基于Flink构建实时数仓实践
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Flink构建实时数仓实践相关的知识,希望对你有一定的参考价值。
导读
随着公司用户增长业务快速发展,陆续孵化出 部落、同镇、C 端会员、游戏等非常多的业务板块。与此同时产品及运营对实时数据需求逐渐增多,帮助他们更快的做出决策,更好的进行产品迭代,实时数仓的建设变得越发重要起来。本文主要介绍用户增长业务基于 Flink 构建实时数仓的实践之路。
实时数仓1.0介绍
如下图是早期的实时计算架构,实时数据需求较少,架构简单,数据链路少,一路到底的开发模式能很快满足业务需求;

但是,随着产品和业务人员对实时数据需求的不断增多,上面的架构带来了如下的问题:
需求驱动的烟囱式开发,导致开发成本居高不下;
数据模型,数据分层缺失,导致实时计算资源成本高,数据指标一致性不可控;
数据使用场景变多,明细数据,多维分析,业务指标计算等,单一的需求驱动式开发模式难以应付多种需求场景;
基于以上的问题,我们开始构建 2.0 版本的实时计算架构。
实时数仓2.0介绍
一、模型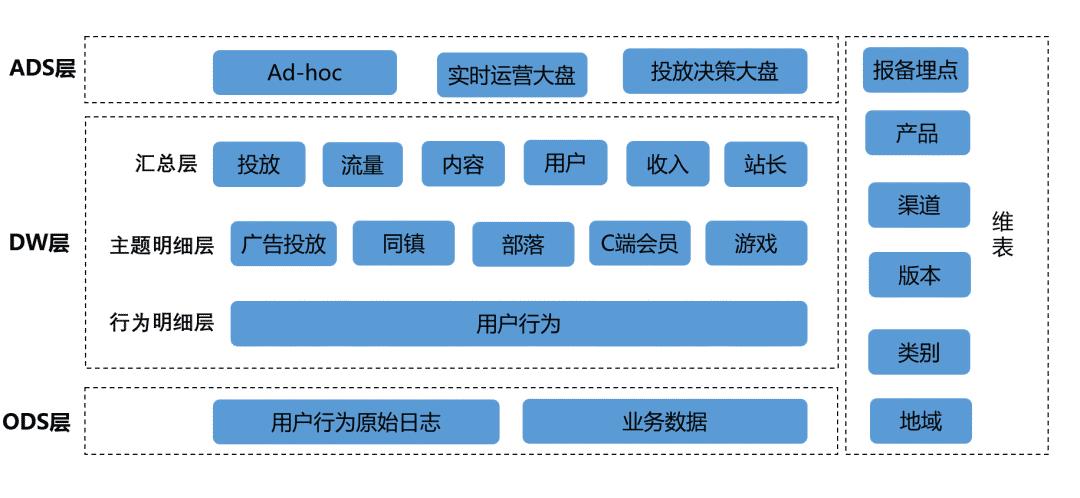
我们参考离线数仓,将实时数仓按照分层设计的思想分为三层,如上图所示,分别为:
ODS 层:存储 APP 各业务线埋点数据以及业务端各种日志;
DW 之明细层:分为公共层和业务层,APP 客户端收集的埋点数据通过关联维表,统一将产品,渠道,版本,类别,地域等客户端公共维度属性进行 ETL,并统一进行去重,过滤,分流等动作,这样就生成了公共行为明细表和业务行为明细表;然后业务明细表关联各自业务维表形成了业务主题明细表,比如同镇业务,部落业务等;
DW 之汇总层:读取业务主题明细表计算出各业务主题关心的通用维度和指标,并存储到 自研的wtable中;(wtable 是 公司自研的分布式 kv、klist 存储系统 )
ADS 层:这一层主要提供 ad-hoc 查询和实时大盘服务,其中 ad-hoc 查询是指通过 Flink 将主题明细宽表实时导入到 ClickHouse 中,为分析师和产品提供 ad-hoc 查询;而实时大盘主要是读取 wtable 中存储的DWS多维汇总指标来提供;
二、技术架构

三:实现方案
接下来我们从五个部分来讲具体的实现方案,分别为DWD构建、维表Join、Flink Sink ClickHouse、异步 Load Batch HDFS、任务与数据质量监控;
1:DWD构建
主要包括六个功能,分别为格式化、反作弊、去重、Imei-id 服务、Kafka sink exactly-once、分流。
格式化
主要是将原始日志按照 dwd 明细表的模型进行解析,并校验各字段的准确和完整性;
反作弊
主要是把线上测试渠道日志以及实时反作弊策略命中的 IMEI 进行过滤;
去重
主要是将客户端产生日志、服务端接收日志、flume 同步日志、kafka 流转日志这四个阶段产生的重复日志进行过滤,减少对业务分析和决策产生的影响;由于 APP 每日产生的用户行为日志高达数百亿条,所以如何做到高效精确去重?下面介绍两种技术方案;
方案一:redis cluster bitset 方案
实现方式是把每条日志 hash 多次,通过管道方式向 redis 集群请求 setbit 命令,通过布隆过滤的方式,判断日志是否重复。流程图如下所示:

此方案缺点是:重度依赖第三方 redis,需要解决 qps 高,redis 内存倾斜,redis 资源占用大,以及整体架构的稳定性和扩展性等问题。
方案二:flink state 状态去重方案
实现方式是使用 RocksDBStateBackend,开启增量检查点,存储大状态。根据日志数据量和日志 hash 冲突测试,设计日志去重的 key。
time 可以根据自己的去重方案设计,比如 ‘20200601’ 或者 ‘2020060112’ 等动态时间戳。使用 ValueState<Boolean> ,可以判断 distinctKey 是否存在。不存在代表不是重复日志,存在代表是重复日志。并且设置状态的过期时间为 24 小时。
流程图如下所示:

此方案基于 flink 强大的 state 功能,架构简单可靠,程序处理速度与稳定性良好。
最终我们采用方案二来实现日志去重的功能;
Imei-id 服务
主要实现如下两个功能:
一是根据 IMEI 实时判断新老用户;
二是把 IMEI 映射成一个正整数,支持使用 BitMap 计算用户留存率;
下面分四步详细介绍实现方案;
1)生成唯一 ID 方案对比:

2) 技术方案如下图所示:根据上图的方案比对,最终选择了 wtable 方案。wtable可以根据 KV 存储结构实时为每个 Imei 生成唯一数字;

3) Operator 处理流程:

如上图所示,利用 flink 状态,避免每条日志都去请求 wtable,提高处理速度。
4) 线程安全问题:
Imei 生成唯一数字 ID 服务,在一个 flink 任务中是线程安全的,可以保证 imei 对应唯一 ID;若有多个 flink 任务同时实现此服务则是不安全的。解决方案有如下两个:
方案一:运用分布式锁,保证多进程之间数据安全。由于日志数据量比较大,需要频繁加锁和释放锁,导致 Flink 程序处理逻辑比较复杂,程序处理性能低等问题;
方案二:根据 flink 的多流合并 api,把多个 kafka 数据源 Data stream 合并一个后,通过 key by imei 的方式来处理日志并生成 ID,保证了线程安全,并且架构和代码实现逻辑简单;目前我们采用的是此方案。
Kafka sink exactly-once
为了保证每条数据仅仅被处理一次,通过 Flink 两阶段提交语义来实现端到端一致性;
1)预提交阶段

2)提交阶段
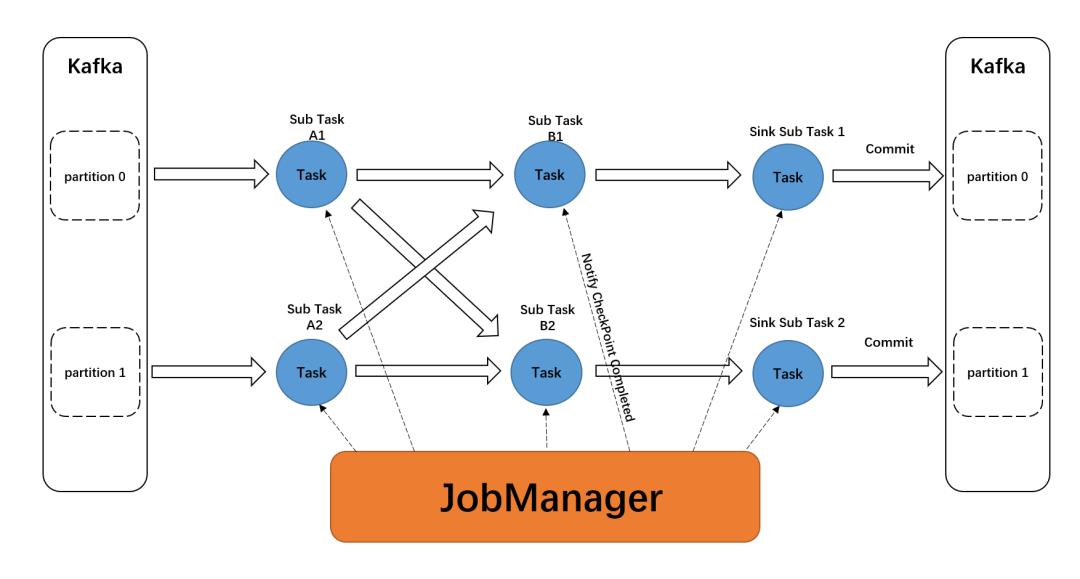
3)代码实现
1:开启 check point,设置 CheckpointingMode.EXACTLY_ONCE;
2:输出 kafka 版本需要 0.11 及以上;
3:enableCheckpointing(1000*60*5),checkpoint时间间隔为5分钟
4)手动恢复任务
1:如果程序需要重启或代码变更等情形下,从系统指定的savepoint目录进行状态恢复;
2:操作示例

分流
该功能主要目的是将APP公共行为日志按业务进行拆分,降低业务读kafka流量,节省Flink计算资源。具体实现过程为将公共行为明细日志关联埋点报备维表,将关联上的业务行为日志按照事先申请的topic进行分发。
2:维表 join
在实时数仓的建设过程中底层实时宽表的构建可谓是重中之重,如何保证实时宽表低延迟、高完整的产出是保证数据质量的关键,为此我们整理了 DataStream 层面常用的三种维表 join 方式供大家参考;
1)在 RichFlatMapFunction 的 open 方法中读取外部数据源,定时触发更新,例如加载 mysql 维表数据,在 open 方法中先读取指定维表信息,再将数据加载至内存,每次关联是取内存中匹配对应的维表数据;
优点:
实现方案简单直接
缺点:
维表更新时机不易把控可能存在 join 延迟
需要评估维表数据量级以避免内存溢出

2)将维表数据加载到热存储中,如 redis、wtabe、hbase 等。通过第三方热存储来缓存维表数据,在数据关联时直接用异步 IO 的方式从热存储获取数据并关联;
优点:
维表量级不受限与内存可加载大量数据
维表更新延迟较低(受限于维表数据写入热存储)
缺点:
需要额外热存储资源且占用一定网络开销

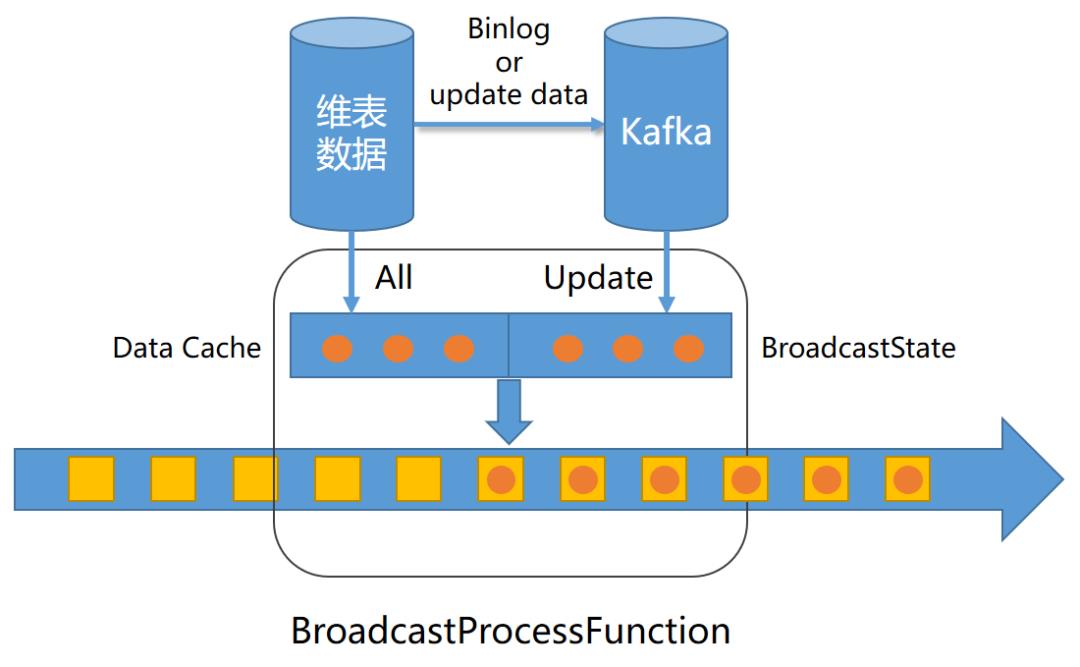
3)将维表分为全量维表和增量维表,程序启动时加载全量维表到内存,采用 BroadcastState 将增量维表数据转换为流式数据,实时 Join 主体流与维表流;
优点:
流式 Join 不依赖热存储实时更新维表数据
缺点:
需要评估维表量级避免内存溢出
3:Flink Sink ClickHouse
如下图是Flink 接入ClickHouse的流程图 ,我们基于jdbc实现了高可靠的ClickHouse Sink,依据DataTime或DataSize实现了流数据低延迟导入CK;

4:异步 Load Batch HDFS
1:流程图

2:实现方案
(1)采用10分钟一个分区,按照 dt,hour,minute 层级目录划分;
(2)hdfs sink 的方案
如果写入的 hdfs 版本小于 2.7,则选择 BucketingSink;
如果写入的 hdfs 版本大于等于 2.7,则选择 StreamingFileSink 或者 BucketingSink;
当前平台的 hadoop 版本为 2.6,故采用了 BucketingSink 方案;
(3)日志实时写入 hdfs 文件的方案
目前是每分钟数据落地到 hdfs 上;
根据日志量与 hadoop 设置的块大小,目前采用的是 256M 落地到 hdfs 上;
代码示例:
sink.setBatchRolloverInterval(1 * 60 * 1000L);
sink.setBatchSize(1024 * 1024 * 256L)
(4)日志落地 hdfs 时间分区的方案选择
根据日志 EventTime 落地,数据写入 EventTime 对应的时间分区目录下,如图:
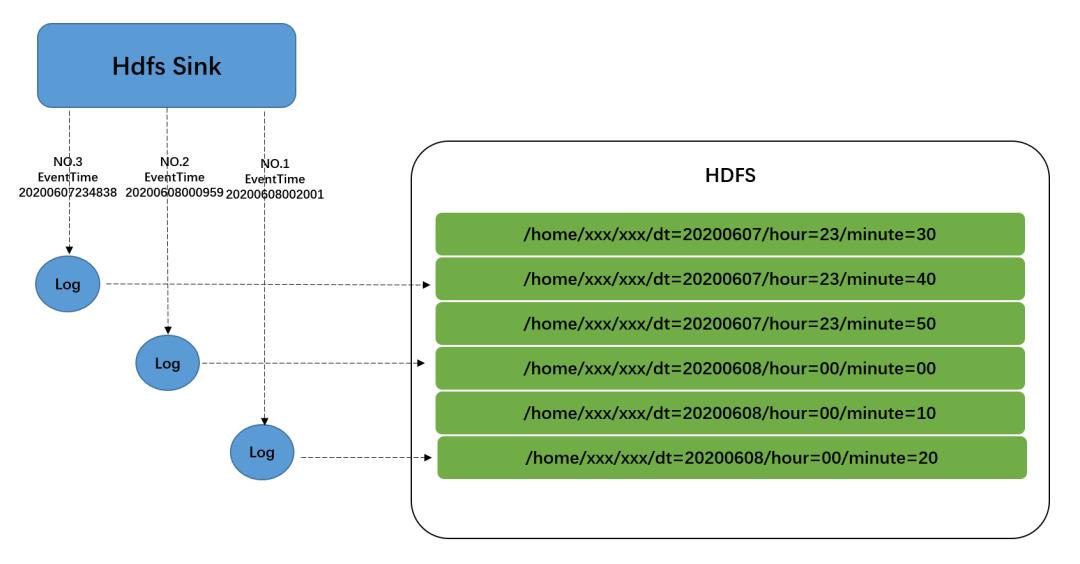
优点:数据分区准确,延迟的数据也会归位到真实的时间分区下。
缺点:若有延迟数据,每次查询历史分区,数据计算结果会发生变化。
根据日志 ProcessingTime 落地,数据写入当前系统时间分区目录下,如图:

优点:没有日志回溯问题,每次查询历史分区,数据计算结果不变。
缺点:如果发生数据延迟,数据只会追加到当前处理时间的分区目录下,不能真实反映数据分布情况。
最终方案
经过线上任务实际测试,在正常情况下数据延迟率比较低,通常在秒级别,所以采用两种时间结合的方案。即在 每天的 0 点 0 分-0 点 5 分时间段,采用 EventTime 时间处理,尽可能保证延迟数据不出现跨天的问题。其他时间段采用 ProcessingTime 时间处理,保证数据多次计算结果一致。
(5) Hdfs sink exactly-once
开启 check point,设置 CheckpointingMode.EXACTLY_ONCE;
hdfs sink 输出的格式需要指定为 text 格式;
若需要重启 flink 任务,需要指定上一次 savepoint 的 hdfs 文件路径;
由于 hadoop 2.6 版本不支持 truncate,flink 任务重启后需要人工干预处理 hdfs 的文件,才能保证 hdfs sink 端到端一致性。
编写脚本,处理 flink 任务重启后生成的 hdfs 文件;
(6)实时 hive 表与分区
创建外部表,设置 location 为日志写入 hdfs 的路径;
通过定时任务动态建立 dt、hour、minute 的分区;
5:任务与数据质量监控
1:实时任务监控,在大数据平台自建的 Flink 开发平台 Wstream 系统中,针对任务提供了 QPS、GC、CPU、Lag 延迟、内存使用等多维度的监控指标配置,一旦触发规则进行实时报警,系统监控如图所示:

2:实时数据质量监控
在实时数仓中,我们主要关注四个指标,分别是完整性,准确性,一致性,及时性,并按一分钟粒度进行统计监控;
完整性:指的是在 ETL 代码中校验日志格式是否符合规范以及关键埋点是否存在,并实时将结果存储到 DB 中,一旦触发监控规则就进行报警;
准确性:指的是在 ETL 代码中校验日志关键埋点参数值是否正确,并实时将结果存储到 DB 中,一旦触发监控规则就进行报警;
一致性:指的是在 ODS,DWD,DWS 层按一分钟粒度计算各层 topic 读入量,过滤量,输出量,通过统计各分层的这三个值可以监控当前实时数仓在每一层流转过程中数据条数的差异,从而保障实时数仓的一致性;为了及时排查问题,我们将各层过滤日志实时落地 HIVE 来加速问题定位;
及时性:指的是监控各分层中 Flink 程序 ProcessingTime 和日志 EventTime 的差值,通过该值来监控实时数仓的延迟率;
如下图是其中一个质量指标监控效果图:

进展与收益
在 1.0 阶段,离线数仓采用 flume 传输到 Hdfs 后构建,实时数仓采用 kafka流转并 进行计算;在 2.0 阶段,通过 Flink 实时落地 Hive,我们在 ODS,DWD,DWS 层实现了离线和实时数仓的一致性,解决了 1.0 阶段离线和实时数仓由于采集存储通道不同,ETL 不一致,数据源不一致等几个核心痛点。
通过在 DWD 用户行为明细层统一 ETL 和分流,将我们支持的部落,同镇,广告投放,游戏,C 端 VIP 等多个业务进行流量日志自动化拆分。由于各业务消费的是分流后的 topic,Flink 任务消费 kafka 流量下降了一个数量级,从而降低了 Flink 计算资源成本。
通过实时数仓分层建设,业务指标和计算口径的变更,只需要在明细层的 ETL 任务中进行一次变更即可满足下游所有任务,解决了之前需要多个计算任务同时变更的问题,从而保证了业务指标一致性。
通过基于 Flink 实时导入 ClickHouse 的各业务明细宽表,产品及分析师可以快速便捷的进行实时 Ad-Hoc 查询,避免了 1.0 阶段每个实时需求都需要排期开发,极大的提高了产品运营分析效率。
通过基于 Flink 实时数仓模型分层和元数据构建,各业务基于明细宽表通过 FlinkSQL 的方式就可以很快速的进行实时任务的开发,需求开发周期从周下降到天级别,极大的提升了开发效率。
未来展望
从实时数仓 1.0 到 2.0,不管是数据架构还是技术方案,我们在深度和广度上都有了更多的积累。随着公司业务的快速发展以及新技术的不断推出,实时数仓也会不断的迭代优化。后续我们会从以下方面进一步提升实时数仓的服务能力。
实时数仓血缘关系的完善,提升任务和表的质量监控;
Streaming SQL 持续改造和推进,可以有效减少jar文件开发方式的代码维护成本;
Flink 作业的监控,比如 checkpoint 的监控 ,目前 checkpoint 对开发者来说是黑盒,采用 exactly-once 会对实时程序的性能造成一定程度上的下降,所以该部分的持续优化和监控非常重要。
进一步强化实时任务的健壮性,包括自动化压测以及极端情况下状态的丢失等各种情况下的预案。
Java与大数据架构
7年老码农,10W+关注者。【Java与大数据架构】全面分享Java编程、Spark、Flink、Kafka、Elasticsearch、数据湖等干货。欢迎扫码关注!

以上是关于基于Flink构建实时数仓实践的主要内容,如果未能解决你的问题,请参考以下文章