清华郑纬民院士:AI for Science的出现,让高性能计算与AI的融合成为刚需|MEET2023...
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了清华郑纬民院士:AI for Science的出现,让高性能计算与AI的融合成为刚需|MEET2023...相关的知识,希望对你有一定的参考价值。
杨净 整理自 MEET2023
量子位 | 公众号 QbitAI
算力的需求,远比以往来得更为猛烈。甚至有人直呼:得算力者得未来。
元宇宙、AIGC、AI for Science的涌现,又给高性能计算(HPC)平添了好几把火。
在诸多挑战与机遇共存交织的当下,这一领域泰斗中国工程院院士、清华大学计算机科学与技术系郑纬民,在MEET2023智能未来大会上,分享了自己的见解和思考。
估计未来两年到四年,HPC(高性能计算)+AI+BigData融合的服务器就会出现。
AI for Science的出现,让HPC+AI的融合成为刚性需求;而数据处理又是AI的基础,数据和AI的融合也很自然。
甚至他还开玩笑说,现在要获HPC领域的戈登贝尔奖,必须要有AI的算法。你没有AI的算法,否则奖都得不了。
虽然这是玩笑说法,但实际上也是一种趋势。
除此之外,他还谈到人工智能计算机设计的三大平衡性原则、AI基准设计四大目标以及如何通过并行方法加速大规模预训练模型。

为了完整体现郑纬民院士的分享及思考,在不改变原意的基础上,量子位对他的演讲内容进行了编辑整理。
关于MEET 智能未来大会:MEET大会是由量子位主办的智能科技领域顶级商业峰会,致力于探讨前沿科技技术的落地与行业应用。今年共有数十家主流媒体及直播平台报道直播了MEET2023大会,吸引了超过300万行业用户线上参会,全网总曝光量累积超过2000万。
演讲要点
估计未来两年到四年,HPC(高性能计算)+AI+BigData融合的服务器就会出现。过去HPC是一台机器、AI是一台机器,大数据处理是第三台机器,这三个机器自己管自己,但现在这三台机器正在融合之中;
AI基准设计要达到四个目标:统一的一个分数、可变的问题规模、具有实际的人工智能意义、评测程序包含必要的多机通信;
现在要获HPC领域的戈登贝尔奖,必须要有AI的算法,你没有AI的算法,否则奖都得不了。这是开玩笑的说法,但实际上也是一个趋势;
AI for Science的出现,让HPC+AI的融合成为刚性需求;
探索更大参数量模型的效果,是具有重要科学意义的;
我们希望人工智能计算机跟HPC有TOP 500一样,也有一个AIPerf 500。
(以下是郑纬民院士演讲全文)
人工智能计算机设计的三大平衡性原则
今天给大家讲讲我们团队为人工智能做的三件事,就是AI与算力基础设施的设计、评测和优化。

第一件事,HPC(高性能计算)和AI的应用是不一样的。
HPC的应用领域主要有科学和工程计算、天气预报、核聚变模拟、飞行器设计。它的运算精度是双精度浮点运算,64位甚至128位的,所以加减乘除做得很快,主要是这点不同。
人工智能计算机就是半精度的,甚至是定点的,8位的、16位的、32位的。

因此这两台机器应该是不一样的,而人工智能计算机最近两年才开始有。因此我们团队设计了一台能比较好地处理人工智能问题的计算机,究竟长什么样子?
我们团队第一个贡献,是人工智能计算机设计的平衡性原则。
第一个,计算平衡设计。人工智能是处理单精度的或者定点的,你这台机器是不是只要把定点的、单精度的做好就行了?但实际上也不是。虽然我们主要考虑半精度运算,但是也要考虑到双精度运算的能力。
这两年下来有一个经验:
1)双精度与半精度的运算性能之比1:100比较好。
2)人工智能计算机不能只做CNN的,还要做大模型训练。
因此,提出来叫变精度平衡设计思想,总体来说还要增加通用计算。
第二,网络平衡设计,既然这台机器很大,由上千个、上万个小机器连在一起,那么这个网络也要做得好。如果只做CNN那就好办,但还要考虑训练。这样一来,网络怎么做平衡设计也非常重要。
第三,存储,即IO子系统设计。我们知道现在每台机器都有SSD,怎么把每台SSD联合起来开成一个大的分布式文件系统?这也是很要紧的。
因此,我们提出来这三个平衡设计原则,已被很多公司采用。现在国内20多个城市陆续启动人工智能超算中心,让算力无处不在、触手可及,这其中大多数都用上了平衡设计这个想法。
目前行业有个趋势是HPC+AI+BigData融合在一块。过去HPC是一台机器、AI是一台机器,大数据处理是第三台机器,这三个机器自己管自己,但现在这三台机器正在融合之中。
为何这么说呢?
一方面,AI for Science的出现,让HPC程序中包含了AI算法。因此HPC+AI的融合,成为刚性需求。
我曾经开玩笑说,你现在要获HPC的领域戈登贝尔奖,必须要有AI的算法,你没有AI的算法,否则奖都得不了。这是开玩笑的说法,但实际上也是一个趋势。
另一方面,数据处理是AI的基础,数据和AI的融合也很自然。因此,我估计两年到四年,HPC、AI和BigData融合的服务器就会出现。

这是我们小组第一个贡献,即人工智能计算机应该长成什么样子。
AI基准设计要达四个目标
第二个贡献,大规模人工智能算力基准评测程序AIPerf。
什么意思呢?传统HPC有个评测程序Linpack,TOP500就是它评出来的,但它不能用于AI计算机评测。Linpack是用来测64位,甚至128位加减乘除做的快慢。现在人工智能计算机是16位、32位,甚至8位,这是完全不一样。

因此,我们需要做一个能回答这个问题的人工智能算力基准测试程序。我们希望有个简单的评价指标,来判断哪家系统的人工智能算力更强。
那现在有没有相应的评测程序呢?其实也有,但没有太合适的。
比如,DeepBench针对单个芯片,不适用于整机评测。Mobile AI Bench针对的是移动端硬件上的模型训练评测,不是整个系统的。MLPerf可扩展性不好。因此,我们决定要自己做一个。
做个AI基准设计一定要达到这四个目标:
1、统一的分数。我们希望运行Benchmark出来一个值,就一个值就行了。而不是结果出来一个报告,这样看起来很费劲。
2、可变的问题规模。Benchmark可以测4个节点组成的机器,也可以测1000个、20000个,要规模可变,大规模的做起来也挺费劲。
3、具有实际的人工智能意义。不能随便说加减乘除,那就不能反映人工智能的问题。特别是要反映人工智能问题中的神经网络运算、自然语言处理能力。
4、评测程序包含必要的多机通信,因为是一个大的系统,由多机连起来的,需要有通信。
最后,以清华大学为主的团队做了一个AIPerf来测试,于2020年11月15日首次发布。我们希望人工智能计算机跟HPC有TOP 500一样,也有一个AIPerf 500。
现在它已经连续三年每年都发布排行榜,得到了很多单位、企业的认可。
大规模预训练模型的三种并行加速方法
第三个贡献,百万亿参数超大规模训练模型的加速方法。
简单举个例子,学界至今已形成一个共识:模型规模和模型效果呈正相关关系。GPT有1.1亿参数,GPT-3有1750亿参数,悟道2.0有1.75万亿参数,我们做的BaGuaLu却有174万亿参数,应该说参数越多,效果越好,越接近人的智慧,但有个问题就是,训练数据越多,要求的算力也就越大。
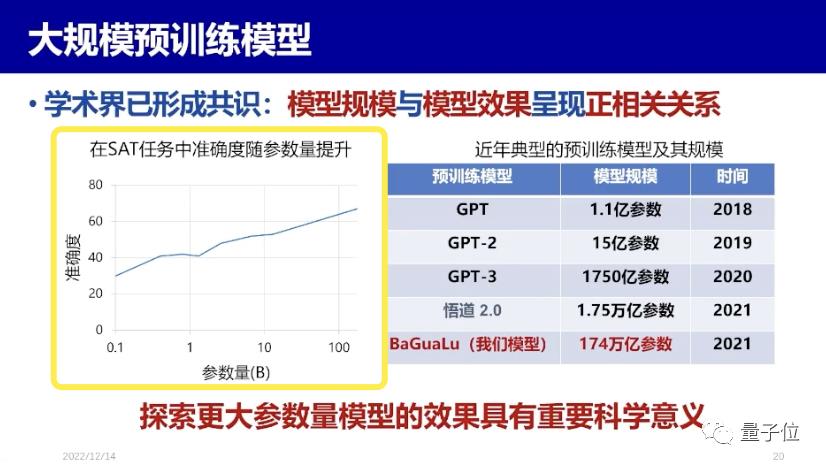
再来看左边这张图SAT(美国高考)任务的情况,如果模型参数达到100B(相当于1000亿个参数),那么模型完成SAT,就有70%的准确度。
因此,探索更大参数量模型的效果,是具有重要科学意义的。
但模型越做越大,问题随之而来。现在国内很多单位模型都做得很好,但怎么把模型安装到一台机器上去,这有讲究。
举个例子,我们就将BaGuaLu模型安装到了新一代神威体系结构芯片上。
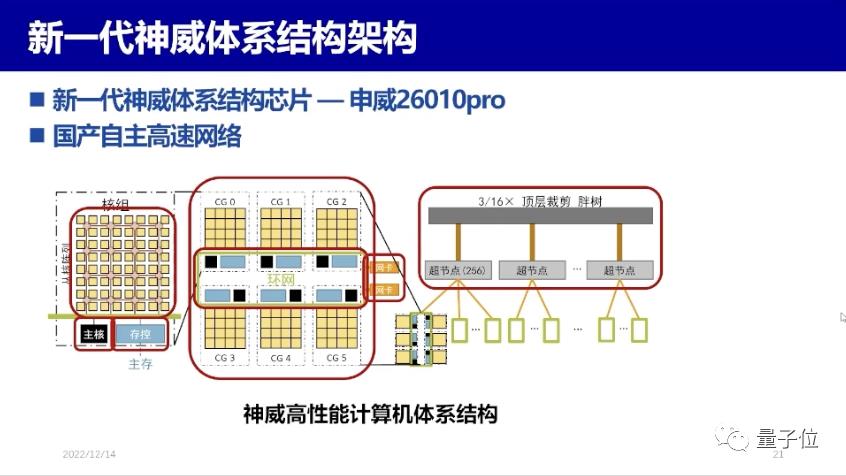
图上可以看到,核组共有64个核,再加上黑色主核,共有65个核。一个CPU共有6个这样的组成:CG0、CG1、CG2、CG3、CG4、CG5,这6个通过环形网连在一起。我们称之为一个节点,将它集成到一块,一个节点大概有390个核。一共有256个节点组成超节点,超节点内部通信一步直联,超节点跟超节点之间要经过上层的网络。
因此,256个节点内部通信很快,一步就到。但超节点之间的通信就比较慢了。
而要将大模型在这台机器上运行,问题就来了。现在预训练模型都是Transfomer,而Transfomer结构是嵌入层、注意力层、前反馈网络层,中间注意力层跟前反馈层都会经过N次迭代,整个运算又基本上是矩阵乘法。
如果一个模型能在单个CPU上运算,那最省事了,但CPU的计算能力有限,内存也有限,模型也就大不到哪里去。因此大模型训练一定是多机的、分布的,这就涉及到了多种并行方法。
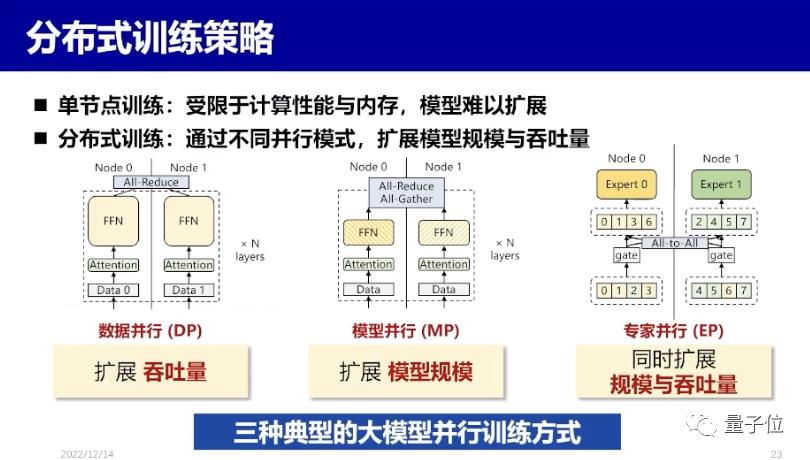
第一种,数据并行。假如整个模型设两个节点,一个模型节点0、另一个模型做的节点1,整个模型都做了数据并行,数据各一半要拿去训练学习,但是要注意训练完了以后不是最终的结果,因为只输入了一半的数据。因此这中间要AII-Reduce,AII-Reduce就做好多通信,整件事情就会很复杂。
第二种,模型并行。将整个模型切成一半,一半模型节点0,一半模型节点1,数据是整个拿去训练。训练完了以后出来的结果也不是最终结果,因为只训练了一半的模型,出来还有AII-Gather,也是做通信的。
第三种,专家并行,跟数据并行、模型并行一样,同样要求通信。
现在如果你只有一种方法,究竟用哪种并行方法呢?实际上这跟计算机结构有关。如果每台计算机之间通信都非常快,那么用数据并行就可以;如果你的通信比较慢,就要考虑模型并行或者专家并行。
因此,这些模型如何跟数据、机器实际情况匹配?这就涉及到软硬件协同这件事。
我们在新一代神威机器上采用了“拓扑感知的混合并行模式”。
具体而言,刚才提到,该体系架构节点内部通信很快,但超节点之间通信比较慢。因此在混合并行模式下,一个通信超节点内部,采用数据并行;超节点之间则采用专家并行或模型并行。
除此之外,还有内存大小、访问内存等问题:怎么样让内存访问的比较快,负载比较均衡?
做大规模模型训练时,平均每小时都会发生一次硬件软件出错,不要以为这个机器不可靠。目前这个水平已经很好了。因此,一般都要做检查点,如果写的不好,这件事情就有做三个小时,怎么能让它加速呢?最后我们做到了10分钟就完成了。
现在,我们把模型开源了,尤其是并行训练模型,将他们放在了开源系统FastMOE里,现在得到了工业界很多认可,像阿里巴巴的淘宝、天猫,腾讯的端到端语言模型,都用上了我们的并行系统。百度飞桨的MOE模块,也使用了我们的FastMOE。
最后总结一下,一是人工智能算力是当前人工智能领域发展的关键。
二是团队对人工智能的三点小贡献:
1)提出了一种AI算力基础设施的架构和平衡设计原则,现在全国20多个城市的20多个人工智能超算中心基本上都采纳了我们的设计思想。
2)做了评测,即人工智能基准测试程序AIPerf,现在每年都会发布500名榜单,在国内外产生了一定影响。
3)大模型怎么训练得快?特别是关于数据并行、模型并行,还是专家并行。我们做了一个库放在Open Source上。现在工业界都来用我们的东西,使得大训练模型训练能够加快。
因此,我们团队对人工智能做了这三点小贡献,希望能够推动人工智能的发展。
讲的不对的地方请大家批评指正。谢谢大家!
(最后,如果想回看大会全程,请点击阅读原文)
以上是关于清华郑纬民院士:AI for Science的出现,让高性能计算与AI的融合成为刚需|MEET2023...的主要内容,如果未能解决你的问题,请参考以下文章
中国工程院院士:分布式数据存储成为维持元宇宙持久运转的基本方式