ClickHouse vs Elasticsearch谁更胜一筹?
Posted androidstarjack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ClickHouse vs Elasticsearch谁更胜一筹?相关的知识,希望对你有一定的参考价值。
点击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识 Elasticsearch和ClickHouse都是支持分布式 多机的数据产品!

背景:
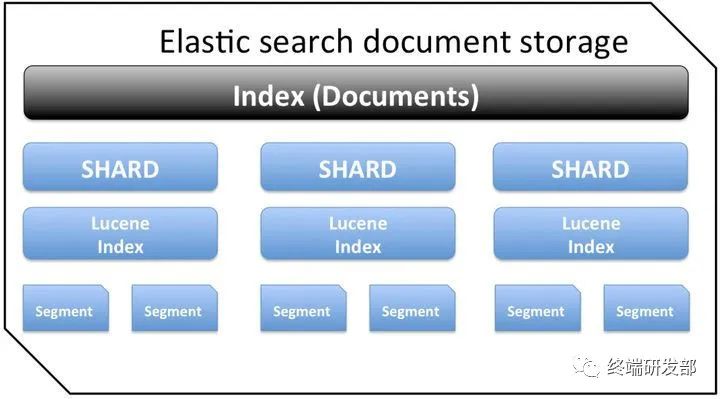
Elasticsearch
Elasticsearch 是一个实时的分布式搜索分析引擎,它的底层是构建在Lucene之上的。简单来说是通过扩展Lucene的搜索能力,使其具有分布式的功能。ES通常会和其它两个开源组件logstash(日志采集)和Kibana(仪表盘)一起提供端到端的日志/搜索分析的功能,常常被简称为ELK。
Clickhouse
Clickhouse是俄罗斯搜索巨头Yandex开发的面向列式存储的关系型数据库。ClickHouse是过去两年中OLAP领域中最热门的,并于2016年开源。
Elasticsearch的搜索引擎支持三种不同模式的搜索方式:query_and_fetch,query_then_fetch,dfs_query_then_fetch。第一种模式很简单,每个分布式节点独立搜索然后把得到的结果返回给客户端,第二种模式是每个分布式存储节点先搜索到各自TopN的记录Id和对应的score,汇聚到查询请求节点后做重排得到最终的TopN结果,最后再请求存储节点去拉取明细数据。这里设计成两轮请求的目的就是尽量减少拉取明细的数量,也就是磁盘扫描的次数。最后一种方式是为了均衡各个存储节点打分的标准,先统计全局的TF(Term Frequency)和DF(Document Frequency),再进行query_then_fetch。Elasticsearch的搜索引擎完全不具备数据库计算引擎的流式处理能力,它是完全回合制的request-response数据处理。当用户需要返回的数据量很大时,就很容易出现查询失败,或者触发GC。一般来说Elasticsearch的搜索引擎能力上限就是两阶段的查询,像多表关联这种查询是完全超出其能力上限的。
ClickHouse的计算引擎特点则是极致的向量化,完全用c++模板手写的向量化函数和aggregator算子使得它在聚合查询上的处理性能达到了极致。配合上存储极致的并行扫描能力,轻松就可以把机器资源跑满。ClickHouse的计算引擎能力在分析查询支持上可以完全覆盖住Elasticsearch的搜索引擎,有完备SQL能力的计算引擎可以让用户在处理数据分析时更加灵活、自由。
ClickHouse VS ES
ES 的底层是 Lucenc,主要是要解决搜索的问题。搜索是大数据领域要解决的一个常见的问题,就是在海量的数据量要如何按照条件找到需要的数据。搜索的核心技术是倒排索引和布隆过滤器。
ES 通过分布式技术,利用分片与副本机制,直接解决了集群下搜索性能与高可用的问题。
ClickHouse是基于MPP架构的分布式ROLAP(关系OLAP)分析引擎。每个节点都有同等的责任,并负责部分数据处理(不共享任何内容)。ClickHouse 是一个真正的列式数据库管理系统(DBMS)。在 ClickHouse 中,数据始终是按列存储的,包括矢量(向量或列块)执行的过程。让查询变得更快,最简单且有效的方法是减少数据扫描范围和数据传输时的大小,而列式存储和数据压缩就可以帮助实现上述两点。Clickhouse同时使用了日志合并树,稀疏索引和CPU功能(如SIMD单指令多数据)充分发挥了硬件优势,可实现高效的计算。Clickhouse 使用Zookeeper进行分布式节点之间的协调。

可能有很多小伙伴对ClickHouse不怎么了解
ClickHouse核心特性
1. 列存储
2. 向量化执行
3. 编码压缩
4. 多索引
5. 物化视图(Cube/Rollup)
6.支持主键索引
索引
ClickHouse支持主键索引(一级索引),它将每列数据按照index granularity(默认8192行)进行划分,每个index granularity的开头第一行被称为一个mark行。主键索引存储该mark行对应的primary key的值。

对于where条件中含有primarykey的查询,通过对主键索引进行二分查找,能够直接定位到对应的index granularity,避免了全表扫描从而加速查询。
ClickHouse还支持二级索引(跳数索引),二级索引是在一级索引的基础上建立的,有一个重要的参数:granularity = 3,这个参数的意思是:在3段一级索引上创建二级索引。
ClickHouse 的优势:
1、ClickHouse 写入吞吐量大,单服务器日志写入量在 50MB 到 200MB/s,每秒写入超过 60w 记录数,是 ES 的 5 倍以上。
2、在 ES 中比较常见的写 Rejected 导致数据丢失、写入延迟等问题,在 ClickHouse 中不容易发生。
3、查询速度快,官方宣称数据在 pagecache 中,单服务器查询速率大约在 2-30GB/s;没在 pagecache 的情况下,查询速度取决于磁盘的读取速率和数据的压缩率。经测试 ClickHouse 的查询速度比 ES 快 5-30 倍以上。
4.ClickHouse与Elasticsearch一样,都采用列式存储结构,都支持副本分片,不同的是ClickHouse底层有一些独特的实现,如下:
MergeTree 合并树表引擎,提供了数据分区、一级索引、二级索引。
Vector Engine 向量引擎,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用CPU。

ClickHouse 仍然年轻,虽然在某些方面存在不足,但极致性能的存储引擎,使得 ClickHouse 成为一个非常优秀的存储底座。
总结:
Elasticsearch产品功能全面,适用范围广,性能也不错,综合应用是首选。
Elasticsearch在搜索查询领域,几乎完胜所有竞争产品,在笔者的技术栈看来,关系型数据库解决数据事务问题,Elasticsearch几乎解决一切搜索查询问题。
但是Elasticsearch局限性也很明显,一是数据量超过千万或者亿级时,若聚合的列数太多,性能也到达瓶颈;二是不支持深度二次聚合,导致一些复杂的聚合需求,需要人工编写代码在外部实现,这又增加很多开发工作量。
在同样的服务器资源可以承担更多的业务需求下,优选ClickHourse!
向我们公司后面引入了ClickHouse,替代Elasticserach做深度聚合需求,性能表现不错,在数据量千万级亿级表现很好,且资源消耗相比之前降低不少!
最后说一句(别白嫖,求关注)
回复 【idea激活】即可获得idea的激活方式
回复 【Java】获取java相关的视频教程和资料
回复 【SpringCloud】获取SpringCloud相关多的学习资料
回复 【python】获取全套0基础Python知识手册
回复 【2020】获取2020java相关面试题教程
回复 【加群】即可加入终端研发部相关的技术交流群
阅读更多
用 Spring 的 BeanUtils 前,建议你先了解这几个坑!
lazy-mock ,一个生成后端模拟数据的懒人工具
在华为鸿蒙 OS 上尝鲜,我的第一个“hello world”,起飞!
字节跳动一面:i++ 是线程安全的吗?
一条 SQL 引发的事故,同事直接被开除!!
太扎心!排查阿里云 ECS 的 CPU 居然达100%
一款vue编写的功能强大的swagger-ui,有点秀(附开源地址)
相信自己,没有做不到的,只有想不到的在这里获得的不仅仅是技术!
喜欢就给个“在看”以上是关于ClickHouse vs Elasticsearch谁更胜一筹?的主要内容,如果未能解决你的问题,请参考以下文章