Spark SQL执行计划到RDD全流程记录
Posted lilyjoke
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark SQL执行计划到RDD全流程记录相关的知识,希望对你有一定的参考价值。
目录
记录Spark SQL生成执行计划的全流程和代码跟踪。Spark版本是2.3.2。
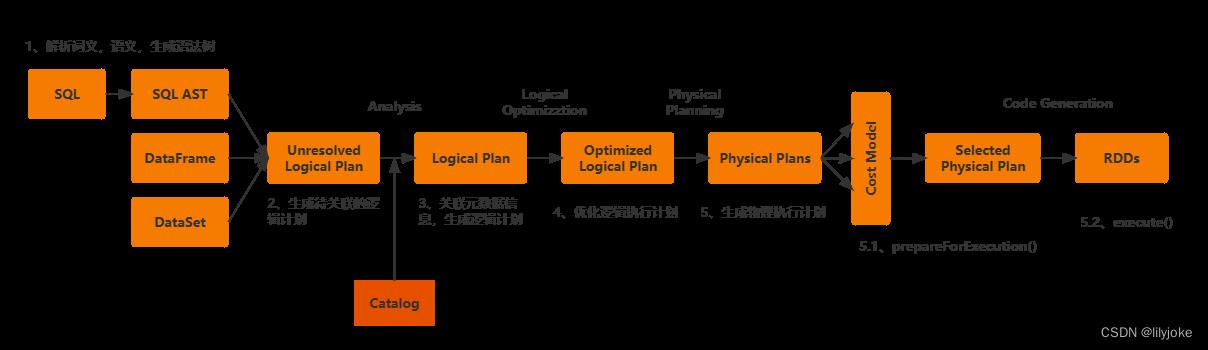
上图流程描述了Spark SQL 怎么转成Spark计算框架可以执行的分布式模型,下面结合一个样例,跟踪每个步骤。
0、样例说明
SQL样例:
select
t1.*,
t2.id
from
test.tb_hive_test t1
join
test.test t2
on
t1.a == t2.name and imp_date == '20221216'test.tb_hive_test是分区表,test.test是非分区表,两张表的建表语句:
CREATE TABLE test.tb_hive_test(
a string,
b string
)
PARTITIONED BY (imp_date string COMMENT '分区时间')
Stored as ORC
CREATE TABLE test.test(
id int,
name string,
create_time timestamp
)
Stored as ORC1、解析词义,语义,生成语法树
1.1、概念
SparK基于ANTLR语法解析SQL,ANTLR是可以根据输入自动生成语法树并可视化的显示出来的开源语法分析器。 ANTLR 主要包含词法分析器,语法分析器和树分析器。
- 词法分析器又称 Scanner、Lexer 或 Tokenizer。词法分析器的工作是分析量化那些本来毫无意义的字符流, 抽取出一些单词,例如关键字(例如SELECT)、标识符(例如STRING)、符号(例如=)和操作符(例如UNION) 供语法分析器使用。
- 语法分析器又称编译器。在分析字符流的时候,词法分析器只关注单个词语,不关注上下文。语法分析器则将收到的 Token 组织起来,并转换成为目标语言语法定义所允许的序列。
- 树分析器可以用于对语法分析生成的抽象语法树进行遍历,并能执行一些相关的操作。
1.2、Spark源码分析
当提交上述SQL是,会调用该方法:
package org.apache.spark.sql
class SparkSession private(...)
//sqlText为输入的SQL
def sql(sqlText: String): DataFrame =
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
sessionState.sqlParser的parsePlan方法在AbstractSqlParser进行具体实现:
package org.apache.spark.sql.catalyst.parser
abstract class AbstractSqlParser extends ParserInterface with Logging
//1、parsePlan函数具体实现
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) parser =>
astBuilder.visitSingleStatement(parser.singleStatement()) match
case plan: LogicalPlan => plan
case _ =>
val position = Origin(None, None)
throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position)
//2、调用parse方法
protected def parse[T](command: String)(toResult: SqlBaseParser => T): T =
logDebug(s"Parsing command: $command")
//词法分析器
val lexer = new SqlBaseLexer(new UpperCaseCharStream(CharStreams.fromString(command)))
lexer.removeErrorListeners()
lexer.addErrorListener(ParseErrorListener)
val tokenStream = new CommonTokenStream(lexer)
val parser = new SqlBaseParser(tokenStream) //语法分析器
parser.addParseListener(PostProcessor)
parser.removeErrorListeners()
parser.addErrorListener(ParseErrorListener)
...
debug可以看到,执行到这里,sql被拆解成了很多类型的**Context
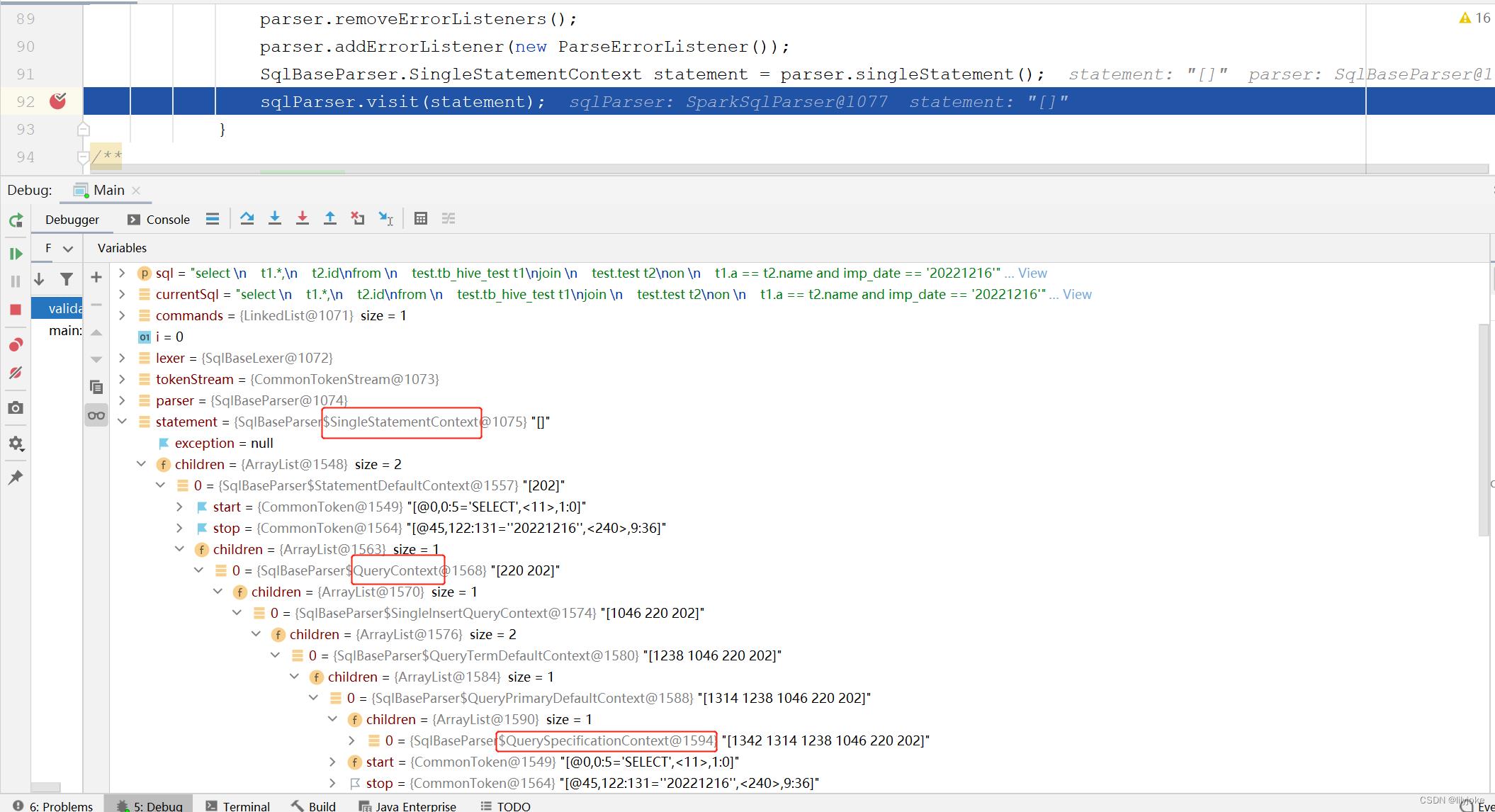
这些Context类都是根据ANTLR语法去解析SqlBase.g4这个DSL脚本,然后生成的,比如下面这个querySpecification就会生成QuerySpecificationContext类,里面就能通过各类参数记录下Select开头的某类SQL的词义和值。
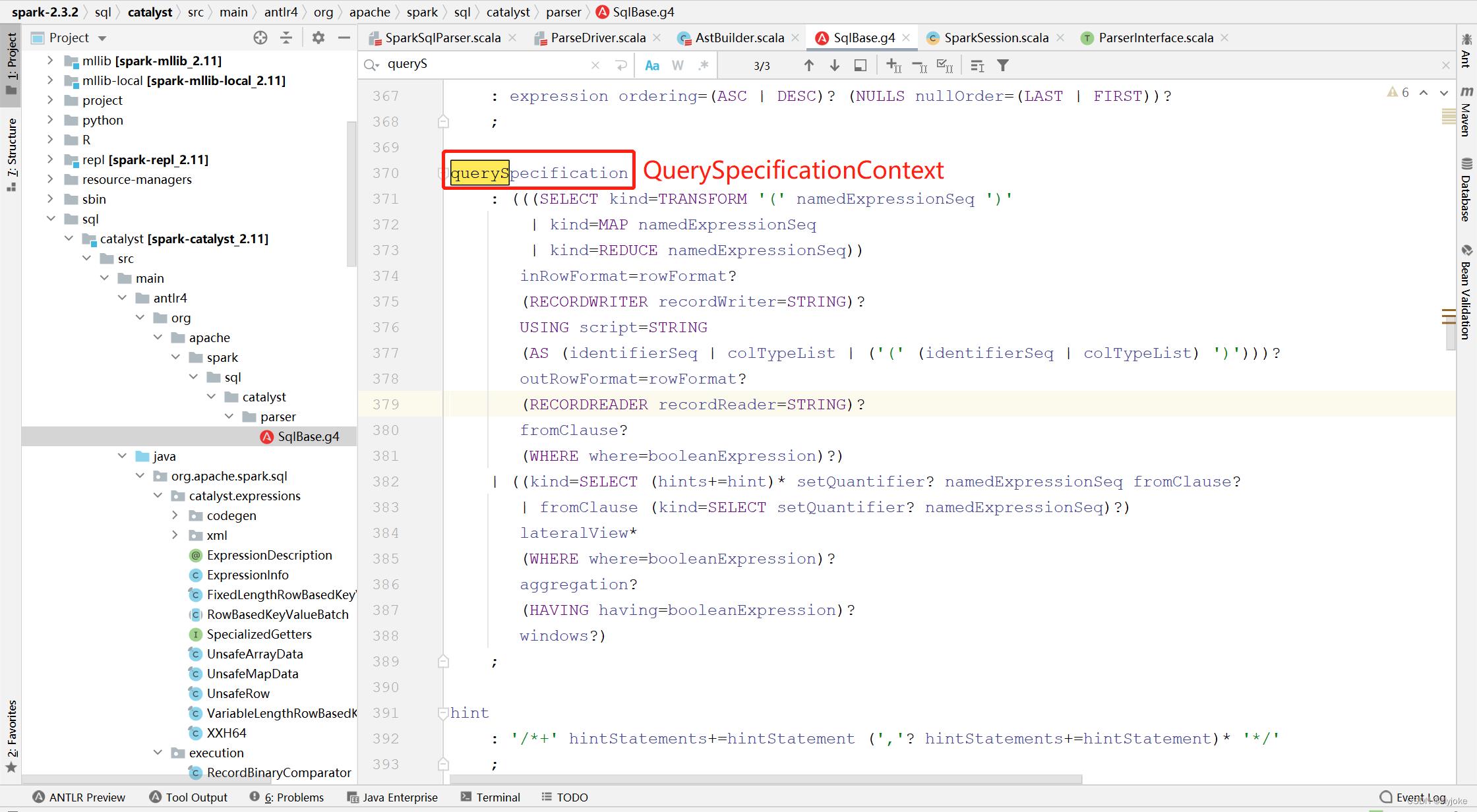
把SQL解析成AST语法树之后,就可以开始构建逻辑执行计划。
2、Unresolved Logical Plan
回到上面得parsePlan函数,第一步生成语法树之后,第二步是使用 AstBuilder (树遍历)将语法
树转换成 LogicalPlan。这个 LogicalPlan 也被称为 Unresolved LogicalPlan。
package org.apache.spark.sql.catalyst.parser
abstract class AbstractSqlParser extends ParserInterface with Logging
//1、parsePlan具体实现
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) parser =>
//2、astBuilder遍历语法树,获得Unresolved LoginPlan
astBuilder.visitSingleStatement(parser.singleStatement()) match
case plan: LogicalPlan => plan
case _ =>
val position = Origin(None, None)
throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position)
从代码上看,第二步执行完成后,应该得到的是如下的执行计划,所有的表和字段,都没有关联到实际的表和元数据,只是简单的做一步SQL的解析,生成语法树。
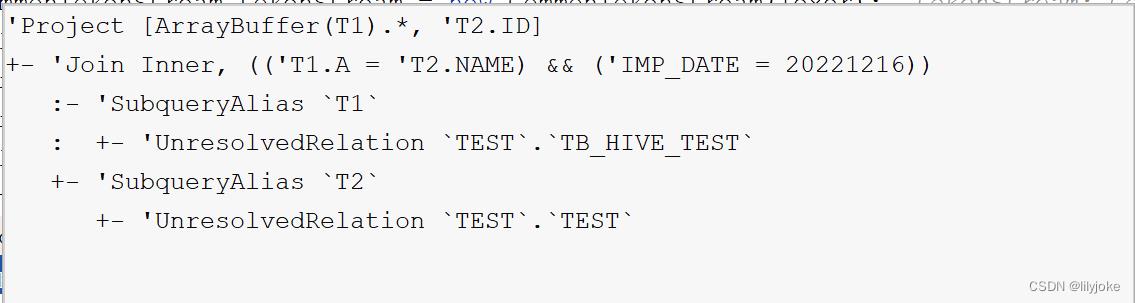
但是从Spark history看,logical plan如下,两张表已经关联到了对应的hive表,并拿到了实际表字段,为什么?
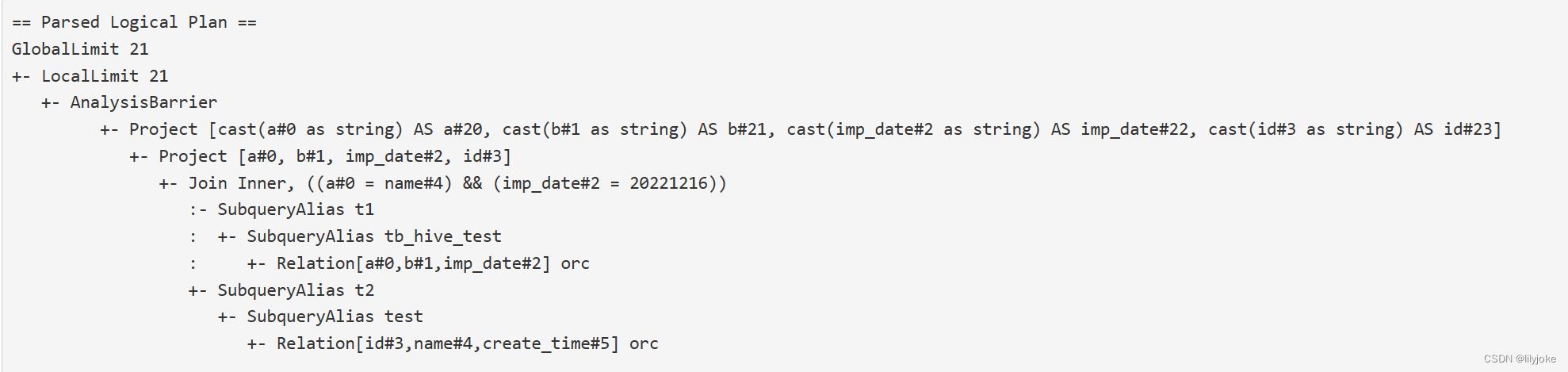
QueryExecution
因为上面打印的Parsed Logical Plan是在QueryExecution中打印的,可以看到QueryExecution打印这个执行计划过程中有四个变量:logical,analyzedPlan,optimizedPlan,executedPlan,分别就是从QueryExecution这个层面划分的《未关联的逻辑执行计划》,《关联元数据的逻辑执行计划》,《优化后的逻辑执行计划》和《物理执行计划》。
package org.apache.spark.sql.execution
class QueryExecution(val sparkSession: SparkSession, val logical: LogicalPlan)
override def toString: String = withRedaction
def output = Utils.truncatedString(
analyzed.output.map(o => s"$o.name: $o.dataType.simpleString"), ", ")
val analyzedPlan = Seq(
stringOrError(output),
stringOrError(analyzed.treeString(verbose = true))
).filter(_.nonEmpty).mkString("\\n")
s"""== Parsed Logical Plan ==
|$stringOrError(logical.treeString(verbose = true))
== Analyzed Logical Plan ==
|$analyzedPlan
== Optimized Logical Plan ==
|$stringOrError(optimizedPlan.treeString(verbose = true))
|== Physical Plan ==
|$stringOrError(executedPlan.treeString(verbose = true))
""".stripMargin.trim
那QueryExecution对象怎么生成的,又回到最初的起点:
package org.apache.spark.sql
class SparkSession private(...)
//sqlText为输入的SQL
def sql(sqlText: String): DataFrame =
Dataset.ofRows(
self,
//1、得到Unresolved Logical Plan
sessionState.sqlParser.parsePlan(sqlText)
)
private[sql] object Dataset
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame =
//2、在这里构造一个QueryExecution,logicalPlan入参就是上面获得的Unresolved Logical Plan
val qe = sparkSession.sessionState.executePlan(logicalPlan)
qe.assertAnalyzed()
new Dataset[Row](sparkSession, qe, RowEncoder(qe.analyzed.schema))
package org.apache.spark.sql.internal
private[sql] class SessionState(...)
def executePlan(plan: LogicalPlan): QueryExecution = createQueryExecution(plan)
3、Analyzed Logical Plan
源码
Unresolved LogicalPlan 通过绑定catalog元数据,得到Analyzed Logical Plan。这一步骤主要通过Analyzer来实现。先通过源码跟踪,回到第一步:
package org.apache.spark.sql
class SparkSession private(...)
//sqlText为输入的SQL
def sql(sqlText: String): DataFrame =
Dataset.ofRows(
self,
//1、得到Unresolved Logical Plan
sessionState.sqlParser.parsePlan(sqlText)
)
private[sql] object Dataset
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame =
//2、构造一个QueryExecution
val qe = sparkSession.sessionState.executePlan(logicalPlan)
qe.assertAnalyzed() //3、analyze,即将未关联的logicalPlan转成关联的logicalPlan
new Dataset[Row](sparkSession, qe, RowEncoder(qe.analyzed.schema))
package org.apache.spark.sql.execution
class QueryExecution(val sparkSession: SparkSession, val logical: LogicalPlan)
def assertAnalyzed(): Unit = analyzed
lazy val analyzed: LogicalPlan =
SparkSession.setActiveSession(sparkSession)
//3.1、调用Analyzer对象方法,对逻辑计划进行关联分析,得到分析后的逻辑计划
sparkSession.sessionState.analyzer.executeAndCheck(logical)
private[sql] class SessionState(
sharedState: SharedState,
val conf: SQLConf,
val experimentalMethods: ExperimentalMethods,
val functionRegistry: FunctionRegistry,
val udfRegistration: UDFRegistration,
catalogBuilder: () => SessionCatalog,
val sqlParser: ParserInterface,
analyzerBuilder: () => Analyzer,
optimizerBuilder: () => Optimizer,
val planner: SparkPlanner,
val streamingQueryManager: StreamingQueryManager,
val listenerManager: ExecutionListenerManager,
resourceLoaderBuilder: () => SessionResourceLoader,
createQueryExecution: LogicalPlan => QueryExecution,
createClone: (SparkSession, SessionState) => SessionState)
然后看下Analyzer源码,构造Analyzer对象的第一个入参是SessionCatalog。
package org.apache.spark.sql.catalyst.analysis
class Analyzer(
catalog: SessionCatalog,
conf: SQLConf,
maxIterations: Int)
extends RuleExecutor[LogicalPlan] with CheckAnalysis
...
SessionCatalog
在 Spark 2.x 中,Spark SQL中的 Catalog 体系实现以 SessionCatalog 为主体,SessionCatalog起到了一个代理的作用,对底层的元数据信息、临时表信息、视图信息和函数信息进行了封装,用来管理数据库(Databases)、数据表(Tables)、数据分区(Partitions)和函数(Functions)的一些功能接口,例如表是否存在,Drop表,修改表等等。
SessionCatalog 的ExternalCatalog变量分为两类:ExternalCatalog和InMemoryCatalog,ExternalCatalog利用Hive原数据库来实现持久化的管理,在生产环境中广泛应用,InMemoryCatalog将信息存储在内存中,一般用于测试或比较简单的SQL处理;
package org.apache.spark.sql.catalyst.catalog
class SessionCatalog(
//有InMemoryCatalog和HiveExternalCatalog两种实现类
val externalCatalog: ExternalCatalog,
globalTempViewManager: GlobalTempViewManager,
functionRegistry: FunctionRegistry,
conf: SQLConf,
hadoopConf: Configuration,
parser: ParserInterface,
functionResourceLoader: FunctionResourceLoader) extends Logging
...
Analyzer Rule Batch
回到Analyzer的executeAndCheck方法,如上述代码所示。对逻辑执行计划进行优化的逻辑主要是:
1、使用事先定义好的优化规则 以及 SessionCatalog 对 Unresolved LogicalPlan 进行转换操作;
2、事先定义好的优化规则主要是由 Rule 组成一个 Batch,一共有多个Batch规则。例如下面的Resolution Batch,RuleExecutor 执行时,是先按Batch顺序,串行执行第一个Batch的Rule列表,再执行第二个Batch的Rule列表。
package org.apache.spark.sql.catalyst.analysis
class Analyzer(
catalog: SessionCatalog,
conf: SQLConf,
maxIterations: Int)
//0、Analyzer继承RuleExecutor,具体的转换是在RuleExecutor实现
extends RuleExecutor[LogicalPlan] with CheckAnalysis
//1、analyzer调用入口参数
def executeAndCheck(plan: LogicalPlan): LogicalPlan =
val analyzed = execute(plan) //2、最终跳转到RuleExecutor中的execute
try
checkAnalysis(analyzed)
EliminateBarriers(analyzed)
catch
case e: AnalysisException =>
val ae = new AnalysisException(e.message, e.line, e.startPosition, Option(analyzed))
ae.setStackTrace(e.getStackTrace)
throw ae
package org.apache.spark.sql.catalyst.rules
abstract class RuleExecutor[TreeType <: TreeNode[_]] extends Logging
def execute(plan: TreeType): TreeType =
var curPlan = plan
val queryExecutionMetrics = RuleExecutor.queryExecutionMeter
//3、对预定义好的rule进行遍历
//根据rule将UnresolvedLogicalPlan转换成RelateLogicalPlan
batches.foreach batch =>
val batchStartPlan = curPlan
var iteration = 1
var lastPlan = curPlan
var continue = true
// Run until fix point (or the max number of iterations as specified in the strategy.
while (continue)
curPlan = batch.rules.foldLeft(curPlan) //4、这里是关键实现
case (plan, rule) =>
val startTime = System.nanoTime()
val result = rule(plan) //4.1、每个rule都在上一次运行得到得plan基础上进行转换
...
//5、rule在Analyser已经预定义好
package org.apache.spark.sql.catalyst.analysis
class Analyzer...
lazy val batches: Seq[Batch] = Seq(
...
Batch("Resolution", fixedPoint,
ResolveTableValuedFunctions :: //解析表的函数
ResolveRelations :: //解析表或者视图的函数
ResolveReferences :: //解析列的函数
...
)
foldLeft和foldRight
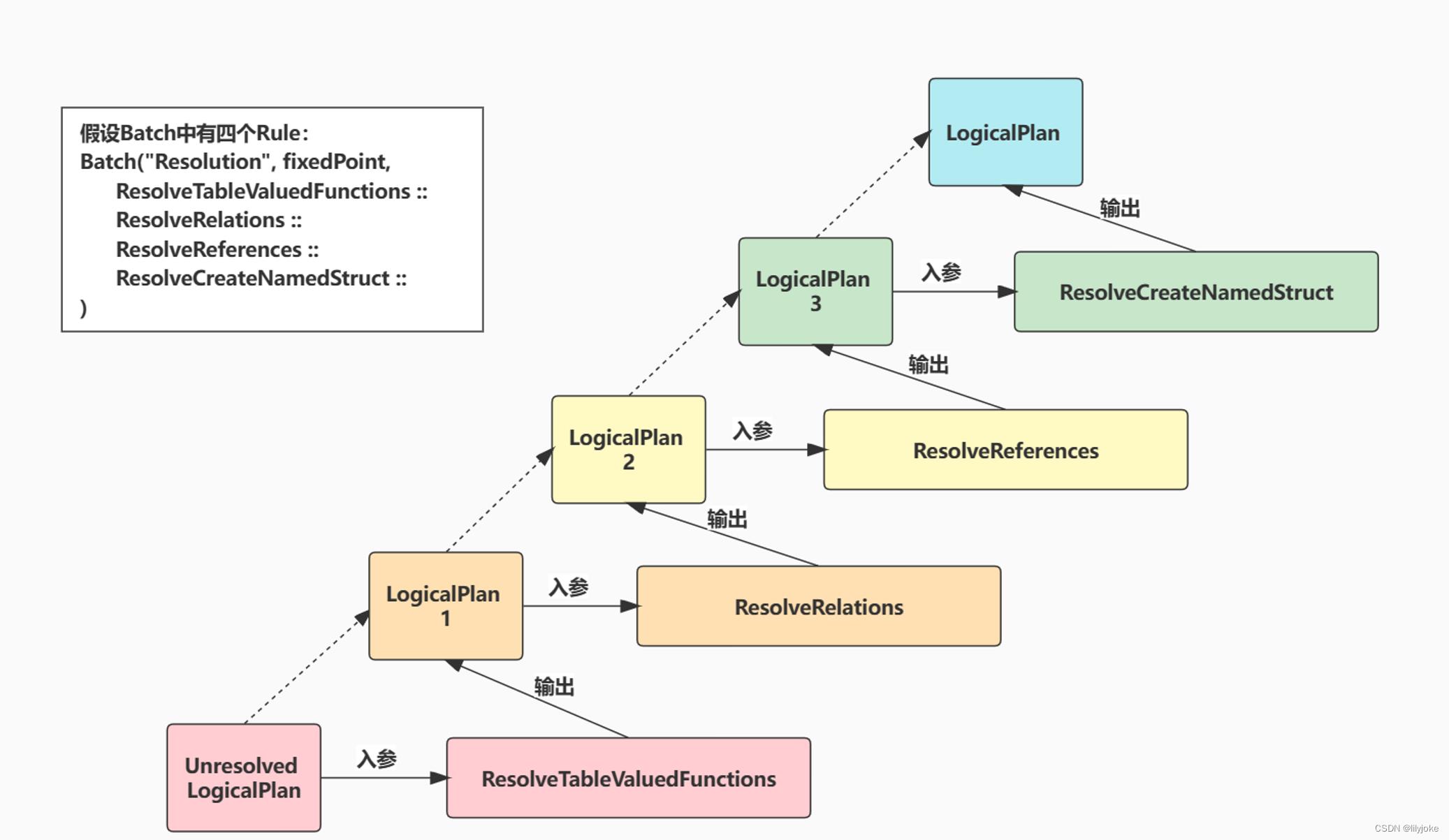
上面代码中,第四步,对于LogicalPlan要根据每个Rule进行迭代转换,用的Scala遍历方法foldLeft,foldLeft和foldRight这两个方法的思路主要是:通过后序遍历规则(先左后右再根),去放置初始值和列表值,其中foldLeft的初始值一定是左叶子节点;foldRight的初始值一定是右叶子节点。这个遍历方法在网上有个哥们说得很清楚,我按照他的思路画一下图,也让我自己梳理一下。
如下图,假设Batch有四个方法,初始入参是Unresolved LogicalPlan:
如果是foldRight,图就会变成 :
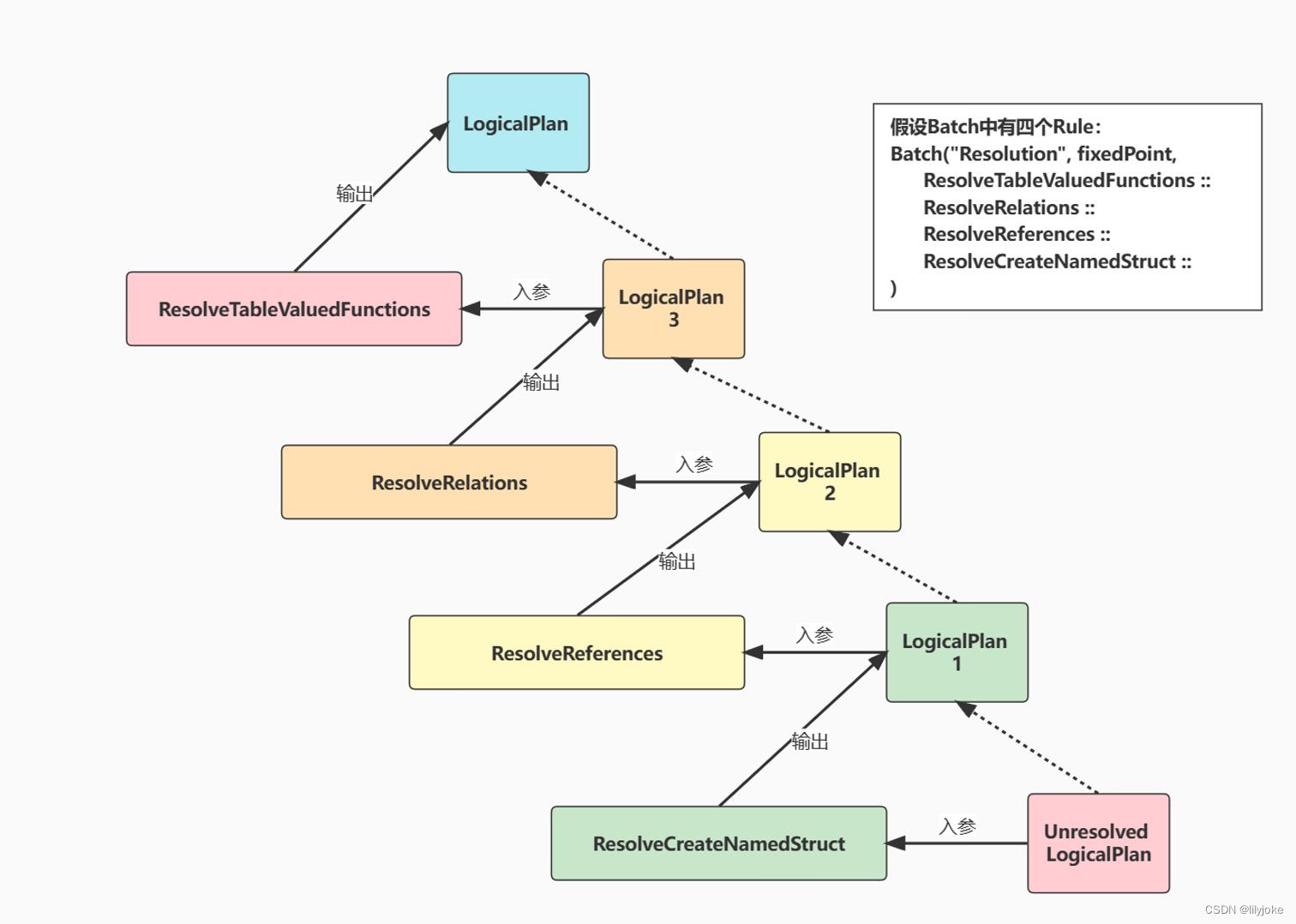
对比
下面是Unresolved LogicalPlan和Analyzed Logical Plan的对比,其实我这个例子不太明显,没有复杂的子查询,然后spark对Unresolved LogicalPlan得到的logicalPlan已经做了一些元数据的关联,因此两个步骤的结果相差不大,只是把AnalysisBarrier去掉了。

4、Optimized Logical Plan
Optimized Logical Plan的生成和第三步的逻辑差不多,主要看下Optimizer自己预定义了哪些Rule Batch。
package org.apache.spark.sql.catalyst.optimizer
abstract class Optimizer(sessionCatalog: SessionCatalog)
extends RuleExecutor[LogicalPlan]
def batches: Seq[Batch] =
val operatorOptimizationRuleSet =
Seq(
// Operator push down
PushProjectionThroughUnion,
ReorderJoin,
EliminateOuterJoin,
PushPredicateThroughJoin,
PushDownPredicate,
LimitPushDown,
ColumnPruning,
InferFiltersFromConstraints,
// Operator combine
CollapseRepartition,
CollapseProject,
CollapseWindow,
CombineFilters,
CombineLimits,
CombineUnions,
// Constant folding and strength reduction
NullPropagation,
...
)
在这个例子里,主要做了两类:
- 谓词下推:把join中的imp_date == '20221216'条件,下推到了tb_hive_test表,这样可以减少数据源要扫描的数据。
- 空值传导:默认判断分区字段不为空,以及join on条件中的的a字段不为空。
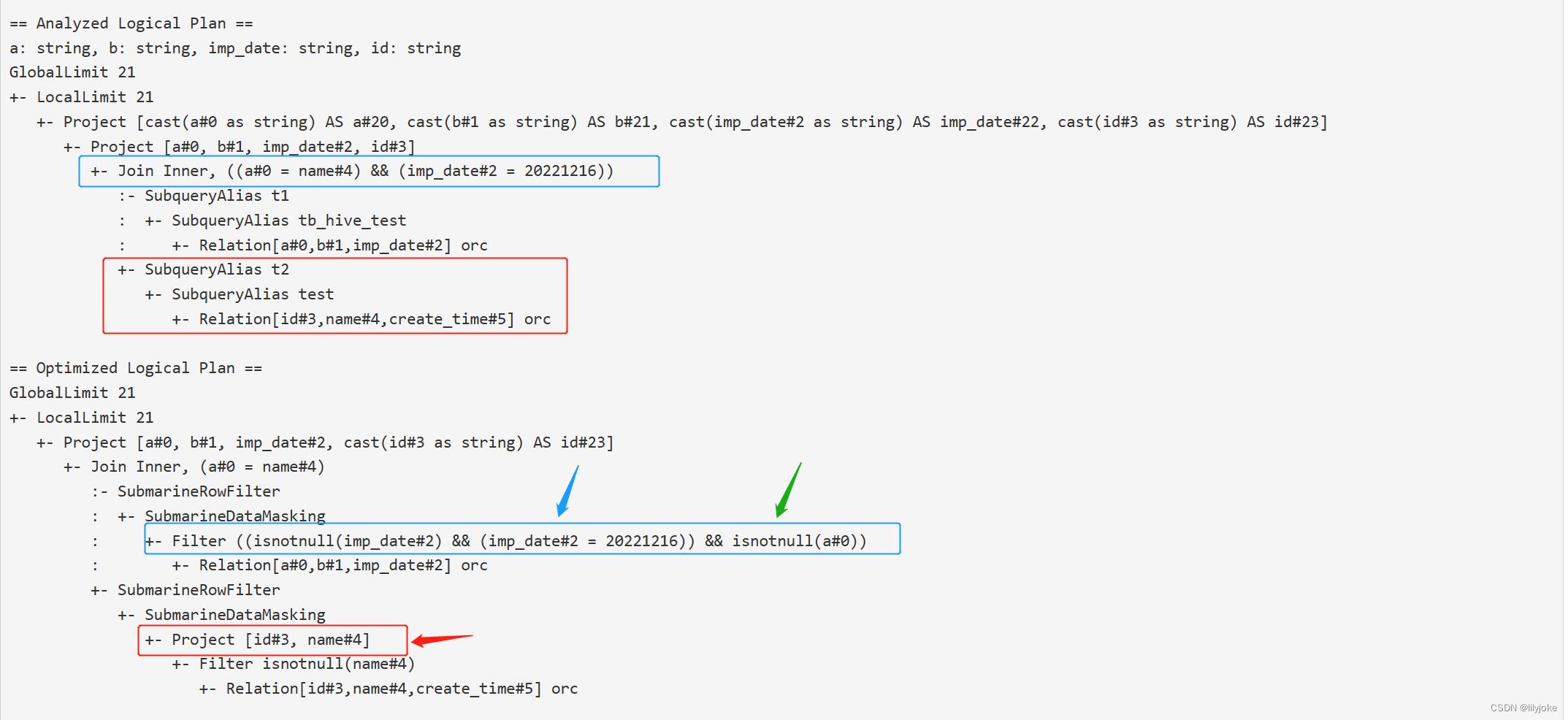
到这一步,这个函数的功能就都实现了。接下来就要用户调用一些action方法将逻辑执行计划转成物理执行计划,例如show(),count(),rdd()等。
5、Physical Plan
假设用户执行了一个collect算子,将结果数据全部汇聚到driver,调用过程是怎么样的?
val conf = new SparkConf().setMaster("yarn").setAppName("test")
val spark = SparkSession.builder.config(conf).getOrCreate
val df = spark.sql("select * from tb_a").collect
调用流程如下:
package org.apache.spark.sql
@InterfaceStability.Stable
class Dataset[T] private[sql](
@transient val sparkSession: SparkSession,
@DeveloperApi @InterfaceStability.Unstable @transient val queryExecution: QueryExecution,
encoder: Encoder[T])
extends Serializable
//1、collect入口函数
def collect(): Array[T] = withAction("collect", queryExecution)(collectFromPlan)
//2、在这里将逻辑执行计划转变为物理执行计划
private def withAction[U](name: String, qe: QueryExecution)(action: SparkPlan => U) =
try
qe.executedPlan.foreach plan =>
plan.resetMetrics()
...最后还是调用到了QueryExecution中的executedPlan方法,代码如下
package org.apache.spark.sql.execution
class QueryExecution(val sparkSession: SparkSession, val logical: LogicalPlan)
//2、将逻辑执行计划转换为物理执行计划
lazy val sparkPlan: SparkPlan =
SparkSession.setActiveSession(sparkSession)
planner.plan(ReturnAnswer(optimizedPlan)).next()
//1、executedPlan懒加载,用时初始化
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
lazy val toRdd: RDD[InternalRow] = executedPlan.execute()
//3、优化物理执行计划,增加shuffle环节。
protected def prepareForExecution(plan: SparkPlan): SparkPlan =
preparations.foldLeft(plan) case (sp, rule) => rule.apply(sp)
protected def preparations: Seq[Rule[SparkPlan]] = Seq(
python.ExtractPythonUDFs, //从运算符中提取PythonUDF,重写查询计划,以便可以在批处理中单独计算UDF,下面几个方法都可以在代码注释中理解其用处。
PlanSubqueries(sparkSession),
EnsureRequirements(sparkSession.sessionState.conf),
CollapseCodegenStages(sparkSession.sessionState.conf), //等下重点说下这个
ReuseExchange(sparkSession.sessionState.conf),
ReuseSubquery(sparkSession.sessionState.conf)) //找出重复的子查询,对引用子查询的地方调用相同的子查询结果。
SparkPlanner
先看上面代码的第二步:
planner.plan(ReturnAnswer(optimizedPlan)).next()这里的逻辑和上面 Analyzer或Optimizer的实现逻辑很类似。都是将具体的执行逻辑放到基类,而自身维护一组要执行的策略。
此处的planner就是SparkPlanner对象, SparkPlanner继承自 SparkStrategies 类,而 SparkStrategies 类则继承自 QueryPlanner基类。
plan() 方法在 QueryPlanner 类中进行具体实现。SparkPlanner自己维护自身的一个strategies,逐个遍历strategies列表中的Strategy,然后将逻辑执行计划转成物理执行计划:
package org.apache.spark.sql.execution
class SparkPlanner(
val sparkContext: SparkContext,
val conf: SQLConf,
val experimentalMethods: ExperimentalMethods)
extends SparkStrategies
//1、维护自身的转换逻辑
override def strategies: Seq[Strategy] =
experimentalMethods.extraStrategies ++
extraPlanningStrategies ++ (
DataSourceV2Strategy ::
FileSourceStrategy ::
DataSourceStrategy(conf) ::
SpecialLimits ::
Aggregation ::
JoinSelection ::
InMemoryScans ::
BasicOperators :: Nil)
abstract class SparkStrategies extends QueryPlanner[SparkPlan]
package org.apache.spark.sql.catalyst.planning
abstract class QueryPlanner[PhysicalPlan <: TreeNode[PhysicalPlan]]
//2、遍历逻辑进行处理
def plan(plan: LogicalPlan): Iterator[PhysicalPlan] =
val candidates = strategies.iterator.flatMap(_(plan))
val plans = candidates.flatMap candidate =>
...
placeholders.iterator.foldLeft(Iterator(candidate))
case (candidatesWithPlaceholders, (placeholder, logicalPlan)) =>
val childPlans = this.plan(logicalPlan)
...
val pruned = prunePlans(plans)
assert(pruned.hasNext, s"No plan for $plan")
pruned
protected def prunePlans(plans: Iterator[PhysicalPlan]): Iterator[PhysicalPlan]
SparkPlan
在 SparkSQL 中,物理计划用 SparkPlan表示,它是所有物理计划的抽象类。有了SparkPlan Tree,才能将其转换成 RDD的DAG。 SparkPlan分四类:
- LeafExecNode,叶子节点,是不存在子节点的。在所有SparkPlan中最基础的,是生成RDD的开始,和数据源相关,例如HiveTableScanExec。
- UnaryExecNode,一元节点,拥有一个子节点的SparkPlan,这种物理执行计划一般是对RDD进行转换,一进一出,例如Exchange重分区。
-
BinaryExecNode,二元节点,拥有两个子节点的SparkPlan,这种物理计划有LeftNode和RightNode组成,例如Join。
-
其他节点,例如CodeGenSupport和UnionExec。
我们等下检几个比较重要的说。
package org.apache.spark.sql.execution
abstract class SparkPlan extends QueryPlan[SparkPlan] with Logging with Serializable
trait LeafExecNode extends SparkPlan
override final def children: Seq[SparkPlan] = Nil
override def producedAttributes: AttributeSet = outputSet
object UnaryExecNode
def unapply(a: Any): Option[(SparkPlan, SparkPlan)] = a match
case s: SparkPlan if s.children.size == 1 => Some((s, s.children.head))
case _ => None
trait BinaryExecNode extends SparkPlan
def left: SparkPlan
def right: SparkPlan
override final def children: Seq[SparkPlan] = Seq(left, right)
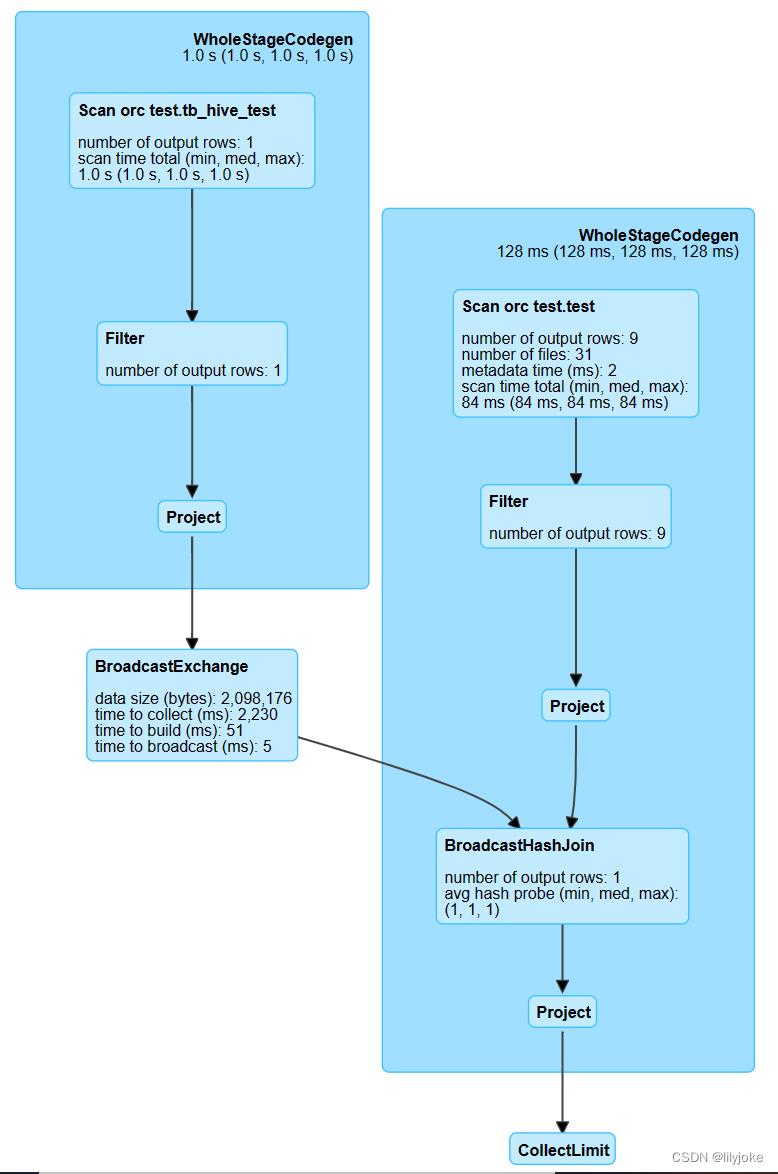
在本例子中,Relation 算子变为 FileScan,Join 算子变为BroadcastHashJoin(因为我的测试数据量很小)。

WholeStageCodegenExec
一般看到Spark history,每个大的蓝框都会有WholeStageCodegenExec,这个是什么?
WholeStageCodegenExec是全阶段代码生成的实现类,用来将多个处理逻辑整合到单个代码模块中,然后将SQL中的逻辑表达式转换成java函数,因为最终来说,用于计算的实体还是一个一个的JVM进程。
以上是关于Spark SQL执行计划到RDD全流程记录的主要内容,如果未能解决你的问题,请参考以下文章