如果我是核酸系统架构师,我会这么用MQ。。。
Posted 石杉的架构笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如果我是核酸系统架构师,我会这么用MQ。。。相关的知识,希望对你有一定的参考价值。
V-xin:ruyuan0330 获得600+页原创精品文章汇总PDF目录
- 一、前情提示
- 二、保证投递消息不丢失的confirm机制
- 三、confirm机制的代码实现
- 四、confirm机制投递消息的高延迟性
- 五、高并发下如何投递消息才能不丢失
- 六、消息中间件全链路100%数据不丢失能做到吗?
一、前情提示
上篇文章:《选Redis做MQ的人,是脑子里缺根弦儿吗?》,我们分析了RabbitMQ开启手动ack机制保证消费端数据不丢失的时候,prefetch机制对消费者的吞吐量以及内存消耗的影响。
通过分析,我们知道了prefetch过大容易导致内存溢出,prefetch过小又会导致消费吞吐量过低,所以在实际项目中需要慎重测试和设置。
这篇文章,我们转移到消息中间件的生产端,一起来看看如何保证投递到MQ的数据不丢失。
如果投递出去的消息在网络传输过程中丢失,或者在RabbitMQ的内存中还没写入磁盘的时候宕机,都会导致生产端投递到MQ的数据丢失。
而且丢失之后,生产端自己还感知不到,同时还没办法来补救。
下面的图就展示了这个问题。
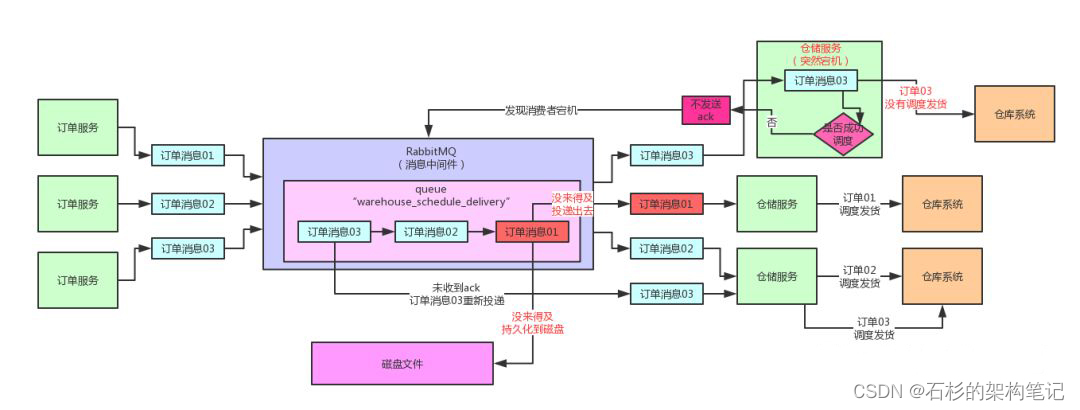
所以本文呢,我们就来逐步分析一下。
二、保证投递消息不丢失的confirm机制
其实要解决这个问题,相信大家看过之前的消费端ack机制之后,也都猜到了。
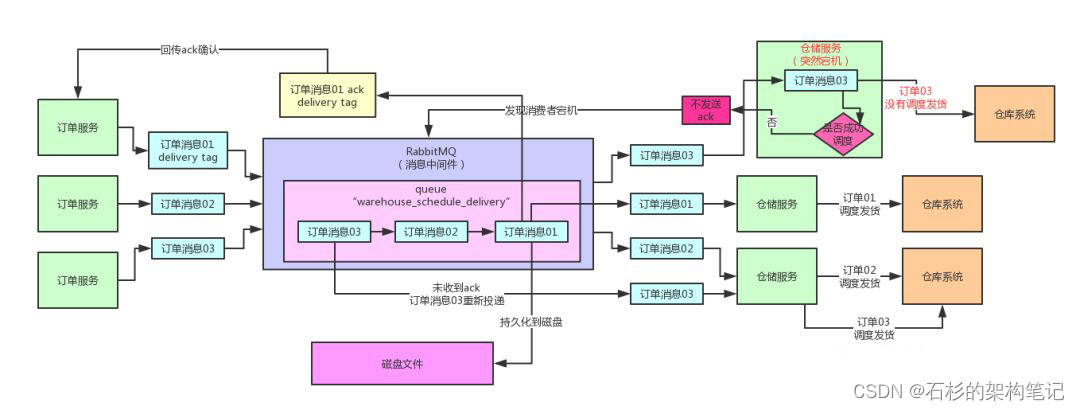
很简单,就是生产端(比如上图的订单服务)首先需要开启一个confirm模式,接着投递到MQ的消息,如果MQ一旦将消息持久化到磁盘之后,必须也要回传一个confirm消息给生产端。
这样的话,如果生产端的服务接收到了这个confirm消息,就知道是已经持久化到磁盘了。
否则如果没有接收到confirm消息,那么就说明这条消息半路可能丢失了,此时你就可以重新投递消息到MQ去,确保消息不要丢失。
而且一旦你开启了confirm模式之后,每次消息投递也同样是有一个delivery tag的,也是起到唯一标识一次消息投递的作用。
这样,MQ回传ack给生产端的时候,会带上这个delivery tag。你就知道具体对应着哪一次消息投递了,可以删除这条消息。
此外,如果RabbitMQ接收到一条消息之后,结果内部出错发现无法处理这条消息,那么他会回传一个nack消息给生产端。此时你就会感知到这条消息可能处理有问题,你可以选择重新再次投递这条消息到MQ去。
或者另一种情况,如果某条消息很长时间都没给你回传ack/nack,那可能是极端意外情况发生了,数据也丢了,你也可以自己重新投递消息到MQ去。
通过这套confirm机制,就可以实现生产端投递消息不会丢失的效果。大家来看看下面的图,一起来感受一下。
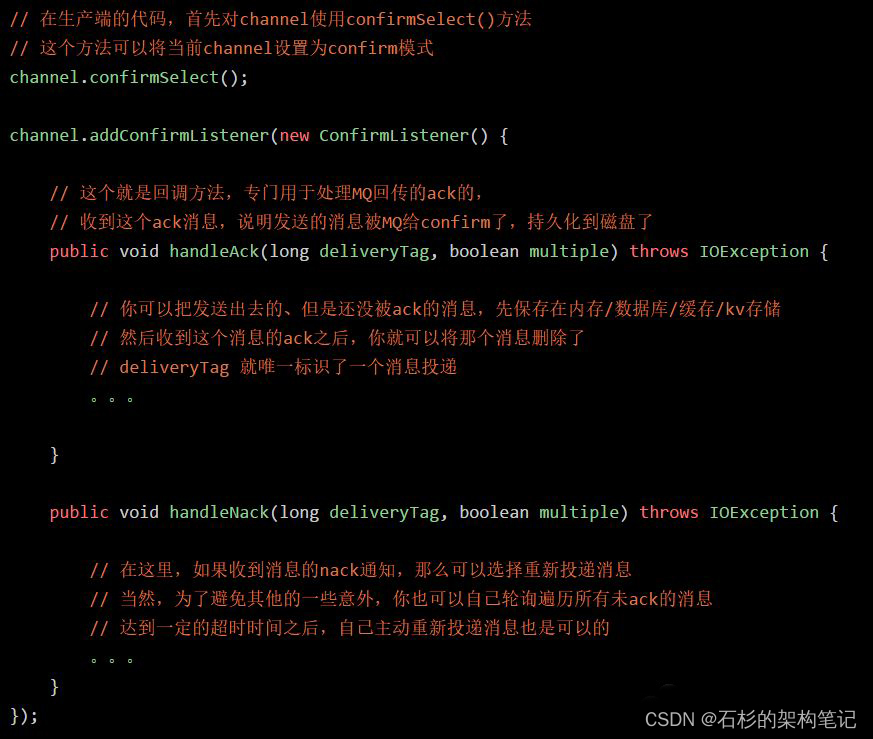
三、confirm机制的代码实现
下面,我们再来看看confirm机制的代码实现:
四、confirm机制投递消息的高延迟性
这里有一个很关键的点,就是一旦启用了confirm机制投递消息到MQ之后,MQ是不保证什么时候会给你一个ack或者nack的。
因为RabbitMQ自己内部将消息持久化到磁盘,本身就是通过异步批量的方式来进行的。
正常情况下,你投递到RabbitMQ的消息都会先驻留在内存里,然后过了几百毫秒的延迟时间之后,再一次性批量把多条消息持久化到磁盘里去。
这样做,是为了兼顾高并发写入的吞吐量和性能的,因为要是你来一条消息就写一次磁盘,那么性能会很差,每次写磁盘都是一次fsync强制刷入磁盘的操作,是很耗时的。
所以正是因为这个原因,你打开了confirm模式之后,很可能你投递出去一条消息,要间隔几百毫秒之后,MQ才会把消息写入磁盘,接着你才会收到MQ回传过来的ack消息,这个就是所谓confirm机制投递消息的高延迟性。
大家看看下面的图,一起来感受一下。
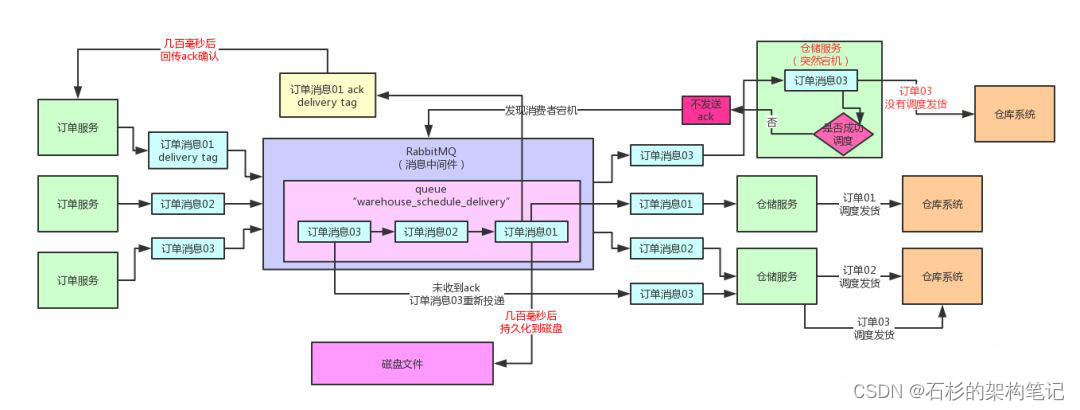
五、高并发下如何投递消息才能不丢失
大家可以考虑一下,在生产端高并发写入MQ的场景下,你会面临两个问题:
- 1、你每次写一条消息到MQ,为了等待这条消息的ack,必须把消息保存到一个存储里。
并且这个存储不建议是内存,因为高并发下消息是很多的,每秒可能都几千甚至上万的消息投递出去,消息的ack要等几百毫秒的话,放内存可能有内存溢出的风险。
- 2、绝对不能以同步写消息 + 等待ack的方式来投递,那样会导致每次投递一个消息都同步阻塞等待几百毫秒,会导致投递性能和吞吐量大幅度下降。
针对这两个问题,相对应的方案其实也呼之欲出了。
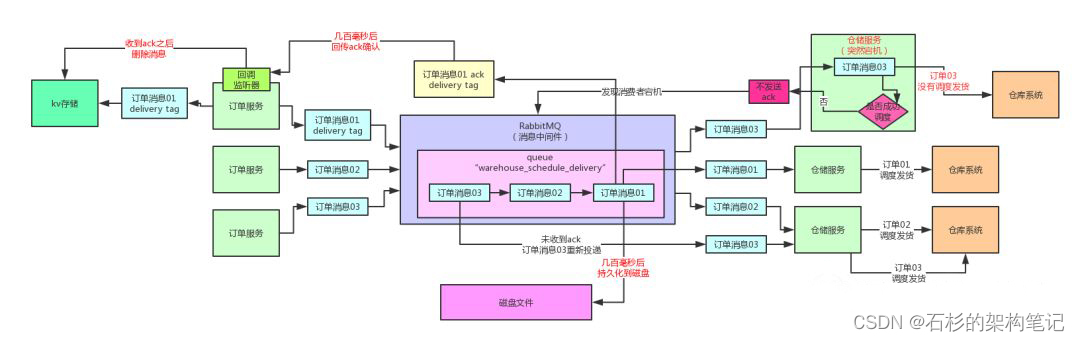
首先,用来临时存放未ack消息的存储需要承载高并发写入,而且我们不需要什么复杂的运算操作,这种存储首选绝对不是mysql之类的数据库,而建议采用kv存储。kv存储承载高并发能力极强,而且kv操作性能很高。
其次,投递消息之后等待ack的过程必须是异步的,也就是类似上面那样的代码,已经给出了一个初步的异步回调的方式。
消息投递出去之后,这个投递的线程其实就可以返回了,至于每个消息的异步回调,是通过在channel注册一个confirm监听器实现的。
收到一个消息ack之后,就从kv存储中删除这条临时消息;收到一个消息nack之后,就从kv存储提取这条消息然后重新投递一次即可;也可以自己对kv存储里的消息做监控,如果超过一定时长没收到ack,就主动重发消息。
大家看看下面的图,一起来体会一下:
六、消息中间件全链路100%数据不丢失能做到吗?
到此为止,我们已经把生产端和消费端如何保证消息不丢失的相关技术方案结合RabbitMQ这种中间件都给大家分析过了。
其实,架构思想是通用的, 无论你用的是哪一种MQ中间件,他们提供的功能是不太一样的,但是你都需要考虑如下几点:
- 生产端如何保证投递出去的消息不丢失:消息在半路丢失,或者在MQ内存中宕机导致丢失,此时你如何基于MQ的功能保证消息不要丢失?
- MQ自身如何保证消息不丢失:起码需要让MQ对消息是有持久化到磁盘这个机制。
- 消费端如何保证消费到的消息不丢失:如果你处理到一半消费端宕机,导致消息丢失,此时怎么办?
目前来说,我们初步的借着RabbitMQ举例,已经把从前到后一整套技术方案的原理、设计和实现都给大家分析了一遍了。
但是此时真的能做到100%数据不丢失吗?恐怕未必,大家再考虑一下个特殊的场景。
生产端投递了消息到MQ,而且持久化到磁盘并且回传ack给生产端了。
但是此时MQ还没投递消息给消费端,结果MQ部署的机器突然宕机,而且因为未知的原因磁盘损坏了,直接在物理层面导致MQ持久化到磁盘的数据找不回来了。
这个大家千万别以为是开玩笑的,大家如果留意留意行业新闻,这种磁盘损坏导致数据丢失的是真的有的。
那么此时即使你把MQ重启了,磁盘上的数据也丢失了,数据是不是还是丢失了?
你说,我可以用MQ的集群机制啊,给一个数据做多个副本,比如后面我们就会给大家分析RabbitMQ的镜像集群机制,确实可以做到数据多副本。
但是即使数据多副本,一定可以做到100%数据不丢失?
比如说你的机房突然遇到地震,结果机房里的机器全部没了,数据是不是还是全丢了?
说这个,并不是说要抬杠。而是告诉大家,技术这个东西,100%都是理论上的期望。
应该说,我们凡事都朝着100%去做,但是理论上是不可能完全做到100%保证的,可能就是做到99.9999%的可能性数据不丢失,但是还是有千万分之一的概率会丢失。
当然,从实际的情况来说,能做到这种地步,其实基本上已经基本数据不会丢失了。
V-xin:ruyuan0330 获得600+页原创精品文章汇总PDF另外推荐儒猿课堂的1元系列课程给您,欢迎加入一起学习~
SpringCloudAlibaba零基础入门到项目实战(1元专享)
基于ShardingSphere的分库分表实战课(1元专享)
以上是关于如果我是核酸系统架构师,我会这么用MQ。。。的主要内容,如果未能解决你的问题,请参考以下文章