min_value=1, max_value=10, value=3, step=1)
top_p = st.sidebar.number_input("top_p", min_value=0.0, max_value=1.0, value=0.95, step=0.01)
do_sample = st.sidebar.checkbox('do_sample')
content = st.text_area("输入新闻正文", max_chars=1024,height=400)
if st.button("一键生成摘要"):
start_message = st.empty()
start_message.write("正在抽取,请等待...")
start_time = time.time()
title = predict_one_sample(model, device, tokenizer, content, max_length=max_length,do_sample=do_sample,
num_beams=num_beams, top_k=top_k, top_p=top_p)
end_time = time.time()
start_message.write("抽取完成,耗时s".format(end_time - start_time))
st.text_area("摘要如下",title)
st.markdown(
"""
## 与基准系统T5生成的摘要性能比较
"""
)
col1, col2, col3,col4,col5 = st.columns(5)
col1.metric("Rouge-1", "48.5", "16%")
col2.metric("Rouge-2", "24.6", "-8%")
col3.metric("Rouge-L", "34.9", "4%")
col4.metric("BLEU", "24.0", "0%")
col5.metric("BertScore", "64.7", "-3%")
else:
st.stop()
if __name__ == '__main__':
writer()
3.2 性能评估
另一个比较能用得上的是性能评估,这里我们也不多说,直接上图。

这样的一个网页更加的容易了,下面是其app.py中的主要代码:
import json
import streamlit as st
import time
from evaluate import Evaluator
st.set_page_config(page_title="Evaluate", initial_sidebar_state="auto", layout="wide")
@st.cache(allow_output_mutation=True)
def get_evaluator():
evaluator = Evaluator()
return evaluator
evaluator = get_evaluator()
def get_sources_targets(baseline_data):
objects=json.loads(baseline_data)
sources = objects["sources"]
targets = objects["targets"]
return sources, targets
def compute_diff(baselines, system):
results = zip(baselines, system)
diff_list = []
for result in results:
diff = round((result[1] - result[0]) / result[0], 2)
diff_list.append(diff)
return diff_list
def set_metric(container, baselines, system=None):
col_name_list = ["Rouge-1", "Rouge-2", "Rouge-L", "BLEU", "BertScore"]
cols = container.columns(5)
if system != None:
diff_list = compute_diff(baselines, system)
for i in range(5):
cols[i].metric(col_name_list[i], str(round(system[i],4)), str(diff_list[i]) + "%")
else:
for i in range(5):
cols[i].metric(col_name_list[i], str(round(baselines[i],4)))
def writer():
st.markdown(
"""
## 摘要评估
"""
)
st.sidebar.subheader("上传/下载")
st.sidebar.write("请上传基准系统文件")
baseline_uploaded_file = st.sidebar.file_uploader("基准系统")
uploaded_files = st.sidebar.file_uploader("测试文件", accept_multiple_files=True)
if st.button("一键评估"):
start_message = st.empty()
start_message.write("正在评估,请等待...")
start_time = time.time()
baseline_data = baseline_uploaded_file.read().decode('UTF-8')
sources, targets = get_sources_targets(baseline_data)
baseline_performance = evaluator.compute_all_score(sources, targets)
baseline_container = st.container()
baseline_container.write("基准系统性能表现")
set_metric(baseline_container, baseline_performance)
for index, uploaded_file in enumerate(uploaded_files):
bytes_data = uploaded_file.read().decode('UTF-8')
sources, targets = get_sources_targets(bytes_data)
system_performance = evaluator.compute_all_score(sources, targets)
container = st.container()
container.write(uploaded_file.name + "系统的性能表现")
set_metric(container, baseline_performance, system_performance)
end_time = time.time()
start_message.write("评估完成,耗时s".format(end_time - start_time))
else:
st.stop()
if __name__ == '__main__':
writer()
以上代码我已整理发布demo_streamlit_text_generation,大家记得关注。
4. 小结
这次我们主要讲述了如何利用streamlit制作我们模型展示的Demo,以及利用它进行一个性能展示和比较。对于曾经开发过网页或者移动端App的人来说,这个半天就学会了。如果是0基础的,根据刘聪大神的说法,最多1天就能学会。不过官方给出的建议是,你可以花30天去学会它,而且给出了教程了《30天学会streamlt》。大家感兴趣的可以自己去尝试,非常实用的一款工具。
以上是关于[streamlit]数据科学科研工作者的神器,必须要推荐一下的主要内容,如果未能解决你的问题,请参考以下文章