最全Go select底层原理,一文学透高频用法
Posted 腾讯云开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了最全Go select底层原理,一文学透高频用法相关的知识,希望对你有一定的参考价值。
 导语 |在日常开发中,select语句被高频使用。但目前,全网分析select在编译期和运行时的完整底层原理资料,非常匮乏。本文基于Go1.18.1版本的源码,讲解select访问Channel在编译期和运行时的底层原理——select编译器优化用到的src/cmd/compile/internal/walk/select.go的walkSelectCases()函数和多case情况下运行时用到的runtime.selectgo()函数。希望能帮助到各位开发者。
导语 |在日常开发中,select语句被高频使用。但目前,全网分析select在编译期和运行时的完整底层原理资料,非常匮乏。本文基于Go1.18.1版本的源码,讲解select访问Channel在编译期和运行时的底层原理——select编译器优化用到的src/cmd/compile/internal/walk/select.go的walkSelectCases()函数和多case情况下运行时用到的runtime.selectgo()函数。希望能帮助到各位开发者。
在对Channel的读写方式上,除了我们通用的读 i <- ch, i, ok <- ch,写 ch <- 1 这种阻塞访问方式,还有select关键字提供的非阻塞访问方式。
在日常开发中,select语句还是会经常用到的。可能是channel普通读写的使用频率比select高,网上关于Channel源码的分析文章很多,关于select用法的文章也很多,select运行时的selectgo函数的分析也有一些,但是关于select在编译期和运行时的完整的底层原理的分析文章并不多。
本文的分析基于Go1.18.1版本的源码,主要分析select编译器优化用到的src/cmd/compile/internal/walk/select.go的walkSelectCases()函数和多case情况下运行时用到的 runtime.selectgo()函数。
 结论先行
结论先行
为了节省各位开发者时间,本文先给出结论,若您时间不足可以先看完本节并收藏,后续再持续阅读消化:
第一,Go select语句采用的多路复用思想,本质上是为了达到通过一个协程同时处理多个IO请求(Channel读写事件)。
第二,select的基本用法是:通过多个case监听多个Channel的读写操作,任何一个case可以执行则选择该case执行,否则执行default。如果没有default,且所有的case均不能执行,则当前的goroutine阻塞。
第三,编译器会对select有不同的case的情况进行优化以提高性能。首先,编译器对select没有case、有单case和单case+default的情况进行单独处理。这些处理或者直接调用运行时函数,或者直接转成对channel的操作,或者以非阻塞的方式访问channel,多种灵活的处理方式能够提高性能,尤其是避免对channel的加锁。
第四,对最常出现的select有多case的情况,会调用 runtime.selectgo() 函数来获取执行 case 的索引,并生成 if 语句执行该case的代码。
第五,selectgo函数的执行分为四个步骤:首先,随机生成一个遍历case的轮询顺序 pollorder 并根据 channel 地址生成加锁顺序 lockorder,随机顺序能够避免channel饥饿,保证公平性,加锁顺序能够避免死锁;然后,根据 pollorder 的顺序查找 scases 是否有可以立即收发的channel,如果有则获取case索引进行处理;再次,如果pollorder顺序上没有可以直接处理的case,则将当前 goroutine 加入各 case 的 channel 对应的收发队列上并等待其他 goroutine 的唤醒;最后,当调度器唤醒当前 goroutine 时,会再次按照 lockorder 遍历所有的case,从中查找需要被处理的case索引进行读写处理,同时从所有case的发送接收队列中移除掉当前goroutine。
 select是什么?怎么用?
select是什么?怎么用?
select是Go在语言层面提供的I/O多路复用的机制,其专门用来检测多个channel是否准备完毕:可读或可写。
1)什么是IO多路复用?
我们一看到select,就知道它原本是Linux操作系统中的系统调用。操作系统提供 select、poll 和 epoll 等函数构建 I/O 多路复用模型提升程序处理IO事件如网络请求的性能。Go 语言的 select 与操作系统中的 select 比较相似但又不完全相同。
操作系统中IO多路复用中多路就是多个TCP连接,复用就是指复用一个或少量线程,理解起来就是多个网络连接的IO事件复用一个或少量线程来处理这些连接。一句话概括就是,IO多路复用就是复用一个线程处理多个IO请求。
普通多线程IO 如图1.1所示,每来一个IO事件,比如网络读写请求事件,操作系统都会起一个线程或进程进行处理。这种方式的缺点很明显:对多个IO事件,系统需要创建和维护对应的多个线程或进程。大多数时候,大部分IO事件是处于等待状态,只有少部分会立即操作完成,这会导致对应的处理线程大部分时候处于等待状态,系统为此还需要多做很多额外的线程或者进程的管理工作。
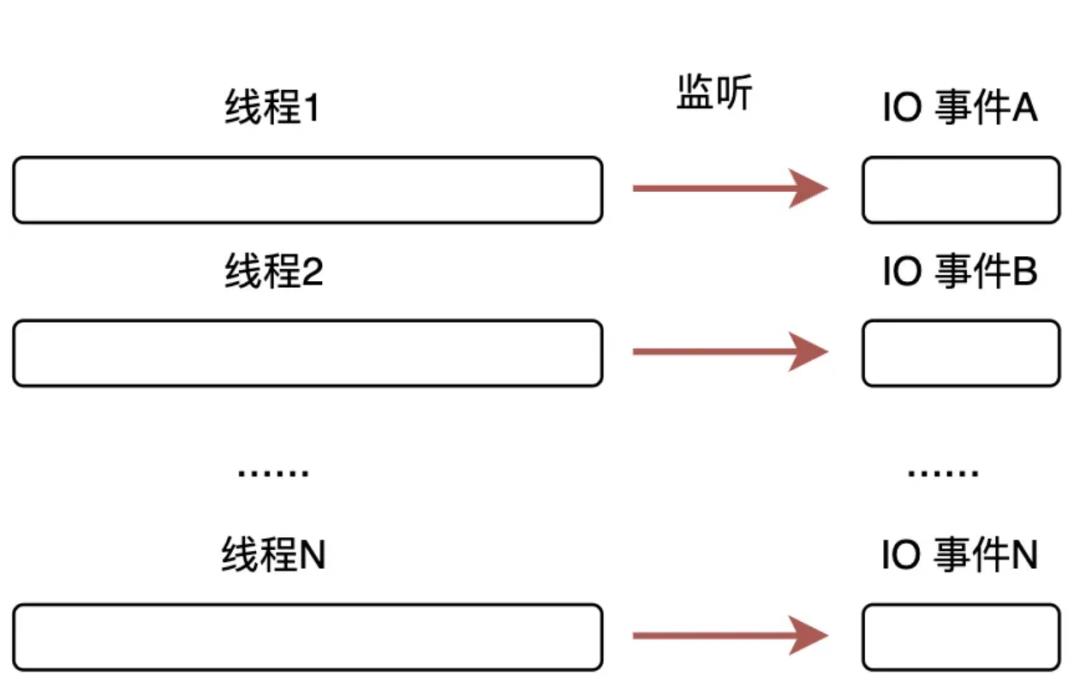
图1.1 普通多线程IO
IO多路复用的基本原理如图1.2所示。通过复用可以使一个线程处理多个IO事件。操作系统无需对额外的多个线程或者进程进行管理,节约了资源,提升了效率。
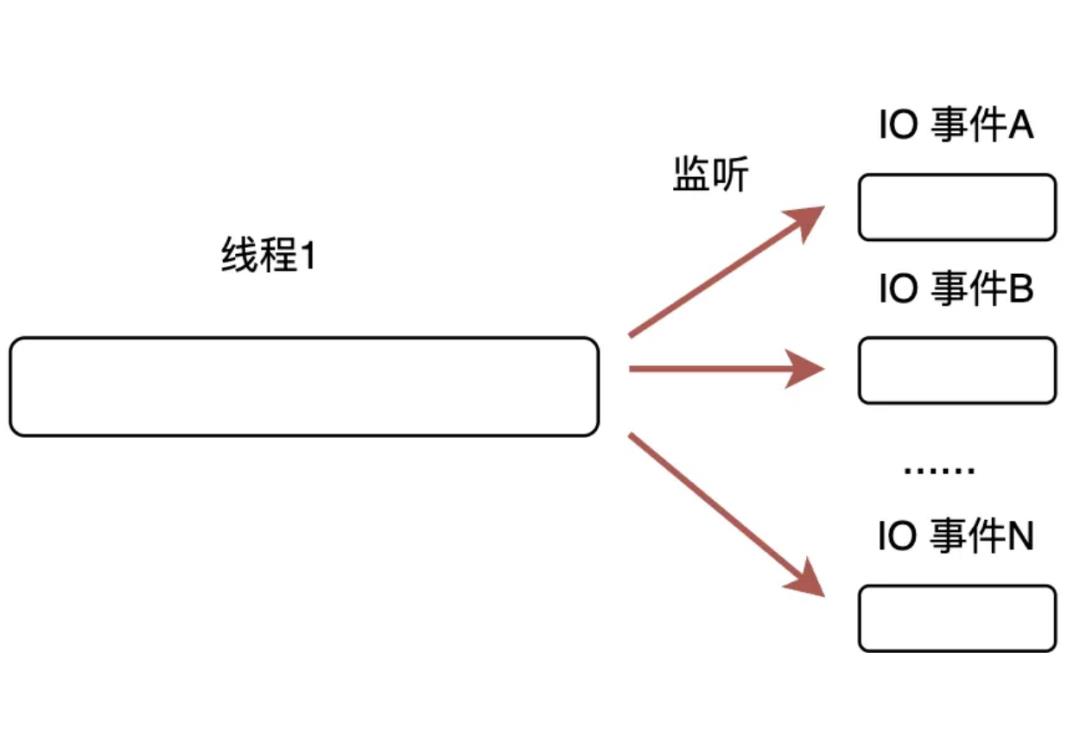
图1.2 IO多路复用
操作系统中实现IO多路复用的命令select、poll、epoll,主要通过起一个线程来监听并处理多个文件描述符代表的TCP链接,用来提高处理网络读写请求的效率。而Go语言的select命令,是用来起一个goroutine协程监听多个Channel(代表多个goroutine)的读写事件,提高从多个Channel获取信息的效率。二者具体目标和实现不同,但本质思想都是相同的。
2)select怎么用?
select基本语法
select命令的基本语法如下:
select
case <- chan1:
// 如果 chan1 成功读到数据,则进行该 case 处理语句
case chan2 <- 1:
// 如果成功向 chan2 写入数据,则进行该 case 处理语句
default:
// 如果上面都没有成功,则进入default处理流程
select的结构跟switch有些相似,不过仅仅只是形式上相似而已,本质上大为不同。select中的多个case的表达式必须都是Channel的读写操作,不能是其他的数据类型。select通过多个case监听多个Channel的读写操作,任何一个case可以执行则选择该case执行,否则执行default。如果没有default,且所有的case均不能执行,则当前的goroutine阻塞。
select没有case,永久阻塞
Go执行如下的代码:
package main
func main()
select
会发生程序因为select所在goroutine永久阻塞而失败的现象:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [select (no cases)]:
...对于空的 select 语句,程序会被阻塞,确切的说是当前协程被阻塞,同时 Go 自带死锁检测机制,当发现当前协程再也没有机会被唤醒时,则会发生 panic。所以上述程序会 panic。
select所有case均无法执行且没有default,则阻塞
Go执行如下代码:
package main
import (
"fmt"
)
func main()
ch1 := make(chan int, 1)
ch2 := make(chan int)
select
case <- ch1:
// 从有缓冲chan中读取数据,由于缓冲区没有数据且没有发送者,该分支会阻塞
fmt.Println("Received from ch")
case i := <- ch2:
// 从无缓冲chan中读取数据,由于没有发送者,该分支会阻塞
fmt.Printf("i is: %d", i)
程序会发生因所有case不满足执行条件,且没有default分支,而阻塞,由于 Go 自带死锁检测机制,当发现当前协程再也没有机会被唤醒时,则会发生 panic:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [select]:
...select有一个case和default
如果修改代码如下:
package main
import (
"fmt"
)
func main()
ch1 := make(chan int, 1)
select
case <- ch1:
// 从有缓冲chan中读取数据,由于缓冲区没有数据且没有发送者,该分支会阻塞
fmt.Println("Received from ch")
default:
fmt.Println("this is default")
select有一个case分支和default分支,当case分支不满足执行条件时执行default分支:
this is default如果有满足的分支,则执行对应的分支:
package main
import (
"fmt"
)
func main()
ch1 := make(chan int, 1)
ch1 <- 10
select
case <- ch1:
// ch1有发送者,该分支满足执行条件
fmt.Println("Received from ch1")
default:
fmt.Println("this is default")
程序运行后,输出结果如下:
Received from ch1select多个case同时可以执行,随机选择一个去执行
package main
import (
"fmt"
)
func main()
ch := make(chan int, 1)
ch <- 10
select
case val := <-ch:
fmt.Println("Received from ch1, val =", val)
case val := <-ch:
fmt.Println("Received from ch2, val =", val)
case val := <-ch:
fmt.Println("Received from ch3, val =", val)
default:
fmt.Println("Run in default")
程序运行后,输出结果如下:
Received from ch2, val = 10如果多次运行该程序,会发现,第一个case、第二个case和第三个case都会被执行。也就是说,此时所有分支条件都满足,则随机选择一个 case 执行。
 select在编译期和运行时的执行过程
select在编译期和运行时的执行过程
1)select的实现原理
select在 Go 语言的源代码中不存在对应的结构体,只是定义了一个 runtime.scase 结构体(在src/runtime/select.go)表示每个 case 语句(包含defaut):
type scase struct
c *hchan // case中使用的chan
elem unsafe.Pointer // 指向case包含数据的指针
因为所有的非 default 的 case 基本都要求是对Channel的读写操作,所以 runtime.scase 结构体中也包含一个 runtime.hchan 类型的字段存储 case 中使用的 Channel,另一个字段 elem 指向 case 条件包含的数据的指针,如 case ch1 <- 1,则 elem 指向常量1。
select语句在编译期间会被转换成 ir.OSELECT 类型的节点,见 src/cmd/compile/internal/walk/stmt.go 的 walkStmt() 函数:
func walkStmt(n ir.Node) ir.Node
......
switch n.Op()
......
case ir.OSELECT:
n := n.(*ir.SelectStmt)
walkSelect(n)
return n
......
......
处理OSELECT类型节点的函数是src/cmd/compile/internal/walk/select.go 的 walkSelect() 函数:
func walkSelect(sel *ir.SelectStmt)
lno := ir.SetPos(sel)
if sel.Walked()
base.Fatalf("double walkSelect")
sel.SetWalked(true)
init := ir.TakeInit(sel)
// 编译器在中间代码生成期间会根据select中case的不同对控制语句进行优化
init = append(init, walkSelectCases(sel.Cases)...)
sel.Cases = nil
sel.Compiled = init
walkStmtList(sel.Compiled)
base.Pos = lno
编译器在中间代码生成期间会根据 select 中 case 的不同对控制语句进行优化,这一过程都发生在 src/cmd/compile/internal/walk/select.go 的 walkSelectCases() 函数中。
func walkSelectCases(cases []*ir.CommClause) []ir.Node
ncas := len(cases)
sellineno := base.Pos
// 编译器优化: select 没有case时
if ncas == 0
return []ir.Nodemkcallstmt("block")
// 编译器优化: select只有一个case时
if ncas == 1
......
......
下面主要是分多种情况分析walkSelectCases() 函数对不同case分支条件的处理,不同的情况会调用不同的运行时函数。如图2.1所示,是编译器对不同的case情况的处理,在运行时会调用不同的函数。
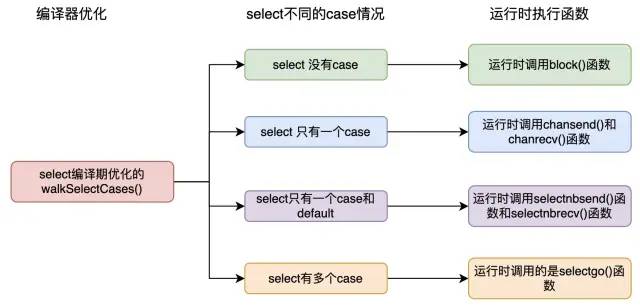
图2.1 编译器对不同的case情况在运行时调用不同的函数
2)当select没有case
从1.2.2小节的事例,我们可以知道,当select没有case时,select所在的goroutine会永久阻塞,程序会直接panic。
select
从 walkSelectCases() 函数对无case的处理逻辑,可以看到,该种情况会直接调用 runtime.block() 函数:
func walkSelectCases(cases []*ir.CommClause) []ir.Node
ncas := len(cases)
sellineno := base.Pos
// 编译器优化: select没有case时
if ncas == 0
return []ir.Nodemkcallstmt("block")
......
runtime.block() 函数会调用 gopark() 函数以waitReasonSelectNoCases的原因挂起当前协程,并且永远无法被唤醒,Go程序检测到这种情况,直接panic:
// src/runtime/select.go
func block()
gopark(nil, nil, waitReasonSelectNoCases, traceEvGoStop, 1) // forever
3)当select只有一个非default的case
select只有一个非 default 的 case 时,只有一个channel,实际会被编译器转换为对该channel的读写操作,和实际调用 data := <- ch 或 ch <- data 并没有什么区别:
ch := make(chan struct)
select
case data <- ch:
fmt.Printf("ch data: %v\\n", data)
该段代码的select语句,会被编译器转换为:
data := <- ch
fmt.Printf("ch data: %v\\n", data)读取ch成功后,才能执行该分支的语句,否则程序一直会阻塞。具体的实现原理在 walkSelectCases() 函数中:
// src/cmd/compile/internal/walk/select.go
func walkSelectCases(cases []*ir.CommClause) []ir.Node
......
// 编译器优化: select只有一个case时
if ncas == 1
cas := cases[0] // 获取第一个也是唯一的一个case
ir.SetPos(cas)
l := cas.Init()
if cas.Comm != nil // case类型不是default:
n := cas.Comm // 获取case的条件语句
l = append(l, ir.TakeInit(n)...)
switch n.Op() // 检查case对channel的操作类型:读或写
default: // 如果case既不是读,也不是写channel,则直接报错
base.Fatalf("select %v", n.Op())
case ir.OSEND:
// 如果对chan操作是写入类型,编译器无须做任何转换,直接是 chan <- data
case ir.OSELRECV2:
// 如果对chan操作是接收类型, 完整形式为:data, ok := <- chan
r := n.(*ir.AssignListStmt)
// 如果具体是<- chan这种形式,即接收字段 data和ok为空,则直接转成 <- chan
if ir.IsBlank(r.Lhs[0]) && ir.IsBlank(r.Lhs[1])
n = r.Rhs[0]
break
// 否则,是 data, ok := <- chan 这种形式
r.SetOp(ir.OAS2RECV)
// 把编译器处理后的case语句条件加入待执行语句列表
l = append(l, n)
// 把case条件后要执行的语句体加入待执行语句列表
l = append(l, cas.Body...)
// 默认加入break类型语句,跳出select-case语句体
l = append(l, ir.NewBranchStmt(base.Pos, ir.OBREAK, nil))
return l
......
从注释中可以看出,在select只有一个case并且这个case不是default时,select对case的处理就是对普通channel的读写操作。
4)当select有一个channel的case + 一个default的case
在很多讲Channel的文章中,打印下面代码的汇编,会看到select只有一个操作channel的case和一个default时,会调用编译器的runtime.selectnbrecv() 函数和runtime.selectnbsend()函数。
package main
import (
"fmt"
)
func main()
ch := make(chan int)
select
case ch <- 1:
fmt.Println("run case 1")
default:
fmt.Println("run default")
编译器会将其改写为:
if selectnbsend(ch, 1)
fmt.Println("run case 1")
else
fmt.Println("run default")
检查 walkSelectCases() 函数:
func walkSelectCases(cases []*ir.CommClause) []ir.Node
......
// 编译器优化: case 有两个case,一个是普通的channel操作,一个是default
if ncas == 2 && dflt != nil
// 获取非default的case
cas := cases[0]
if cas == dflt
cas = cases[1]
n := cas.Comm
ir.SetPos(n)
r := ir.NewIfStmt(base.Pos, nil, nil, nil)
r.SetInit(cas.Init())
var cond ir.Node
switch n.Op()
default:
base.Fatalf("select %v", n.Op())
case ir.OSEND:
// 如果该case是对channel的写入操作,则调用运行时的selectnbsend 函数
n := n.(*ir.SendStmt)
ch := n.Chan
cond = mkcall1(chanfn("selectnbsend", 2, ch.Type()), types.Types[types.TBOOL], r.PtrInit(), ch, n.Value)
case ir.OSELRECV2:
// 如果该case是对channel的读取操作,会调用运行时的selectnbrecv 函数
n := n.(*ir.AssignListStmt)
recv := n.Rhs[0].(*ir.UnaryExpr)
ch := recv.X
elem := n.Lhs[0]
if ir.IsBlank(elem)
elem = typecheck.NodNil()
cond = typecheck.Temp(types.Types[types.TBOOL])
fn := chanfn("selectnbrecv", 2, ch.Type())
call := mkcall1(fn, fn.Type().Results(), r.PtrInit(), elem, ch)
as := ir.NewAssignListStmt(r.Pos(), ir.OAS2, []ir.Nodecond, n.Lhs[1], []ir.Nodecall)
r.PtrInit().Append(typecheck.Stmt(as))
r.Cond = typecheck.Expr(cond)
r.Body = cas.Body
// 将default语句放入if语句的else分支
r.Else = append(dflt.Init(), dflt.Body...)
return []ir.Noder, ir.NewBranchStmt(base.Pos, ir.OBREAK, nil)
......
runtime.selectnbrecv() 函数和runtime.selectnbsend()函数会分别调用runtime.cahnrecv()函数和runtime.chansend()函数,我们可以看到传入这两个函数的第三个参数都是false,该参数是 block,为false代表非阻塞,即每次尝试从channel读写值,如果不成功则直接返回,不会阻塞。
func selectnbrecv(elem unsafe.Pointer, c *hchan) (selected, received bool)
return chanrecv(c, elem, false)
func selectnbsend(c *hchan, elem unsafe.Pointer) (selected bool)
return chansend(c, elem, false, getcallerpc())
5)当select有多个channel的case
如果对如下代码打印汇编,会发现执行select动作实际是调用的runtime.selectgo()函数:
package main
import (
"fmt"
)
func main()
ch1 := make(chan int)
ch2 := make(chan int)
select
case ch1 <- 1:
fmt.Println("run case 1")
case data := <- ch2:
fmt.Printf("run case 2, data is: %d", data)
继续分析walkSelectCases()函数,处理多case的代码逻辑如下:
func walkSelectCases(cases []*ir.CommClause) []ir.Node
......
// 从这里开始是多case的情况
// ncas是select的全部分支的个数,如果有default分支,ncas个数减一
if dflt != nil
ncas--
//定义casorder为ncas大小的case语句的数组
casorder := make([]*ir.CommClause, ncas)
// 分别定义nsends为发送channel的case个数,nrecvs为接收channel的case个数
nsends, nrecvs := 0, 0
// 定义init为多case编译后待执行的语句列表
var init []ir.Node
base.Pos = sellineno
// 定义selv为长度为ncas的scase类型的数组,scasetype()函数返回的就是scase结构体,包含chan和elem两个字段
selv := typecheck.Temp(types.NewArray(scasetype(), int64(ncas)))
init = append(init, typecheck.Stmt(ir.NewAssignStmt(base.Pos, selv, nil)))
// 定义order为2倍的ncas长度的TUINT16类型的数组
// 注意:selv和order作为runtime.selectgo()函数的入参,前者存放scase列表内存地址,后者用来做scase排序使用,排序是为了便于挑选出待执行的case
order := typecheck.Temp(types.NewArray(types.Types[types.TUINT16], 2*int64(ncas)))
......
// 第一个阶段:遍历case生成scase对象放到selv中
for _, cas := range cases
ir.SetPos(cas)
init = append(init, ir.TakeInit(cas)...)
n := cas.Comm
if n == nil // 如果是default分支,先跳过
continue
var i int
var c, elem ir.Node
// 根据case分别是发送或接收类型,获取chan, elem的值
switch n.Op()
default:
base.Fatalf("select %v", n.Op())
case ir.OSEND:
n := n.(*ir.SendStmt)
i = nsends // 对发送channel类型的case,i从0开始递增
nsends++
c = n.Chan
elem = n.Value
case ir.OSELRECV2:
n := n.(*ir.AssignListStmt)
nrecvs++
i = ncas - nrecvs // 对接收channel类型的case,i从ncas开始递减
recv := n.Rhs[0].(*ir.UnaryExpr)
c = recv.X
elem = n.Lhs[0]
// 编译器对多个case排列后,发送chan的case在左边,接收chan的case在右边,在selv中也是如此
casorder[i] = cas
// 定义一个函数,写入chan或elem到selv数组
setField := func(f string, val ir.Node)
r := ir.NewAssignStmt(base.Pos, ir.NewSelectorExpr(base.Pos, ir.ODOT, ir.NewIndexExpr(base.Pos, selv, ir.NewInt(int64(i))), typecheck.Lookup(f)), val)
init = append(init, typecheck.Stmt(r))
// 将c代表的chan写入selv
c = typecheck.ConvNop(c, types.Types[types.TUNSAFEPTR])
setField("c", c)
// 将elem写入selv
if !ir.IsBlank(elem)
elem = typecheck.ConvNop(elem, types.Types[types.TUNSAFEPTR])
setField("elem", elem)
......
// 如果发送chan和接收chan的个数不等于ncas,说明代码有错误,直接报错
if nsends+nrecvs != ncas
base.Fatalf("walkSelectCases: miscount: %v + %v != %v", nsends, nrecvs, ncas)
// 从这里开始执行select动作
base.Pos = sellineno
// 定义chosen, recvOK作为selectgo()函数的两个返回值,chosen 表示被选中的case的索引,recvOK表示对于接收操作,是否成功接收
chosen := typecheck.Temp(types.Types[types.TINT])
recvOK := typecheck.Temp(types.Types[types.TBOOL])
r := ir.NewAssignListStmt(base.Pos, ir.OAS2, nil, nil)
r.Lhs = []ir.Nodechosen, recvOK
// 调用runtime.selectgo()函数作为运行时实际执行多case的select动作的函数
fn := typecheck.LookupRuntime("selectgo")
var fnInit ir.Nodes
r.Rhs = []ir.Nodemkcall1(fn, fn.Type().Results(), &fnInit, bytePtrToIndex(selv, 0), bytePtrToIndex(order, 0), pc0, ir.NewInt(int64(nsends)), ir.NewInt(int64(nrecvs)), ir.NewBool(dflt == nil))
init = append(init, fnInit...)
init = append(init, typecheck.Stmt(r))
// 执行完selectgo()函数后,销毁selv和order数组.
init = append(init, ir.NewUnaryExpr(base.Pos, ir.OVARKILL, selv))
init = append(init, ir.NewUnaryExpr(base.Pos, ir.OVARKILL, order))
......
// 定义一个函数,根据chosen确定的case分支生成if语句,执行该分支的语句
dispatch := func(cond ir.Node, cas *ir.CommClause)
cond = typecheck.Expr(cond)
cond = typecheck.DefaultLit(cond, nil)
r := ir.NewIfStmt(base.Pos, cond, nil, nil)
if n := cas.Comm; n != nil && n.Op() == ir.OSELRECV2
n := n.(*ir.AssignListStmt)
if !ir.IsBlank(n.Lhs[1])
x := ir.NewAssignStmt(base.Pos, n.Lhs[1], recvOK)
r.Body.Append(typecheck.Stmt(x))
r.Body.Append(cas.Body.Take()...)
r.Body.Append(ir.NewBranchStmt(base.Pos, ir.OBREAK, nil))
init = append(init, r)
// 如果多case中有default分支,并且chosen小于0,执行该default分支
if dflt != nil
ir.SetPos(dflt)
dispatch(ir.NewBinaryExpr(base.Pos, ir.OLT, chosen, ir.NewInt(0)), dflt)
// 如果有chosen选中的case分支,即chosen等于i,则执行该分支
for i, cas := range casorder
ir.SetPos(cas)
dispatch(ir.NewBinaryExpr(base.Pos, ir.OEQ, chosen, ir.NewInt(int64(i))), cas)
return init
从对多case的编译器处理逻辑,可以看到分为三个阶段:
第一阶段,生成scase对象数组,定义selv和order数组,selv存放scase数组内存地址,order用来做scase排序使用,对scase数组排序是为了以某种机制选出待执行的case;
第二阶段,编译器生成调用 runtime.selectgo() 的逻辑,selv和order数组作为入参传入selectgo() 函数,同时定义该函数的返回值,chosen 和 recvOK,chosen 表示被选中的case的索引,recvOK表示对于接收操作,是否成功接收;
第三阶段,根据 selectgo 返回值 chosen 来生成 if 语句来执行相应索引的 case。
6)select在多case下调用的运行时selectgo函数怎样实现多channel的选择?
下面开始分析runtime.selectgo()函数的主要逻辑,逻辑流程图如图所示。
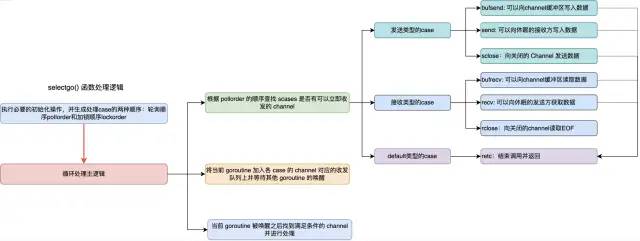
selectgo函数处理主逻辑
selectgo函数首先会执行必要的初始化操作,并生成处理case的两种顺序:轮询顺序polIorder和加锁顺序lockorder。
// cas0 指向一个类型为 [ncases]scase 的数组
// order0 是一个指向[2*ncases]uint16,数组中的值都是 0
// 返回值有两个, chosen 和 recvOK,分别表示选中的case的序号,和对接收操作是否接收成功的布尔值
func selectgo(cas0 *scase, order0 *uint16, pc0 *uintptr, nsends, nrecvs int, block bool) (int, bool)
......
// 为了将scase分配到栈上,这里直接给cas1分配了64KB大小的数组,同理, 给order1分配了128KB大小的数组
cas1 := (*[1 << 16]scase)(unsafe.Pointer(cas0))
order1 := (*[1 << 17]uint16)(unsafe.Pointer(order0))
// ncases个数是发送chan个数nsends加上接收chan个数nrecvs
ncases := nsends + nrecvs
// scases切片是上面分配cas1数组的前ncases个元素
scases := cas1[:ncases:ncases]
// 顺序列表pollorder是order1数组的前ncases个元素
pollorder := order1[:ncases:ncases]
// 加锁列表lockorder是order1数组的第二批ncase个元素
lockorder := order1[ncases:][:ncases:ncases]
......
// 生成排列顺序
norder := 0
for i := range scases
cas := &scases[i]
// 处理case中channel为空的情况
if cas.c == nil
cas.elem = nil // 将elem置空,便于GC
continue
// 通过fastrandn函数引入随机性,确定pollorder列表中case的随机顺序索引
j := fastrandn(uint32(norder + 1))
pollorder[norder] = pollorder[j]
pollorder[j] = uint16(i)
norder++
pollorder = pollorder[:norder]
lockorder = lockorder[:norder]
// 根据chan地址确定lockorder加锁排序列表的顺序
// 通过简单的堆排序,以nlogn时间复杂度完成排序
for i := range lockorder
j := i
// Start with the pollorder to permute cases on the same channel.
c := scases[pollorder[i]].c
for j > 0 && scases[lockorder[(j-1)/2]].c.sortkey() < c.sortkey()
k := (j - 1) / 2
lockorder[j] = lockorder[k]
j = k
lockorder[j] = pollorder[i]
for i := len(lockorder) - 1; i >= 0; i--
o := lockorder[i]
c := scases[o].c
lockorder[i] = lockorder[0]
j := 0
for
k := j*2 + 1
if k >= i
break
if k+1 < i && scases[lockorder[k]].c.sortkey() < scases[lockorder[k+1]].c.sortkey()
k++
if c.sortkey() < scases[lockorder[k]].c.sortkey()
lockorder[j] = lockorder[k]
j = k
continue
break
lockorder[j] = o
......
轮询顺序 pollorder 是通过runtime.fastrandn 函数引入随机性;随机的轮询顺序可以避免 channel 的饥饿问题,保证公平性。加锁顺序 lockorder是按照 channel 的地址排序后确定的加锁顺序,这样能够避免死锁的发生。
加锁和解锁调用的是runtime.sellock()函数和runtime.selunlock()函数。从下面的代码逻辑中可以看到,两个函数分别是按lockorder顺序对channel加锁,以及按lockorder逆序释放锁。
func sellock(scases []scase, lockorder []uint16)
var c *hchan
for _, o := range lockorder
c0 := scases[o].c
if c0 != c
c = c0
lock(&c.lock)
func selunlock(scases []scase, lockorder []uint16)
for i := len(lockorder) - 1; i >= 0; i--
c := scases[lockorder[i]].c
if i > 0 && c == scases[lockorder[i-1]].c
continue
unlock(&c.lock)
接下来,是selectgo()函数的主处理逻辑,它会分三个阶段查找或等待某个channel准备就绪:首先,根据 pollorder 的顺序查找 scases 是否有可以立即收发的 channel;其次,将当前 goroutine 加入各 case 的 channel 对应的收发队列上并等待其他 goroutine 的唤醒;最后,当前 goroutine 被唤醒之后找到满足条件的 channel 并进行处理;
需要说明的是,runtime.selectgo 函数会根据不同情况通过 goto 语句跳转到函数内部的不同标签执行相应的逻辑。其中包括:bufrecv:可以从channel缓冲区读取数据;bufsend:可以向channel缓冲区写入数据;recv:可以从休眠的发送方获取数据;send:可以向休眠的接收方发送数据;rclose:可以从关闭的 channel 读取 EOF;sclose:向关闭的 channel 发送数据;retc:结束调用并返回;
先看主处理逻辑的第一个阶段,根据 pollorder 的顺序查找 scases 是否有可以立即收发的 channel:
func selectgo(cas0 *scase, order0 *uint16, pc0 *uintptr, nsends, nrecvs int, block bool) (int, bool)
......
sellock(scases, lockorder)
......
// 阶段一: 查找可以处理的channel
var casi int
var cas *scase
var caseSuccess bool
var caseReleaseTime int64 = -1
var recvOK bool
for _, casei := range pollorder
casi = int(casei) // case的索引
cas = &scases[casi] // 当前的case
c = cas.c
if casi >= nsends // 处理接收channel的case
sg = c.sendq.dequeue()
if sg != nil // 如果当前channel的sendq上有等待的goroutine,就会跳到 recv标签并从缓冲区读取数据后将等待goroutine中的数据放入到缓冲区中相同的位置;
goto recv
if c.qcount > 0 //如果当前channel的缓冲区不为空,就会跳到bufrecv标签处从缓冲区获取数据;
goto bufrecv
if c.closed != 0 //如果当前channel已经被关闭,就会跳到rclose做一些清除的收尾工作;
goto rclose
else // 处理发送channel的case
......
if c.closed != 0 // 如果当前channel已经被关闭就会直接跳到sclose标签,触发 panic 尝试中止程序;
goto sclose
sg = c.recvq.dequeue()
if sg != nil // 如果当前channel的recvq上有等待的goroutine,就会跳到 send标签向channel发送数据;
goto send
if c.qcount < c.dataqsiz // 如果当前channel的缓冲区存在空闲位置,就会将待发送的数据存入缓冲区;
goto bufsend
if !block // 如果是非阻塞,即包含default分支,会解锁所有 Channel 并返回
selunlock(scases, lockorder)
casi = -1
goto retc
......
主要处理逻辑是:
当 case 会从 channel 中接收数据时,如果当前 channel 的 sendq 上有等待的 goroutine,就会跳到 recv 标签并从缓冲区读取数据后将等待 goroutine 中的数据放入到缓冲区中相同的位置;如果当前 channel 的缓冲区不为空,就会跳到 bufrecv 标签处从缓冲区获取数据;如果当前 channel 已经被关闭,就会跳到 rclose 做一些清除的收尾工作。
当 case 会向 channel 发送数据时,如果当前 channel 已经被关闭,就会直接跳到 sclose 标签,触发 panic 尝试中止程序;如果当前 channel 的 recvq 上有等待的 goroutine,就会跳到 send 标签向 channel 发送数据;如果当前 channel 的缓冲区存在空闲位置,就会将待发送的数据存入缓冲区。
当 select 语句中包含 default 即 block为 false 时;表示前面的所有 case 都没有被执行,这里会解锁所有 channel 并返回,意味着当前 select 结构中的收发都是非阻塞的。
如果没有可以立即处理的 channel,则进入主逻辑的下一个阶段,根据需要将当前 goroutine 加入 channel 对应的收发队列上并等待其他 goroutine 的唤醒。
func selectgo(cas0 *scase, order0 *uint16, pc0 *uintptr, nsends, nrecvs int, block bool) (int, bool)
......
// 阶段2: 将当前goroutine根据需要挂在chan的sendq和recvq上
gp = getg()
if gp.waiting != nil
throw("gp.waiting != nil")
nextp = &gp.waiting
for _, casei := range lockorder
casi = int(casei)
cas = &scases[casi]
c = cas.c
// 获取sudog,将当前goroutine绑定到sudog上
sg := acquireSudog()
sg.g = gp
sg.isSelect = true
sg.elem = cas.elem
sg.releasetime = 0
if t0 != 0
sg.releasetime = -1
sg.c = c
*nextp = sg
nextp = &sg.waitlink
// 加入相应等待队列
if casi < nsends
c.sendq.enqueue(sg)
else
c.recvq.enqueue(sg)
......
// 被唤醒后会根据 param 来判断是否是由 close 操作唤醒的,所以先置为 nil
gp.param = nil
......
// 挂起当前goroutine
gopark(selparkcommit, nil, waitReasonSelect, traceEvGoBlockSelect, 1)
......
等到 select 中的一些 channel 准备就绪之后,当前 goroutine 就会被调度器唤醒。这时会继续执行 runtime.selectgo 函数的第三部分:
func selectgo(cas0 *scase, order0 *uint16, pc0 *uintptr, nsends, nrecvs int, block bool) (int, bool)
......
// 加锁所有的channel
sellock(scases, lockorder)
gp.selectDone = 0
// param 存放唤醒 goroutine 的 sudog,如果是关闭操作唤醒的,那么就为 nil
sg = (*sudog)(gp.param)
gp.param = nil
casi = -1
cas = nil
caseSuccess = false
// 当前goroutine 的 waiting 链表按照lockorder顺序存放着case的sudog
sglist = gp.waiting
// 在从 gp.waiting 取消case的sudog链接之前清除所有元素,便于GC
for sg1 := gp.waiting; sg1 != nil; sg1 = sg1.waitlink
sg1.isSelect = false
sg1.elem = nil
sg1.c = nil
// 清楚当前goroutine的waiting链表,因为被sg代表的协程唤醒了
gp.waiting = nil
for _, casei := range lockorder
k = &scases[casei]
// 如果相等说明,goroutine是被当前case的channel收发操作唤醒的
if sg == sglist
// sg唤醒了当前goroutine, 则当前G已经从sg的队列中出队,这里不需要再次出队
casi = int(casei)
cas = k
caseSuccess = sglist.success
if sglist.releasetime > 0
caseReleaseTime = sglist.releasetime
else
// 不是此case唤醒当前goroutine, 将goroutine从此case的发送队列或接收队列出队
c = k.c
if int(casei) < nsends
c.sendq.dequeueSudoG(sglist)
else
c.recvq.dequeueSudoG(sglist)
// 释放当前case的sudog,然后处理下一个case的sudog
sgnext = sglist.waitlink
sglist.waitlink = nil
releaseSudog(sglist)
sglist = sgnext
......
这里主要是:首先,先释放当前goroutine的等待队列,因为已经被某个case的sudog唤醒了;其次,遍历全部的case的sudog,找到唤醒当前goroutine的case的索引并返回,后面会根据它做channel的收发操作;最后,剩下的不是唤醒当前goroutine的case,需要将当前goroutine从这些case的发送队列或接收队列出队,并释放这些case的sudog;
selectgo() 函数的最后一些代码,是循环第一阶段用到的跳转标签代码段;
bufsend 和 bufrecv 两个代码段,这两段代码的执行过程都很简单,它们是向 channel 的缓冲区中发送数据或者从缓冲区中获取数据;
两个直接收发 channel 的情况recv、send,会调用运行时函数 runtime.send 和 runtime.recv,这两个函数会与处于休眠状态的 goroutine 打交道;
向关闭的 channel 发送数据或者从关闭的 channel 中接收数据分别是 sclose 和 rclose阶段;sclose,向一个关闭的 channel 发送数据就会直接 panic 造成程序崩溃;rclose,从一个关闭 channel 中接收数据会直接清除 Channel 中的相关内容;retc阶段,退出程序。
bufrecv:
......
recvOK = true
qp = chanbuf(c, c.recvx)
if cas.elem != nil
typedmemmove(c.elemtype, cas.elem, qp)
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz
c.recvx = 0
c.qcount--
selunlock(scases, lockorder)
goto retc
bufsend:
......
typedmemmove(c.elemtype, chanbuf(c, c.sendx), cas.elem)
c.sendx++
if c.sendx == c.dataqsiz
c.sendx = 0
c.qcount++
selunlock(scases, lockorder)
goto retc
recv:
// 可以直接从休眠的goroutine获取数据
recv(c, sg, cas.elem, func() selunlock(scases, lockorder) , 2)
......
recvOK = true
goto retc
rclose:
//从一个关闭 channel 中接收数据会直接清除 Channel 中的相关内容;
selunlock(scases, lockorder)
recvOK = false
if cas.elem != nil
typedmemclr(c.elemtype, cas.elem)
......
goto retc
send:
......
// 可以直接从休眠的goroutine获取数据
send(c, sg, cas.elem, func() selunlock(scases, lockorder) , 2)
if debugSelect
print("syncsend: cas0=", cas0, " c=", c, "\\n")
goto retc
retc:
// 退出selectgo()函数
if caseReleaseTime > 0
blockevent(caseReleaseTime-t0, 1)
return casi, recvOK
sclose:
// 向一个关闭的 channel 发送数据就会直接 panic 造成程序崩溃;
selunlock(scases, lockorder)
panic(plainError("send on closed channel")) 总结
总结
综合上面的分析,总结如下:
编译器会对select有不同的case的情况进行优化以提高性能。首先,编译器对select没有case、有单case和单case+default的情况进行单独处理,这些处理或者直接调用运行时函数,或者直接转成对channel的操作,或者以非阻塞的方式访问channel,多种灵活的处理方式能够提高性能,尤其是避免对channel的加锁。
对最常出现的select有多case的情况,会调用runtime.selectgo()函数来获取执行case的索引,并生成 if 语句执行该case的代码。
selectgo函数的执行分为四个步骤:首先,随机生成一个遍历case的轮询顺序 pollorder 并根据 channel 地址生成加锁顺序 lockorder,随机顺序能够避免channel饥饿,保证公平性,加锁顺序能够避免死锁和重复加锁;然后,根据 pollorder 的顺序查找 scases 是否有可以立即收发的channel,如果有则获取case索引进行处理;再次,如果pollorder顺序上没有可以直接处理的case,则将当前 goroutine 加入各 case 的 channel 对应的收发队列上并等待其他 goroutine 的唤醒;最后,当调度器唤醒当前 goroutine 时,会再次按照 lockorder 遍历所有的case,从中查找需要被处理的case索引进行读写处理,同时从所有case的发送接收队列中移除掉当前goroutine。
你可能感兴趣的腾讯工程师作品


后台回复“GO资料”,领本文作者推荐的更多资料

🔹关注我并点亮星标🔹
工作日晚8点 看腾讯技术、学专家经验

以上是关于最全Go select底层原理,一文学透高频用法的主要内容,如果未能解决你的问题,请参考以下文章