独一无二的「MySQL调优金字塔」相信也许你拥有了它,就再也不用为数据库性能发愁
Posted 洛神灬殇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了独一无二的「MySQL调优金字塔」相信也许你拥有了它,就再也不用为数据库性能发愁相关的知识,希望对你有一定的参考价值。
文章目录
- 开发俏皮话
- 笔者瞩望
- 技术金字塔
- 技术梗概
- 调优白皮书
开发俏皮话
【让我996不算啥,我只怕测试也996给我提bug!】
笔者瞩望
你好,无论我们在现实生活中是否相识,在CSDN的世界里终会快乐相遇,在此提前预祝国庆节快乐,并且在属于我们的“1024”那天不在加班,早点回家陪陪老婆和孩子啊。
技术金字塔
本篇文章会按照自上而下以及自下而上的两种方向去“游览”【mysql技术金字塔】,两个方向分别是从成本出发的(潜台词就是便宜越好,照顾公司成本哦!),本章内容,可能有点多,希望大家慢慢消化,实在不行来片“吗丁啉”,哈哈,开玩笑了!
技术梗概
主要技术分布为6大部分,如下图金子图所示:
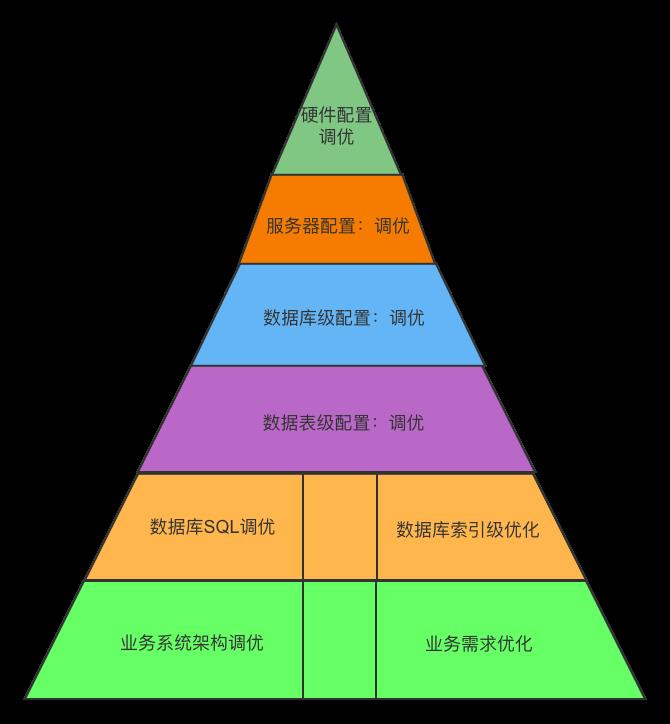
研发成本角度
从软件的【研发成本】的角度而言:伴随着优化的方向,从金字塔顶部像金字塔底部的方向进行过度,伴随着高度越来越低,成本会越来越低,这个方向其实是非常考验技术人员与项目管理者的能力的,但是它确实,老板对象看到的,哈哈。

技术可行性和效果角度
从软件的【技术可行性和效果】的角度而言:伴随着优化的方向,从金字塔低部像金字塔顶部的方向进行过度,伴随着高度越来越高,成本会越来越高,耗费的财力和人力也会相对的有所降低,但是如果多花钱,老板肯定不愿意,比如,请一些行业大牛或者一些牛掰的服务器等,可以看出来正好与上面的方向相反。
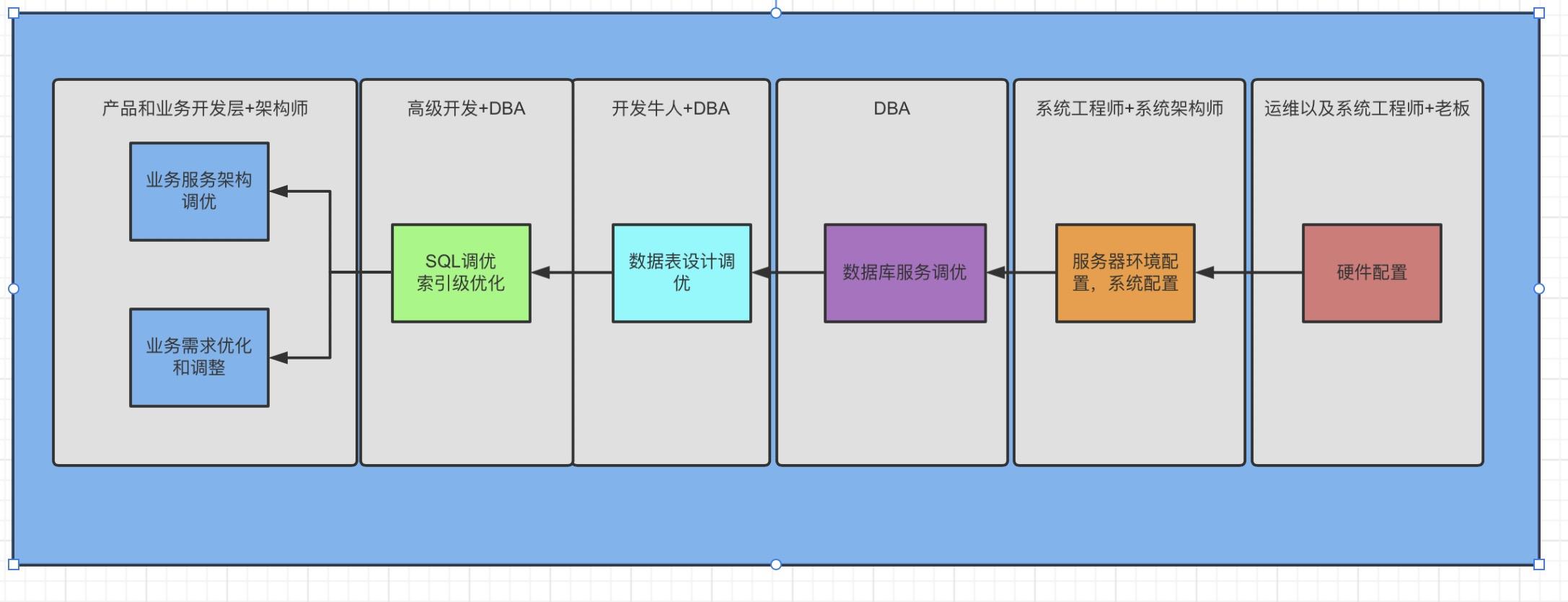
总结一下,以上这两点的方针,遵循着研发成本的越来越低+效果方案越来越高,那么我们就划分出一个公式,作为系统服务调优方法论,我们就按照金字塔层面,进行自下而上进行调优!我们接下来就来按照这个方向进行分析。
调优白皮书
业务需求和业务架构
产品中单要支援,需求出装要全面。——王者荣耀之产品篇
调整一下合适的需求,其实是一个很不错的方案,所以如果可以从根本上去出发,进行调整需求是一个很有效果的方案哦!并且对一些不合理的需求说不!在做架构设计的时候,应该充分考虑业务实际场景,考虑好数据库的选项和引入一些其他的方案是非常重要的,例如NoSQL或者NewSQL等。所以,调整好一个一个系统架构是一个非常不错的方案。
- 尽量将请求拦截在系统上游传统业务系统之所以挂,请求都压倒了后端数据层,数据读写锁冲突严重,并发高响应慢,几乎所有请求都超时,流量虽大,下单成功的有效流量甚小。
- 读多写少的常用多使用缓存这是一个典型的读多写少的应用场景,非常适合使用缓存。
SQL技术调优
根据业务需求,不单纯的写好SQL语句,还要对SQL语句进行调优,使得其性能变得最佳化。
调优的思路
调优主要有三个部分组成:发现问题、分析问题和解决问题。
发现问题(慢SQL的优化和分析)
发现慢SQL以及查询日志
查询慢SQL的日志是MySQL内置的一个功能,可以记录执行时间超过我们配置阈值的SQL语句。
参数与默认值:

使用方式-修改MySQL服务配置
一般我们就设置“老三样”即可!
- 修改我们安装后的配置文件my.cnf,在[mysqld]段落中加入以上参数配置:
[mysqld]
log_output='FILE,TABLE';
slow_query_log=ON // 代表开启慢sql参数进行开启
long_query_time=0.001 //查询时间(秒)
- 之后进行重启服务
service mysqld restart
使用方式-修改全局服务配置
set global log_output='TABLE,FILE';
set global slow_query_log = 'NO';
set long_query_time = 0.001;
这种方式,不需要重启就可以生效,但是当服务器重启的时候,又会重新丢失配置。
以上的配置可以将慢查询SQL记录到mysql数据库中的slow_log表中以及对应的slow_sql的文件中去。
分析慢SQ的查询日志
查询slow_log表,当根据上面的设置,当log_output设置为TABLE的时候,就会将mysql的慢查询日志记录到mysql.slow_log表中去,我们可以采用select * from mysql.slow_log去进行查询,可以根据此方面进行分析和统计sql的执行性能。
分析慢SQL日志文件
当log_output设置为FILE的时候,因为文件过大,不方便查看,所以可以采用专门的工具进行分析,这里主要介绍原生的mysqldumpslow工具进行分析,如下图所示:
mysqldumpslow --help:

使用案例:
- 如果要查询出返回结果行数最多的20条SQL:
mysqldumpslow -s r -t 20 /path/show.log
- 根据查询时间进行排序,并且带有left join的20条SQL:
mysqldumpslow -s t -t -g "left join" /path/show.log
当然还有其他相关的MySQL慢查询分析日志工具,例如mysql profiles或者pt-query-digest也可以专门进行分析。有兴趣的小伙伴可以搜搜看。
执行计划分析慢SQL
explain关键字进行执行慢SQL语句,进行指标分析:
案例分析
最简单的案例就是:
explain sql语句
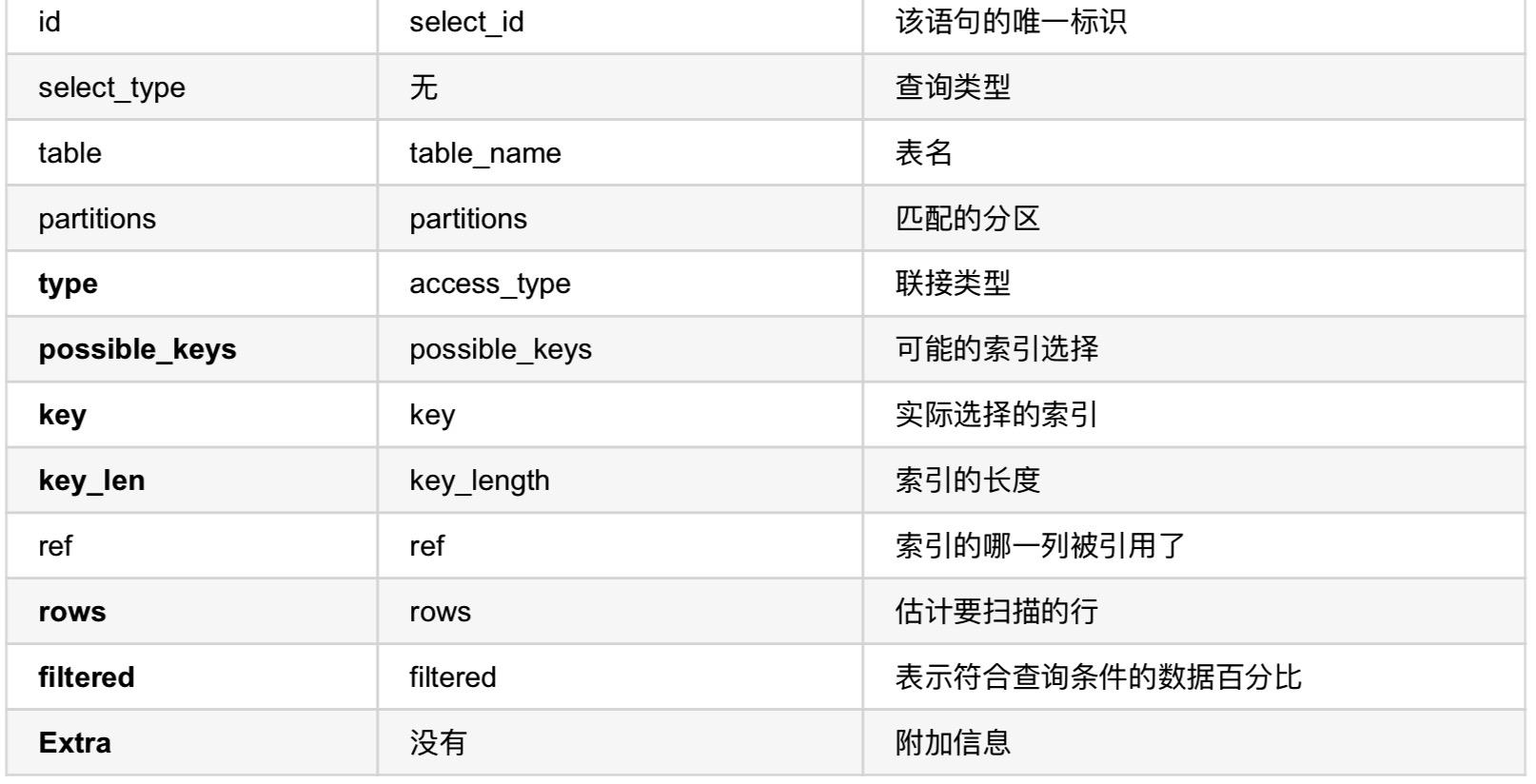
id字段
它表示代表着语句SQL中每一个部分原子查询(维护)操作的标识单位,如果explain中的有多个id对应的数据项,那么切记一定要按照:倒叙进行执行,也就是说:
- 数字越大的,越先执行分析
- 数字编号相同,从上到下进行分析
select_type字段
查询类型,如下几组值:

table字段
它表示当前这一行正在访问哪张表,如果SQL定义了别名,则展示表的别名
partitions字段
当前查询匹配记录的分区。对于未分区的表,返回null。
type字段
连接类型,有如下几种取值,性能从好到坏排序 如下:
system:
该表只有一行(相当于系统表),system是const类型的特例。
const:
针对主键或唯一索引的等值查询扫描, 最多只返回一行数据. const查询速度非常快, 因为它仅仅读取一次即可。
eq_ref:
当使用了索引的全部组成部分,并且索引是PRIMARY KEY或UNIQUE NOT NULL 才会使用该类型,性能 仅次于system及const。
多表关联查询,单行匹配
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
多表关联查询,联合索引,多行匹配
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
ref
当满足索引的最左前缀规则,或者索引不是主键也不是唯一索引时才会发生。如果使用的索引只会匹配到少量的行,性能也是不错的。
根据索引(非主键,非唯一索引),匹配到多行
SELECT * FROM ref_table WHERE key_column=expr;
多表关联查询,单个索引,多行匹配
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
多表关联查询,联合索引,多行匹配
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
TIPS
最左前缀原则,指的是索引按照最左优先的方式匹配索引。比如创建了一个组合索引(column1, column2, column3),那么,如果查询条件是:
- WHERE column1 = 1、WHERE column1= 1 AND column2 = 2、WHERE column1= 1 AND column2 = 2 AND column3 = 3 都可以使用该索引;
- WHERE column2 = 2、WHERE column2 = 1 AND column3 = 3就无法匹配该索引。
fulltext:全文索引
ref_or_null
该类型类似于ref,但是MySQL会额外搜索哪些行包含了NULL。这种类型常⻅于解析子查询。
SELECT * FROM ref_table WHERE key_column=expr OR key_column IS NULL;
index_merge
此类型表示使用了索引合并优化,表示一个查询里面用到了多个索引。
unique_subquery
该类型和eq_ref类似,但是使用了IN查询,且子查询是主键或者唯一索引。例如:
value in ( select primary_key from single_table where some_condition)
index_subquery
value in ( select key_column from single_table where some_condition)
和unique_subquery类似,只是子查询使用的是非唯一索引
range
范围扫描,表示检索了指定范围的行,主要用于有限制的索引扫描。比较常⻅的范围扫描是带有 BETWEEN子句或WHERE子句里有>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE、IN()等操作符。
SELECT * FROM tbl_name
WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name
WHERE key_column IN (10,20,30);
index
全索引扫描,和ALL类似,只不过index是全盘扫描了索引的数据。当查询仅使用索引中的一部分列时,可使用此类型。有两种场景会触发:
-
如果索引是查询的覆盖索引,并且索引查询的数据就可以满足查询中所需的所有数据,则只扫描索引树。此 时,explain的Extra 列的结果是Using index。index通常比ALL快,因为索引的大小通常小于表数据。
-
按索引的顺序来查找数据行,执行了全表扫描。此时,explain的Extra列的结果不会出现Uses index。
ALL
全表扫描,性能最差。
possible_keys
展示当前查询可以使用哪些索引,这一列的数据是在优化过程的早期创建的,因此有些索引可能对于后续优化过程是没用的。
key
表示MySQL实际选择的索引
key_len
索引使用的字节数。由于存储格式,当字段允许为NULL时,key_len比不允许为空时大1字节。
key_len计算公式
可以参考博客: https://www.cnblogs.com/gomysql/p/4004244.html
ref
表示将哪个字段或常量和key列所使用的字段进行比较。 如果ref是一个函数,则使用的值是函数的结果。要想查看是哪个函数,可在EXPLAIN语句之后紧跟一个SHOW WARNING语句。
rows
MySQL估算SQL执行后会扫描的行数,数值越小越好。
filtered
符合查询条件的数据百分比,最大100。用rows × filtered可获得和下一张表连接的行数。例如rows = 1000, filtered = 50%,则和下一张表连接的行数是500。
TIPS
在MySQL 5.7之前,想要显示此字段需使用explain extended命令; MySQL.5.7及更高版本,explain默认就会展示filtered
Extra(重点分析)
展示有关本次查询的附加信息,取值如下:
- Child of ‘table’ pushed join@1
此值只会在NDB Cluster下出现。
- const row not found
查询语句SELECT … FROM tbl_name,而表是空的
- Deleting all rows
对于DELETE语句,某些引擎(例如MyISAM)支持以一种简单而快速的方式删除所有的数据,如果使用了这种优化,则显示此值.
- Distinct
查找distinct值,当找到第一个匹配的行后,将停止为当前行组合搜索更多行
FirstMatch(tbl_name)当前使用了半连接FirstMatch策略.
- Full scan on NULL key
子查询中的一种优化方式,在无法通过索引访问null值的时候使用
- Impossible HAVING
HAVING子句始终为false,不会命中任何行
- Impossible WHERE
WHERE子句始终为false,不会命中任何行
- Impossible WHERE noticed after reading const tables
MySQL已经读取了所有const(或system)表,并发现WHERE子句始终为false
LooseScan(m…n)当前使用了半连接LooseScan策略,
- No matching min/max row
没有任何能满足例如 SELECT MIN(…) FROM … WHERE condition 中的condition的行
160
- no matching row in const table
对于关联查询,存在一个空表,或者没有行能够满足唯一索引条件
- No matching rows after partition pruning
对于DELETE或UPDATE语句,优化器在partition pruning(分区修剪)之后,找不到要delete或update的内容
- No tables used
当此查询没有FROM子句或拥有FROM DUAL子句时出现。例如:explain select 1
- Not exists
MySQL能对LEFT JOIN优化,在找到符合LEFT JOIN的行后,不会为上一行组合中检查此表中的更多行。例如:
SELECT * FROM t1 LEFT JOIN t2 ON t1.id=t2.id WHERE t2.id IS NULL;
MySQL8以前的版本会这么分析:
例如,t2.id定义成了 NOT NULL ,此时,MySQL会扫描t1,并使用t1.id的值查找t2中的行。 如果MySQL在t2中找到一 个匹配的行,它会知道t2.id永远不会为NULL,并且不会扫描t2中具有相同id值的其余行。也就是说,对于t1中的每 一行,MySQL只需要在t2中只执行一次查找,而不考虑在t2中实际匹配的行数。
MySQL 8.0.17及更高版本中:
-
如果出现此提示,还可表示形如 NOT IN (subquery) 或 NOT EXISTS (subquery) 的WHERE条件已经在内部转换为反连接。
-
这将删除子查询并将其表放入最顶层的查询计划中,从而改进查询的开销。通过合并半连接和反联接,优化器可以更加自由地对执行计划中的表重新排序,在某些情况下,可让查询提速。
可以通过在EXPLAIN语句后紧跟一个SHOW WARNING语句,并分析结果中Message列,从而查看何时 对该查询执行了反联接转换。
反连接:两表关联只返回主表的数据,并且只返回主表与子表没关联上的数据,这种的连接方式。
- Plan isn’t ready yet
使用了EXPLAIN FOR CONNECTION,当优化器尚未完成为在指定连接中为执行的语句创建执行计划时, 就会出现此值。
-
Range checked for each record (index map: N)
-
MySQL没有找到合适的索引去使用,但是去检查是否可以使用range或index_merge来检索行时,会出现此提示。
-
index map N索引的编号从1开始,按照与表的SHOW INDEX所示相同的顺序。 索引映射值N是指示哪些索引是候 选的位掩码值。 例如0x19(二进制11001)的值意味着将考虑索引1、4和5。
-
好了看到这里你是否会觉得已经眼花缭乱了?现在开始重头戏,上面的可以作为知识扩展和了解,但下面的内容建议你一定要理解哦,会对性能优化有很大的帮助哦!
- unique row not found
对于形如 SELECT … FROM tbl_name 的查询,但没有行能够满足唯一索引或主键查询的条件。
-
Using filesort(重点)
- 出现的原因:当SQL查询中包含 ORDER BY子句的操作后,而且无法利用索引完成排序操作的时候,MySQL Query Optimizer 不得不选择 相应的排序算法来实现。
- 数据较少时从内存排序,当超过Memory_Sort的阈值的时候就会从磁盘排序,性能超级低哦!
- 并且,Explain命令并不会显示的告诉MySQL数据库客户端用哪种排序。
官方解释:MySQL需要额外的一次传递,以找出如何按排序顺序检索行。
- 通过根据联接类型浏览所有行,并为所有匹配WHERE子句的行保存排序关键字和行的指针来完成排序。
- 然后关键字被排序,并按排序顺序检索行。
-
Using index(重点)
- (俗称:单覆盖索引哦!),仅使用索引树中的信息从表中检索列信息,而不必进行其他查找以读取实际行。
- 当查询仅使用属于单个索引的列时,可以使用此策略。例如:
select id from table -
Using index condition(重点)
- (俗称:覆盖下推哦!),表示先按条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行。通过这种方式,除非有必要,否则索引信息将可以延迟“下推”读取整个行的数据。例如:
SELECT * FROM people where id > 10 and age = 10 or address > 100000 ;
可以通过开关进行调整开或者关闭索引条件下推
SET optimizer_switch = 'index_condition_pushdown=off';
SET optimizer_switch = 'index_condition_pushdown=on';
多说一句,MySQL分成了Server层和Engine层,下推指的是将请求交给引擎层处理,相比较而言性能差异有不同的引擎决定。
- Using index for group-by(次重点)
数据访问和 Using index 一样,所需数据只须要读取索引,当Query 中使用GROUP BY或DISTINCT 子句时,如果分组字段也在索引中,Extra中的信息就会是 Using index for group-by,例如:
explain SELECT name FROM t1 group by name
- Using index for skip scan(不是特别重要,记住它算是SQL索引其效果了)
表示使用了Skip Scan。底层采用了“Skip Scan Range Access Method算法机制”,意思说是提前做出了索引查询定位,并且减少了很多的扫描,其实和using Index区别不大!
- Using join buffer (Block Nested Loop),不是特别重要,表示采用了嵌套子查询的缓存批次处理技术!
Using join buffer 使用Block Nested Loop或Batched Key Access算法提高join的性能,此部分属于采用了Batched Key Access(批次关键字进行检索),意思是不会再进行一行一行对比,而是进行一批一批的方式进行比较,并且他们的内存行类似相邻的位置,所以采用buffer缓存快的机制缓存这一批次对比检索的数据,大大提高了效率!
具体有兴趣的小伙伴可以推荐参考: https://www.cnblogs.com/chenpingzhao/p/6720531.html
- Using MRR
使用了Multi-Range Read优化策略。详⻅ “Multi-Range Read Optimization”
Using sort_union(…), Using union(…), Using intersect(…),这些指示索引扫描如何合并为index_merge连接类型。详⻅参考官方的“Index Merge Optimization” 。
- Using temporary(非常重要)
上面说了当出现排序或者分组的时候数据需要进行进一步的计算,此时无法利用索引那天然的数据模型来解决的时候该咋办!为了解决该查询,MySQL需要创建一个临时表来保存结果。如果查询包含不同列的GROUP BY和 ORDER BY子 句,通常会发生这种情况。
-
name字段有索引
- explain SELECT name FROM t1 group by name
-
name无索引
- explain SELECT name FROM t1 group by name。
-
Using where(比较重要)
如果我们不是读取表的所有数据,或者不是仅仅通过索引就可以获取所有需要的数据,则会出现using where信息。阈值相对应的就是“覆盖索引哦”!
SELECT * FROM t1 where id = 1
- Zero limit
该查询有一个limit 0子句,不能选择任何行。
explain SELECT name FROM resource_template limit 0
Explain的命令讲解
EXPLAIN可产生额外的扩展信息,可通过在EXPLAIN语句后紧跟一条SHOW WARNING语句查看扩展信息。
- 在MySQL 8.0.12及更高版本,扩展信息可用于SELECT、DELETE、INSERT、REPLACE、UPDATE语句;
- 在MySQL 8.0.12之前,扩展信息仅适用于SELECT语句;
- 在MySQL 5.6及更低版本,需使用EXPLAIN EXTENDED xxx语句;而从MySQL 5.7开始,无需添加 EXTENDED关键词。
SHOW WARNING的结果并不一定是一个有效SQL,也不一定能够执行(因为里面包含了很多特殊标记)
特殊取值含义介绍
-
<auto_key>:自动生成的临时表key。
-
(expr):表达式(例如标量子查询)执行了一次,并且将值保存在了内存中以备以后使用。对于包括多个值的结果,可能会 创建临时表,你将会看到 的字样。
-
(query fragment):子查询被转换为 EXISTS,性能会变得更加好。
-
<in_optimizer>(query fragment):这是一个内部优化器对象,对用户没有任何意义
-
<index_lookup>(query fragment):使用索引查找来处理查询片段,从而找到合格的行
-
(condition, expr1, expr2):如果条件是true,则取expr1,否则取expr2
-
<is_not_null_test>(expr):验证表达式不为NULL的测试
-
(query fragment):使用子查询实现
-
materialized-subquery.col_name,在内部物化临时表中对col_name的引用,以保存子查询的结果
-
<primary_index_lookup>(query fragment): 使用主键来处理查询片段,从而找到合格的行
-
<ref_null_helper>(expr):这是一个内部优化器对象,对用户没有任何意义
-
/* select#N */ select_stmt:SELECT与非扩展的EXPLAIN输出中id=N的那行关联
-
outer_tables semi join (inner_tables):半连接操作。
-
:表示创建了内部临时表而缓存中间结果
估计查询性能
多数情况下,你可以通过计算磁盘的搜索次数来估算查询性能。对于比较小的表,通常可以在一次磁盘搜索中找到行 (因为索引可能已经被缓存了),而对于更大的表,你可以使用B-tree索引进行估算:你需要进行多少次查找才能找到 行: log(row_count) / log(index_block_length / 3 * 2 / (index_length + data_pointer_length)) + 1
在MySQL中,index_block_length通常是1024字节,数据指针一般是4字节。比方说,有一个500,000的表,key是3字 节,那么根据计算公式 log(500,000)/log(1024/3*2/(3+4)) + 1 = 4 次搜索。
该索引将需要500,000 7 3/2 = 5.2MB的存储空间(假设典型的索引缓存的填充率是2/3),因此你可以在内存中存放更 多索引,可能只要一到两个调用就可以找到想要的行了。
但是,对于写操作,你需要四个搜索请求来查找在何处放置新的索引值,然后通常需要2次搜索来更新索引并写入行。
前面的讨论并不意味着你的应用性能会因为log N而缓慢下降。只要内容被OS或MySQL服务器缓存,随着表的变大,只 会稍微变慢。在数据量变得太大而无法缓存后,将会变慢很多,直到你的应用程序受到磁盘搜索约束(按照log N增 ⻓)。为了避免这种情况,可以根据数据的增⻓而增加key的。对于MyISAM表,key的缓存大小由名为key_buffer_size 的系统变量控制,详⻅ Section 5.1.1, “Configuring the Server”
SQL性能分析
SQL性能分析的手段我们主要介绍一下三种:
- SHOW PROFILE
- INFORMATION_SCHEMA.PROFILING
- PERFORMANCE_SCHEMA
SHOW PROFILE(旧版本的MySQL服务可使用,新版本已废弃)
SHOW PROFILE是MySQL的一个性能分析命令,可以跟踪SQL各种资源消耗。使用格式如下:
SHOW PROFILE [type [, type] ... ] [FOR QUERY n]
[LIMIT row_count [OFFSET offset]]
- type的选值范围:
- ALL:显示所有信息
- BLOCK IO:显示阻塞的输入输出次数
- CONTEXT SWITCHES:显示自愿及非自愿的上下文切换次数
- CPU:显示用户与系统CPU使用时间
- IPC:显示消息发送与接收的次数
- MEMORY:显示内存相关的开销,目前未实现此功能
- PAGE FAULTS:显示⻚错误相关开销信息
- SOURCE:列出相应操作对应的函数名及其在源码中的位置(行)
- SWAPS:显示swap交换次数
默认情况下,SHOW PROFILE只展示Status和Duration两列,如果想展示更多信息,可指定type,使用步骤如下:
- 查看是否支持SHOW PROFILE功能,yes标志支持。从MySQL 5.0.37开始,MySQL支持SHOW PROFILE。
select @@have_profiling;
- 查看当前是否启用了SHOW PROFILE,0表示未启用,1表示已启用
select @@profiling;
- 设置为当前会话开启或关闭性能分析,设成1表示开启,0表示关闭
set profiling=1
-
为最近发送的SQL语句做一个概要的性能分析。展示的条目数目由 profiling_history_size会话变量控制,该变量的默认值为15。最大值为100。将值设置为0具有禁用分析的实际效果。
-
Show profiles 命令
-- 默认展示15条
show profiles
-- 使用profiling_history_size调整展示的条目数
set profiling_history_size = 100;
首先使用
show profiles分析指定查询:

使用show profile进行分析,默认情况下,只展示Status和Duration两列,如果想展示更多信息,可指定type。

使用SHOW PROFILE FOR QUERY 1;,1代表的query_id(show profiles)

展示CPU相关的开销
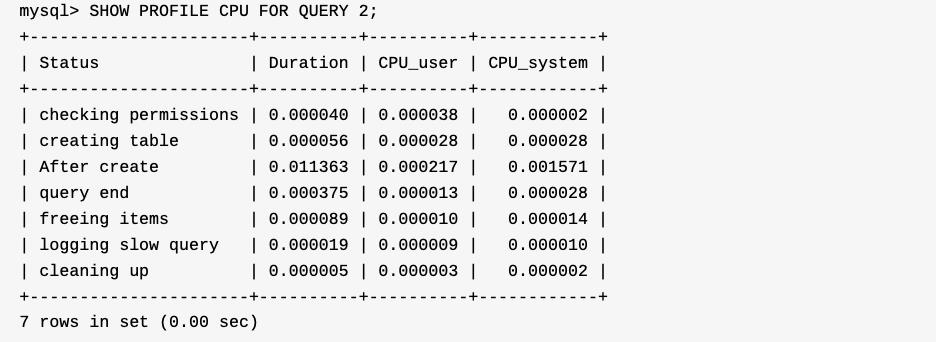
分析完成后,记得关闭掉SHOW PROFILE功能:
set profiling = 1
NFORMATION_SCHEMA.PROFILING
INFORMATION_SCHEMA.PROFILING用来做性能分析,它的内容对应SHOW PROFILE和SHOW PROFILES 语句产生的信息。除非设置了 set profiling = 1; ,否则该表不会有任何数据。
该表包括以下字段:
- QUERY_ID:语句的唯一标识
- SEQ:一个序号,展示具有相同QUERY_ID值的行的显示顺序
- STATE:分析状态
- DURATION:在这个状态下持续了多久(秒)
- CPU_USER,CPU_SYSTEM:用户和系统CPU使用情况(秒)
- CONTEXT_VOLUNTARY,CONTEXT_INVOLUNTARY:发生了多少自愿和非自愿的上下文转换
- BLOCK_OPS_IN,BLOCK_OPS_OUT:块输入和输出操作的数量
- MESSAGES_SENT,MESSAGES_RECEIVED:发送和接收的消息数 PAGE_FAULTS_MAJOR,PAGE_FAULTS_MINOR:主要和次要的⻚错误信息
- SWAPS:发生了多少SWAP SOURCE_FUNCTION,SOURCE_FILE,SOURCE_LINE:当前状态是在源码的哪里执行的
SHOW PROFILE本质上使用的也是INFORMATION_SCHEMA.PROFILING表;
INFORMATION_SCHEMA.PROFILING表已被废弃,在未来可能会被删除。未来将可使用Performance Schema替代,
采用show profile方式进行查询
SHOW PROFILE FOR QUERY 2;
INFORMATION_SCHEMA.PROFILING的查询方式
SELECT STATE, FORMAT(DURATION, 6) AS DURATION FROM INFORMATION_SCHEMA.PROFILING
WHERE QUERY_ID = 2 ORDER BY SEQ;
PERFORMANCE_SCHEMA(未来的继承者)
PERFORMANCE_SCHEMA是MySQL建议的性能分析方式,未来SHOW PROFILE/PROFILES、 INFORMATION_SCHEMA.PROFILING都会废弃。
PERFORMANCE_SCHEMA在MySQL 5.6引入,因此,在MySQL 5.6及更高版本才能使用。可使用 SHOW VARIABLES LIKE ‘performance_schema’;
SHOW VARIABLES LIKE 'performance_schema';
下面来用PERFORMANCE_SCHEMA去实现SHOW PROFILE类似的效果: 查看是否开启性能监控

查看启用情况,MySQL 5.7开始默认启用。
你也可以执行类似如下的SQL语句,只监控指定用户执行的SQL:

这样,就只会监控localhost机器上test_user用户发送过来的SQL。其他主机、其他用户发过来的SQL统统不监控,执行如下SQL语句,开启相关监控项:

使用开启监控的用户,执行SQL语句,比如:

执行如下SQL,获得语句的EVENT_ID。

这一步类似于 SHOW PROFILES。 执行如下SQL语句做性能分析,这样就可以知道这条语句各种阶段的信息了。
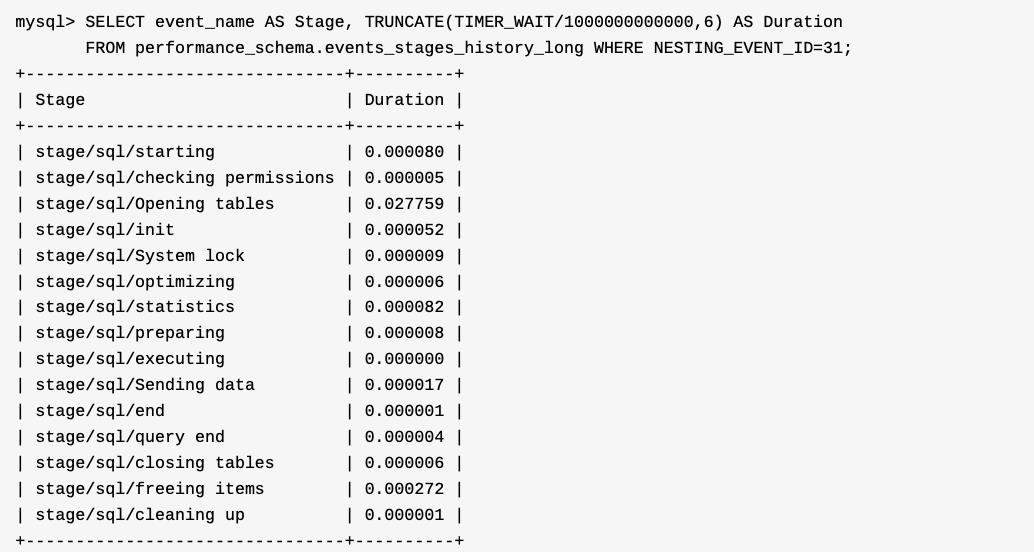
MySQL官方文档声明SHOW PROFILE已被废弃,并建议使用Performance Schema作为替代品。
三种方式对比与选择
- SHOW PROFILE:简单、方便,已废弃
- INFORMATION_SCHEMA.PROFILING,它和SHOW PROFILE本质一样
- PERFORMANCE_SCHEMA:未来之光,但目前来说使用不够方便
因此:目前可以继续用SHOW PROFILE了解PERFORMANCE_SCHEMA,为未来做好准备
OPTIMIZER_TRACE相关参数
- optimizer_trace总开关,默认值: enabled=off,one_line=off enabled:是否开启optimizer_trace;on表示开启,off表示关闭。
- one_line:是否开启单行存储。on表示开启;off表示关闭,将会用标准的JSON格式化存储。设置成on将会有 良好的格式,设置成off可节省一些空间。
- optimizer_trace_features:控制optimizer_trace跟踪的内容,默认
值:greedy_search=on,range_optimizer=on,dynamic_range=on,repeated_subselect=on greedy_search:是否跟踪贪心搜索。 - range_optimizer:是否跟踪范围优化器 dynamic_range:是否跟踪动态范围优化,表示开启所有跟踪项。
- repeated_subselect:是否跟踪子查询,如果设置成off,只跟踪第一条Item_subselect的执行。
- optimizer_trace_limit:控制optimizer_trace展示多少条结果,默认1
- optimizer_trace_max_mem_size:optimizer_trace堆栈信息允许的最大内存,默认1048576
- optimizer_trace_offset:第一个要展示的optimizer trace的偏移量,默认-1。
- end_markers_in_json:如果JSON结构很大,则很难将右括号和左括号配对。为了帮助读者阅读,可将其设置成 on,这样会在右括号附近加上注释,默认off。
总结分析
具体的分析性能介绍后续会在【举世无双的「MySQL调优金字塔」相信也许你拥有了它,你就很可能拥有了全世界。】进行深入介绍,此外还会伴有对索引原理的深入理解和分析。
以上是关于独一无二的「MySQL调优金字塔」相信也许你拥有了它,就再也不用为数据库性能发愁的主要内容,如果未能解决你的问题,请参考以下文章