RabbitMQ 部署及配置详解(集群部署)
Posted Doker 多克
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RabbitMQ 部署及配置详解(集群部署)相关的知识,希望对你有一定的参考价值。
RabbitMQ 集群是一个或 多个节点,每个节点共享用户、虚拟主机、 队列、交换、绑定、运行时参数和其他分布式状态。
一、RabbitMQ 集群可以通过多种方式形成:
通过在配置文件中列出群集节点以声明方式
以声明方式使用基于 DNS 的发现
以声明方式使用 AWS (EC2) 实例发现(通过插件)
声明式使用 Kubernetes 发现(通过插件)
以声明方式使用基于 Consul 的发现(通过插件)
声明式地使用基于 etcd 的发现(通过插件)
手动使用 rabbitmqctl
二、集群部署的核心概念:
1、 仲裁队列
仲裁队列是 RabbitMQ 实现持久、 基于Raft共识算法的复制FIFO队列。 它从 RabbitMQ 3.8.0 开始可用。
仲裁队列和流取代了持久镜像队列,即原始队列 复制的队列类型,现已弃用并计划删除。
仲裁队列针对数据安全性为 重中之重。这在动机中有所介绍。 仲裁队列应被视为复制队列类型的默认选项。
与传统镜像队列相比,仲裁队列在行为上也存在重要差异和一些限制, 包括特定于工作负载的,例如,当使用者重复对同一消息重新排队时。另外仲裁队列支持死信交换 (DLX)。
仲裁队列和镜像队列差异
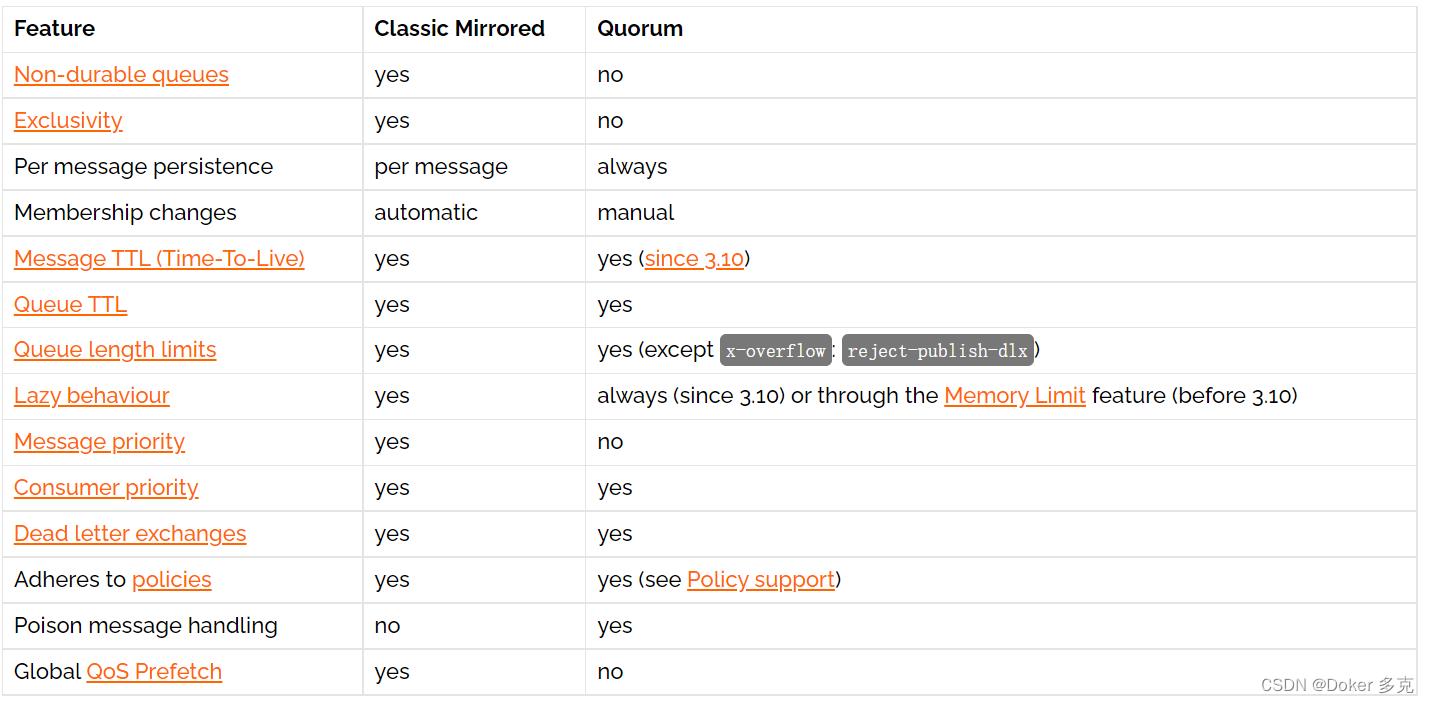
2、节点名称
RabbitMQ 节点由节点名称标识。节点名称由两部分组成, 前缀(通常是兔子)和主机名。例如,rabbit@node1.messaging.svc.local 是一个节点名称,前缀为 rabbit,主机名为 node1.messaging.svc.local。
群集中的节点名称必须是唯一的。如果给定主机上正在运行多个节点 (这通常在开发和 QA 环境中),他们必须使用 不同的前缀,例如rabbit1@hostname和rabbit2@hostname。
在群集中,节点使用节点名称相互标识和联系。这意味着 必须解析每个节点名称的主机名部分。CLI 工具还使用节点名称识别和寻址节点。
当节点启动时,它会检查是否已为其分配节点名称。这是完成的 通过RABBITMQ_NODENAME环境变量。 如果未显式配置任何值, 节点解析其主机名,并将 Rabbit 附加到它以计算其节点名称。
如果系统使用完全限定域名 (FQDN) 作为主机名,RabbitMQ 节点 并且必须将 CLI 工具配置为使用所谓的长节点名称。 对于服务器节点,这是通过将RABBITMQ_USE_LONGNAME环境变量设置为 true 来完成的。
对于 CLI 工具,必须设置 RABBITMQ_USE_LONGNAME 或 --longnames 选项 必须指定。
3、集群形成要求
主机名解析
RabbitMQ 节点使用节点名称(组合)相互寻址 前缀和域名,可以是短的还是完全限定的 (FQDN)。因此,每个集群成员都必须能够解析主机名 对于所有其他集群成员,其自己的主机名也是如此 作为可能使用 RabbitMQCTL 等命令行工具的计算机。节点将在节点引导时尽早执行主机名解析。 在基于容器的环境中,主机名很重要 在容器启动之前,解决方案已准备就绪。 对于 Kubernetes 用户来说,这意味着 CoreDNS 的 DNS 缓存间隔值在 5-10 秒范围内。
主机名解析可以使用任何标准操作系统提供 方法:
域名系统记录
本地主机文件(例如 /etc/hosts)
在限制性更强的环境中,DNS 记录或 主机文件修改受到限制、无法或 不想要的,二郎 可以将 VM 配置为使用备用主机名 解析方法,例如备用 DNS 服务器, 本地文件、非标准主机文件位置或混合 的方法。这些方法可以与 标准操作系统主机名解析方法。要使用 FQDN,请参阅配置指南中的RABBITMQ_USE_LONGNAME。
端口访问
RabbitMQ 节点绑定到端口(开放服务器 TCP 套接字)以接受客户端和 CLI 工具连接。 其他进程和工具(如 SELinux)可能会阻止 RabbitMQ 绑定到端口。当这种情况发生时, 节点将无法启动。
CLI 工具、客户端库和 RabbitMQ 节点也打开连接(客户端 TCP 套接字)。 防火墙可以阻止节点和 CLI 工具相互通信。 以下端口与群集中的节点间通信最相关:
4369:epmd,RabbitMQ 节点和 CLI 工具使用的帮助程序发现守护进程
6000 到 6500:由 RabbitMQ 流复制使用
25672:用于节点间和 CLI 工具通信(Erlang 分发服务器端口) 并且从动态范围分配(默认情况下仅限于单个端口, 计算为 AMQP 端口 + 20000)。除非这些端口上的外部连接确实是必要的(例如 群集使用联合身份验证或在子网外部的计算机上使用 CLI 工具), 这些端口不应公开。有关详细信息,请参阅网络指南。
35672-35682:CLI 工具(Erlang 分发客户端端口)用于与节点通信 并从动态范围(计算为服务器分发端口 + 10000 到 服务器分发端口 + 10010)。
可以将 RabbitMQ 配置为使用不同的端口和特定的网络接口
三、部署
1、启动独立节点
RabbitMQ CLI 工具(如 rabbitmq-diagnostics 和 rabbitmqctl)提供了检查资源和集群范围状态的命令。
通过重新配置现有 RabbitMQ 来设置集群 节点加入群集配置。因此,第一步 就是以正常方式在所有节点上启动 RabbitMQ:
# on rabbit1
rabbitmq-server -detached
# on rabbit2
rabbitmq-server -detached
# on rabbit3
rabbitmq-server -detached这将创建三个独立的 RabbitMQ 代理, 每个节点上一个,如 cluster_status 命令所确认的那样:
# on rabbit1
rabbitmqctl cluster_status
# => Cluster status of node rabbit@rabbit1 ...
# => [nodes,[disc,[rabbit@rabbit1]],running_nodes,[rabbit@rabbit1]]
# => ...done.
# on rabbit2
rabbitmqctl cluster_status
# => Cluster status of node rabbit@rabbit2 ...
# => [nodes,[disc,[rabbit@rabbit2]],running_nodes,[rabbit@rabbit2]]
# => ...done.
# on rabbit3
rabbitmqctl cluster_status
# => Cluster status of node rabbit@rabbit3 ...
# => [nodes,[disc,[rabbit@rabbit3]],running_nodes,[rabbit@rabbit3]]
# => ...done.从 rabbitmq-server shell 脚本启动的 RabbitMQ 代理的节点名称是 rabbit@shorthostname,其中 short 节点名称为小写(如rabbit@rabbit1, 以上)。在 Windows 上,如果使用 rabbitmq-server.bat 批处理文件,则短节点名称为大写(如 在rabbit@RABBIT1)。键入节点名称时, 大小写很重要,这些字符串必须完全匹配
2、创建集群
为了将集群中的三个节点链接起来,我们告诉 其中两个节点,例如rabbit@rabbit2和rabbit@rabbit3,加入 第三,说rabbit@rabbit1。在此之前,两者 新加入的成员必须重置。
我们首先在集群中加入rabbit@rabbit2 与rabbit@rabbit1。为此,在rabbit@rabbit2我们停止了 RabbitMQ 应用程序并加入rabbit@rabbit1集群,然后重新启动 RabbitMQ 应用程序。请注意, 必须先重置节点,然后才能加入现有群集。 重置节点会删除以前的所有资源和数据 存在于该节点上。这意味着节点不能成为成员 并同时保留其现有数据。当需要时, 使用蓝/绿部署策略或备份和还原是可用选项。
# on rabbit2
rabbitmqctl stop_app
# => Stopping node rabbit@rabbit2 ...done.
rabbitmqctl reset
# => Resetting node rabbit@rabbit2 ...
rabbitmqctl join_cluster rabbit@rabbit1
# => Clustering node rabbit@rabbit2 with [rabbit@rabbit1] ...done.
rabbitmqctl start_app
# => Starting node rabbit@rabbit2 ...done.我们可以看到,两个节点通过 在任一节点上运行 cluster_status 命令:
# on rabbit1
rabbitmqctl cluster_status
# => Cluster status of node rabbit@rabbit1 ...
# => [nodes,[disc,[rabbit@rabbit1,rabbit@rabbit2]],
# => running_nodes,[rabbit@rabbit2,rabbit@rabbit1]]
# => ...done.
# on rabbit2
rabbitmqctl cluster_status
# => Cluster status of node rabbit@rabbit2 ...
# => [nodes,[disc,[rabbit@rabbit1,rabbit@rabbit2]],
# => running_nodes,[rabbit@rabbit1,rabbit@rabbit2]]
# => ...done.现在我们加入rabbit@rabbit3 簇。步骤与上述步骤相同,除了 这次我们将集群到 Rabbit2 到 证明选择要群集到的节点不会 物质 - 提供一个在线节点和 节点将群集到指定的群集 节点属于。
# on rabbit3
rabbitmqctl stop_app
# => Stopping node rabbit@rabbit3 ...done.
# on rabbit3
rabbitmqctl reset
# => Resetting node rabbit@rabbit3 ...
rabbitmqctl join_cluster rabbit@rabbit2
# => Clustering node rabbit@rabbit3 with rabbit@rabbit2 ...done.
rabbitmqctl start_app
# => Starting node rabbit@rabbit3 ...done.
我们可以看到,这三个节点通过 在任何节点上运行 cluster_status 命令:
# on rabbit1
rabbitmqctl cluster_status
# => Cluster status of node rabbit@rabbit1 ...
# => [nodes,[disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]],
# => running_nodes,[rabbit@rabbit3,rabbit@rabbit2,rabbit@rabbit1]]
# => ...done.
# on rabbit2
rabbitmqctl cluster_status
# => Cluster status of node rabbit@rabbit2 ...
# => [nodes,[disc,[rabbit@rabbit1,rabbit@rabbit2,rabbit@rabbit3]],
# => running_nodes,[rabbit@rabbit3,rabbit@rabbit1,rabbit@rabbit2]]
# => ...done.
# on rabbit3
rabbitmqctl cluster_status
# => Cluster status of node rabbit@rabbit3 ...
# => [nodes,[disc,[rabbit@rabbit3,rabbit@rabbit2,rabbit@rabbit1]],
# => running_nodes,[rabbit@rabbit2,rabbit@rabbit1,rabbit@rabbit3]]
# => ...done.通过执行上述步骤,我们可以将新节点添加到 在群集运行时随时群集。
未完待续
以上是关于RabbitMQ 部署及配置详解(集群部署)的主要内容,如果未能解决你的问题,请参考以下文章