图像配准SIFT算法原理及二图配准拼接
Posted zstar-_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图像配准SIFT算法原理及二图配准拼接相关的知识,希望对你有一定的参考价值。
前言
本篇开始,将进入图像配准领域的研究。
图像拼接主要有SIFT, BRISK, ORB, AKAZE等传统机器学习算法以及SuperPoint等深度学习算法,在后续将一一进行研究和实验。本篇主要来研究SIFT算法的原理和应用。
SIFT算法原理
算法概述
SIFT(Scale-invariant feature transform)又称尺度不变特征转换,此算法由David Lowe在1999年所发表,2004年完善总结。
SIFT主要是用来提取图像中的关键点。相比于其它角点检测算法(如Harris和shi-toms),SIFT算法具有角度和尺度不变性,换句话说就是不容易受到图像平移、旋转、缩放和噪声的影响。
关键点和尺度空间
关键点是指在不同尺度空间的图像下检测出的具有方向信息的局部极值点。
尺度空间理论最早在1962年提出,其主要思想是通过对原始图像进 行尺度变换,获得图像多尺度下的尺度空间表示序列。
SIFT算法就是利用同一幅图像在不同尺度空间的关系来提取关键点。
尺度空间中各尺度图像的模糊程度逐渐变大,能够模拟人在距离目标由近到远时目标在视网膜上的形成过程。
算法步骤
1.通过高斯卷积构建图像金字塔
根据文献《Scale-space theory: A basic tool for analysing structures at different scales》可知,高斯核是唯一可以产生
多尺度空间的核。因此使用高斯函数和原图像进行卷积,具体公式如下图所示:
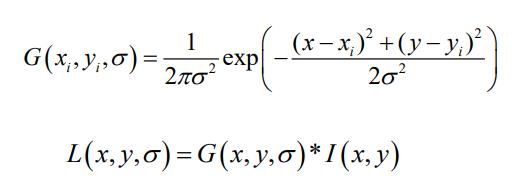
式中,G(x,y,
σ
\\sigma
σ)为高斯函数,I(x,y)表示原图像。
根据
σ
\\sigma
σ的不同取值,可以构建出不同尺度空间的图像,这样就形成了一组图像。
之后,再对这些图像进行降采样,这样就形成图像金字塔。
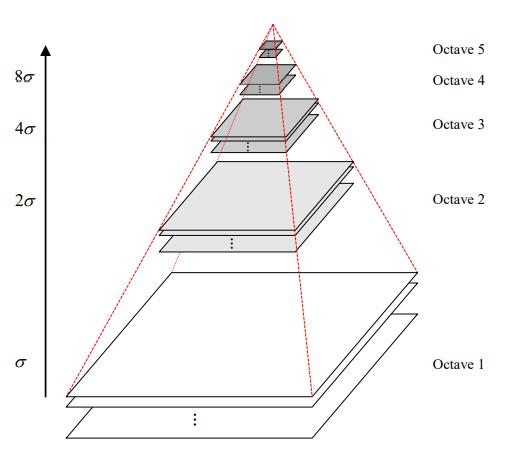
上一组图像的底层是由前一组图像的倒数第二层图像隔点采样生成的。
2.构建高斯差分金字塔
创建好图像高斯金字塔后,每一组内的相邻层相减可以得到高斯差分金字塔(DoG, Difference of Gaussian),如下图所示。
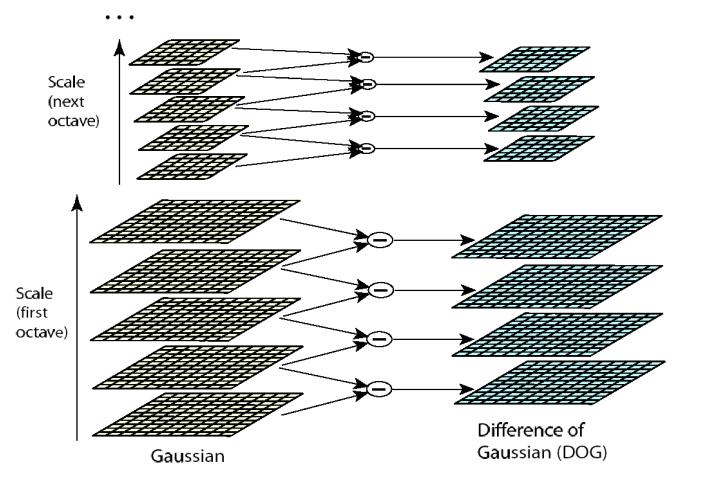
由于DOG是通过相邻层相减得到,因此层数会比高斯图像金字塔少一层。
3.关键点定位
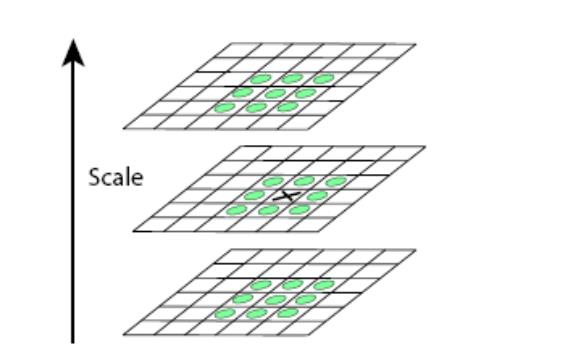
得到DOG之后,就可以在正数第二层和倒数第二层的范围中寻找极值点(第一层和最后一层无法和相邻两层进行比较)。
此时将某个点和周围26个点进行比较,比较的示意图如下图所示,图中x为比较的点,这幅图中x首先和相邻的8个点比较,然后和上下两个尺度的9*2=18个点进行比较,总共需要比较26个点。
如果该点符合极小值或极大值,则此点为离散空间中的极值点。
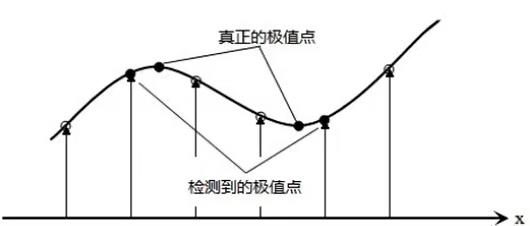
离散空间中的极值点并不是真正的极值点,因此通过离散值插值的方式,可以找到真正的极值点,这一步从公式角度较为复杂,原理大致如下图所示:
4.关键点方向赋值
通过尺度不变性求极值点,可以使其具有缩放不变的性质;为了让其具有图像旋转不变性,需要对每个关键点方向进行赋值。
每一个像素点的梯度方向和幅值计算公式如下:
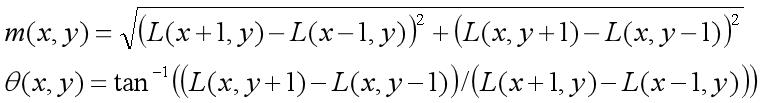
然而直接计算一个点的方向可能会存在误差,因此选取关键点附近的一块领域,对领域内每一个点的方向进行统计。
将0-360度分成8个方向,每45度为一个方向,形成8个方向的柱状图,峰值代表关键点方向,大于峰值80%的作为辅方向,示意图如下:

5.关键点描述
关键点描述的目的是在关键点计算后,用一组向量将这个关键点描述出来,用来作为目标匹配的依据。
SIFT采用4x4x8共128维向量作为特征点,取特征点周围8x8的像素范围进行梯度方向统计和高斯加权(蓝色圆圈表示加权范围),每4x4的窗口生成8个方向。箭头方向代表了像素梯度方向,箭头长度代表该像素的幅值。每个4x4的窗口形成一个种子点,一个特征点由4个种子点的信息所组成。

SIFT算法实践
下面进入到SIFT的编程实践,OpenCV的提供了非常方便的调用接口。
不同版本的OpenCV接口可能会略有区别,下面使用的OpenCV版本为4.5.4.60。
关键点检测
下面这段程序实现了一幅图片的关键点检测。
import cv2
# 读取图像,转灰度图进行检测
img = cv2.imread('Hall_1.jpg')
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# sift实例化对象
sift = cv2.SIFT_create()
# 关键点检测
keypoint = sift.detect(img_gray)
# 关键点信息查看
# print(keypoint) # [<KeyPoint 000001872E1E2960>, <KeyPoint 000001872E1E2B10>]
original_kp_set = (int(i.pt[0]), int(i.pt[1])) for i in keypoint # pt查看关键点坐标
print(original_kp_set)
# 在图像上绘制关键点的检测结果
cv2.drawKeypoints(img, keypoint, img, flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 显示图像
cv2.imshow("img", img)
cv2.waitKey()
sift.detect会返回一个KeyPoint对象,该类型有以下这些属性:
- pt(x,y):关键点的点坐标;
- size():该关键点邻域直径大小;
- angle:角度,表示关键点的方向,值为[零,三百六十),负值表示不使用。
- response:响应强度
运行之后,结果如下图所示:

配准拼接
示例代码
下面是一个两幅图像配准拼接的示例,先放代码[1]:
import time
import cv2
import numpy as np
class Stitcher:
# 拼接函数
def stitch(self, images, ratio=0.75, reprojThresh=4.0, showMatches=False):
# 获取输入图片
(imageB, imageA) = images
# 检测A、B图片的SIFT关键特征点,并计算特征描述子
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# 匹配两张图片的所有特征点,返回匹配结果
M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)
# 如果返回结果为空,没有匹配成功的特征点,退出算法
if M is None:
return None
# 否则,提取匹配结果
# H是3x3视角变换矩阵
(matches, H, status) = M
# 将图片A进行视角变换,result是变换后图片
result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
# 融合
for r in range(result.shape[0]):
left = 0
for c in range(result.shape[1] // 2):
if result[r, c].any(): # overlap
if left == 0:
left = c
alpha = (c - left) / (result.shape[1] // 2 - left)
result[r, c] = imageB[r, c] * (1 - alpha) + result[r, c] * alpha
else:
result[r, c] = imageB[r, c]
# 将图片B传入result图片最左端
# result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
# 检测是否需要显示图片匹配
if showMatches:
# 生成匹配图片
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches, status)
# 返回结果
return (result, vis)
# 返回匹配结果
return result
def detectAndDescribe(self, image):
# 将彩色图片转换成灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 建立SIFT生成器
descriptor = cv2.SIFT_create()
# 检测SIFT特征点,并计算描述子
(kps, features) = descriptor.detectAndCompute(gray, None)
# 将结果转换成NumPy数组
kps = np.float32([kp.pt for kp in kps])
# 返回特征点集,及对应的描述特征
return kps, features
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh):
# 建立暴力匹配器
matcher = cv2.DescriptorMatcher_create("BruteForce")
# 使用KNN检测来自A、B图的SIFT特征匹配对,K=2
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
for m in rawMatches:
# 当最近距离跟次近距离的比值小于ratio值时,保留此匹配对
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
# 存储两个点在featuresA, featuresB中的索引值
matches.append((m[0].trainIdx, m[0].queryIdx))
# 当筛选后的匹配对大于4时,计算视角变换矩阵
if len(matches) > 4:
# 获取匹配对的点坐标
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# 计算视角变换矩阵
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
# 返回结果
return (matches, H, status)
# 如果匹配对小于4时,返回None
return None
def drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):
# 初始化可视化图片,将A、B图左右连接到一起
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# 联合遍历,画出匹配对
for ((trainIdx, queryIdx), s) in zip(matches, status):
# 当点对匹配成功时,画到可视化图上
if s == 1:
# 画出匹配对
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1)
# 返回可视化结果
return vis
if __name__ == '__main__':
start_time = time.time()
# 读取拼接图片
imageA = cv2.imread("Hall_1.jpg")
imageB = cv2.imread("Hall_2.jpg")
# 把图片拼接成全景图
stitcher = Stitcher()
(result, vis) = stitcher.stitch([imageA, imageB], showMatches=True)
cv2.imwrite("img1.png", vis)
cv2.imwrite("img2.png", result)
end_time = time.time()
print("共耗时" + str(end_time - start_time))
特征匹配结果:

拼接结果:

代码细节解析
相比于关键点检测的任务,图像配准任务是在前者的基础上加入图像关键点匹配和图像融合的过程。下面从代码运行的角度进行过程分析:
- 首先读取两张图片,将彩色图片转换为灰度图
- 检测A、B图片的SIFT关键特征点,并计算特征描述子。
在上面的示例中,使用cv2.SIFT_create().detect来得到关键点对象,这里使用的是cv2.SIFT_create().detectAndCompute这个函数接口,该函数会返回两个值,第一个值是各关键点的坐标,第二个值是关键点描述向量,如原理部分所述,SIFT算法采用128维来描述一个关键点,因此该值的size为(关键点个数,128)。 - 设置匹配器,这里采用的匹配器为
BruteForce,BruteForce也称暴力匹配算法,即从主串头开始,依次选取和模拟串等长的子串,挨个字符匹配,如果匹配失败,立马检索下一个子串。 - 匹配策略采用KNN算法,其中K值取2,匹配时,设置了一个阈值
ratio,默认值是0.75,如果两个关键点描述向量的欧式距离之比小于0.75,则匹配成功。 - 如果匹配成功的关键点大于4,则计算视角变换矩阵,这里使用了
cv2.findHomography这个函数,参数设置使用RANSAC方法,返回变换矩阵H(3行x3列)和状态向量(status)(1表示匹配成功,0表示匹配失败) - 将第二幅图进行视角变换,这里用到这样一个函数
cv2.warpPerspective,根据变换矩阵进行仿射变换。单独将变换后的此图拿出来如下图所示:

- 最后是图像融合,因为第二幅图已经根据图一进行了仿射变换,因此,只需要将图一部分连接上去即可,问题在于如果两部分是重合的(overleap),则重合的部分亮度会明显增强。因此,这一部分主要采用了一个像素点遍历循环,只有第二幅图空缺的像素点位置被第一幅图进行填充。

填充完成后,就得到了整幅拼接的图像。
总结
整个算法在图像尺寸不大时,配准拼接速度较快。但是当图像尺寸较大时(几千x几千),速度明显较慢。一方面是Sift特征提取速度还有待提升,其次像素点的匹配是暴力匹配,效率不高;最后是图像融合是直接采用像素点遍历,速度很慢,后续有待改进。
参考
- 利用 SIFT 实现图像拼接 https://blog.csdn.net/itnerd/article/details/89157849
- OpenCV中KeyPoint类 https://blog.csdn.net/qq_41598072/article/details/99302777
- SIFT角点检测算法原理 https://www.bilibili.com/video/BV1kS4y1g7Ge
- 全网最详细SIFT算法原理实现 https://blog.csdn.net/weixin_48167570/article/details/123704075
- 基于OpenCV全景拼接(Python)https://cloud.tencent.com/developer/article/1178958
以上是关于图像配准SIFT算法原理及二图配准拼接的主要内容,如果未能解决你的问题,请参考以下文章