采用特殊硬件指令对密码学算法加速
Posted mutourend
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了采用特殊硬件指令对密码学算法加速相关的知识,希望对你有一定的参考价值。
1. 引言
Armando Faz-Hermandez等人2018年论文《SoK: A Performance Evaluation of Cryptographic Instruction Sets on Modern Architectures》,开源代码见:
slide见:
现代处理器中扩展有针对密码学运行的指令集——Instruction Set Architecture(ISA):



2. 采用SHA New Instructions (SHA-NI)指令对SHA-256加速
2013年,Intel发布了SHA New Instructions(SHA-NI)说明书,包含的指令有:
- SHA1系列指令
- SHA1MSG1
- SHA1MSG2
- SHA1NEXTE
- SHA1RNDS4
- SHA256系列指令
- SHA256MSG1
- SHA256MSG2
- SHA256RNDS2
支持SHA-NI指令的处理器有:
- 2016年,Intel Goldmont——低功耗微处理架构
- 2017年,AMD Zen——中高端微处理架构
采用SHA-NI实现的SHA-256算法要比64-bit implementation快约4~5倍:

3. 采用SIMD vector指令对多个message SHA-256加速
Kaby Lake和Zen支持SSE和AVX2 vector指令集。
SHA-256算法基于32-bits words进行运算:


- 对单个消息进行SHA-256运算的性能约为9.67 cpb(cycles-per-byte)。
- 使用SSE指令做的vector实现,比单个消息哈希要快2.35倍左右。
- 使用AVX2指令做的vector实现,比单个消息哈希要快4.53倍左右。
- Zen处理器中的AVX指令延迟 要比 Intel处理器的 慢2倍。
4. Pipelining SHA-NI
需确保pipelining SHA-NI中的数据不存在相互依赖,使得相同类型的指令可重叠执行:
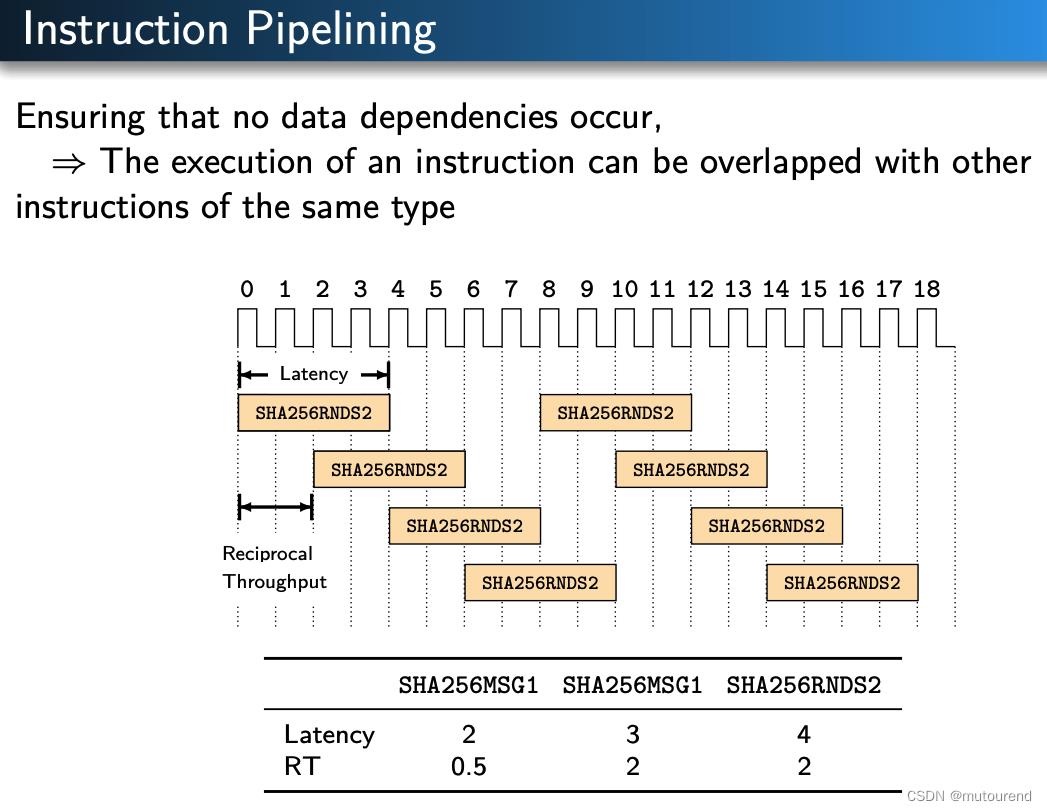
对Multiple-message hashing采用pipelined SHA-NI实现:

采用pipelined方案,对2个消息进行SHA-256性能比单个消息提升约18%;对4个消息比单个单个消息提升约21%。
5. 对Hash-based数字签名进行加速
当前基于哈希的post_quantum数字签名方案有:
- Stateful算法,详细见RFC8391:
- XMSS
- XMSS M T ^MT MT
- Stateless算法
- SPHINCS
- SPHINCS+(NIST将对其进行标准化)
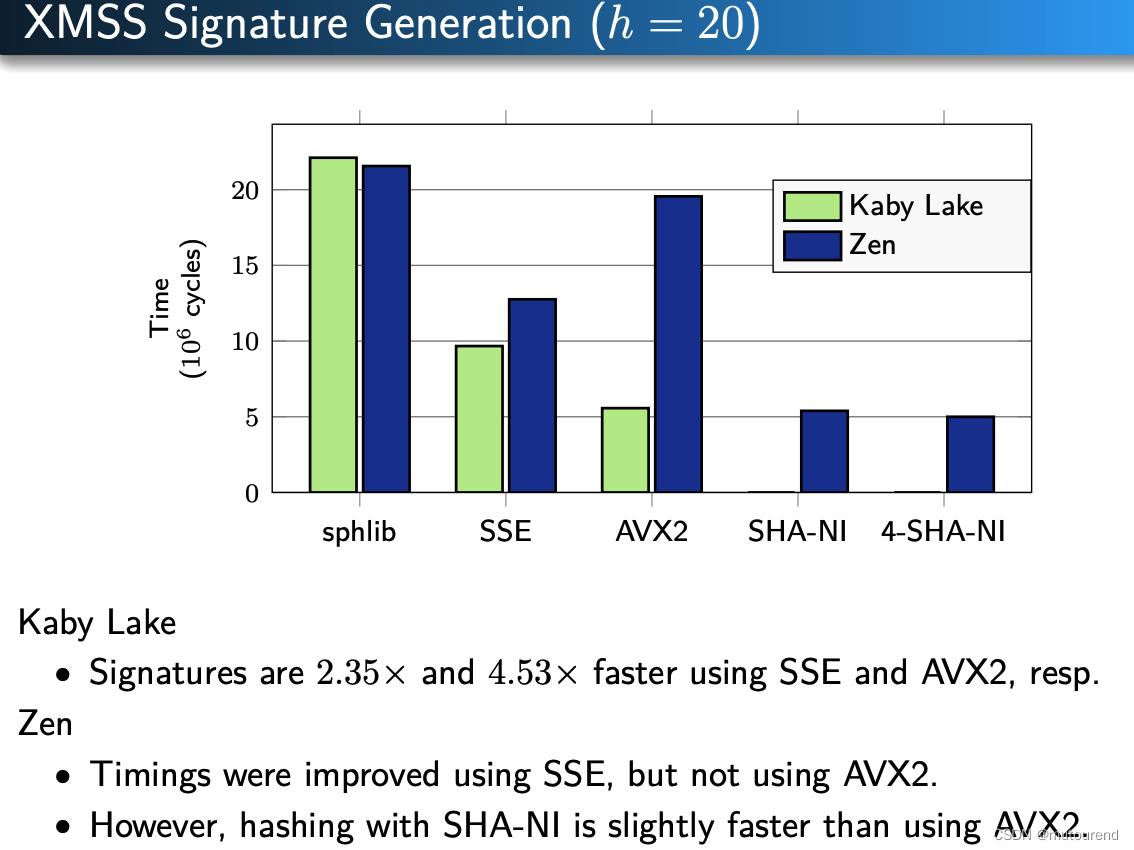

6. 采用AES-NI指令加速
2020年,Intel发布了执行AES算法的指令集:

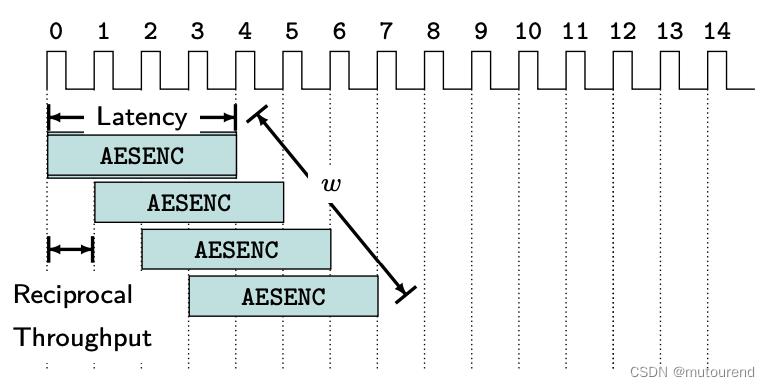
采用AES-NI指令实现的AES-128-CBC Encryption,性能主要取决于AESENC指令的延迟:

可将相同类型的AESENC指令重叠执行,实现pipeline,来对CTR和CBC decryption模式进行加密:
以上是关于采用特殊硬件指令对密码学算法加速的主要内容,如果未能解决你的问题,请参考以下文章