Hadoop综合项目——二手房统计分析(起始篇)
Posted 7&
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop综合项目——二手房统计分析(起始篇)相关的知识,希望对你有一定的参考价值。
Hadoop综合项目——二手房统计分析(起始篇)
文章目录

0、 写在前面
- Windows版本:
Windows10 - Linux版本:
Ubuntu Kylin 16.04 - JDK版本:
Java8 - Hadoop版本:
Hadoop-2.7.1 - Hive版本:
Hive1.2.2 - IDE:
IDEA 2020.2.3 - IDE:
Pycharm 2021.1.3 - IDE:
Eclipse3.8
1、项目背景与功能
1.1 项目背景
随着经济的发展,北、上、广、深这四大一线城市迅速发展,在经济、政治等方面有突出的表现,而且就业岗位多,生活质量较高,是大多数人所向往的地方。但是定居一线城市并不容易,而购买二手房是一个可以选择的方案,故本项目利用相关二手房信息进行统计分析,进而了解房源基本情况。
1.2 项目功能
统计分析国内四大一线城市二手房的情况,包括房子楼龄、价格、数量、地理位置、优势、面积大小、规格大小等维度,更好地展示二手房的市场趋势,帮助部分人解决购房问题。
2、数据集和数据预处理
2.1 数据集
- 数据来源:
利用后裔采集器爬取工具,对贝壳找房网站爬取北京、上海、广州、深圳四个一线城市的二手房数据信息。
- 数据量:11648

- 数据字段说明:
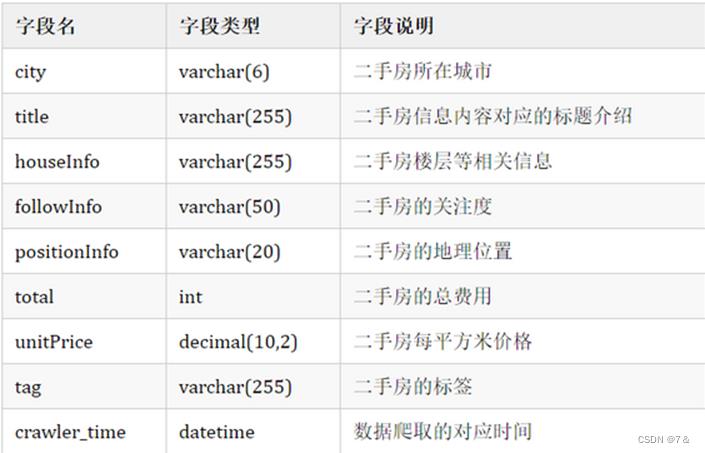
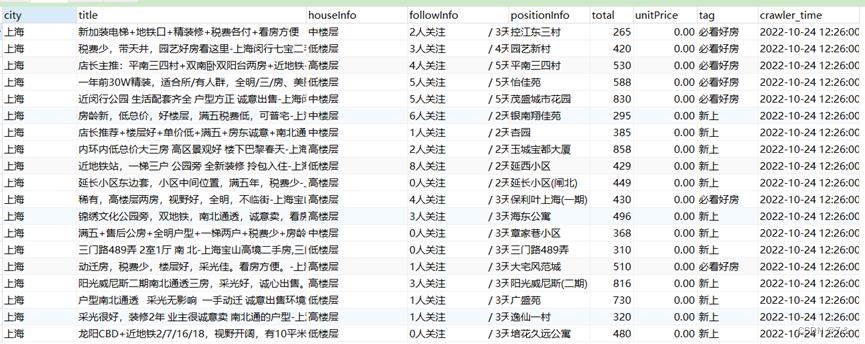
- 原始数据展示:
2.2 数据预处理
数据预处理阶段,本项目是先将爬取的数据直接导入到mysql
(Windows10环境下),接着通过JDBC的方式连接MySQL数据库,对原始数据进行处理。
2.2.1 字段空值处理
- 处理目的:
爬取的数据存在
字段为空的情况,且均属于整条数据(除城市,标签和爬取时间字段外)的字段都为空的情况,导致数据并不适合分析,也没有分析的意义。因此,直接将此种情况的数据剔除掉。
- 具体处理过程:
处理前:各个城市的空值数据条数如下图所示:

- 处理结果:
处理后,空值数据为0条,如下图所示:

2.2.2 无用数据的处理
- 处理目的:
删除没有分析价值的数据,比如下图所示:只有houseInfo、followInfo和total均为空;再比如整条数据都为空的情况。


- 具体处理过程:
直接手动删除掉无用数据
- 处理结果:
证明无用数据已经删除的方法可以通过下文中的【2.2.3 houseInf字段中的空字符处理】来判断。若截取到的
houseInfo中子信息为空,处理houseInf字段中的空字符的程序代码会出现错误,在该程序代码中已经打印出数据处理到哪一个位置,直接根据报错的数据位置,查找对应的无用数据,同时这种数据是个别的,因此在MySQL(Windows10环境下)中将其手动删除即可。
2.2.3 数据重复处理
- 处理目的:
数据重复会影响对于二手房的统计分析,应当提前将
重复数据删除掉。
重复数据如下图所示:

- 具体处理过程:
使用以下的SQL语句查询重复数据的一组id,最终有38组重复的数据,即有19条数据重复。
with th1 as(
select * from tb_house
), th2 as (
select * from tb_house
)
select th1.id id1, th2.id id2 from th1, th2
where th1.title = th2.title and th1.city = th2.city and th1.houseInfo = th2.houseInfo
and th1.followInfo = th2.followInfo and th1.positionInfo = th2.positionInfo
and th1.total = th2.total and th1.unitPrice = th2.unitPrice and th1.tag = th2.tag
and th1.crawler_time = th2.crawler_time and th1.id != th2.id
对于重复数据,直接使用SQL语句删除即可。
delete from tb_house where id = 10108 or id = 8780 or id = 9900 or id = 10858 or id = 10318 or id = 9899 or id = 8798 or id = 6139 or id = 10528 or id = 9988 or id = 11638 or id = 9898 or id = 8794 or id = 9838 or id = 9808 or id = 11458 or id = 9839 or id = 10529 or id = 11128;
- 处理结果:
数据不再有重复的情况,可以通过上述查找重复数据的SQL语句再次确认。
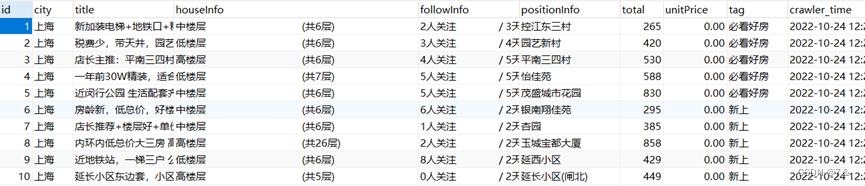
2.2.4 添加id字段
- 处理目的:
作为数据的编号,便于测试分析等。
- 具体处理过程:
直接在MySQL(Windows10环境下)中执行下面的SQL语句,并将id字段设置为主键且设置为自增模式。
alter table tb_house add id int(6);
- 处理结果:
处理后,id字段已经添加成功,如下图所示:
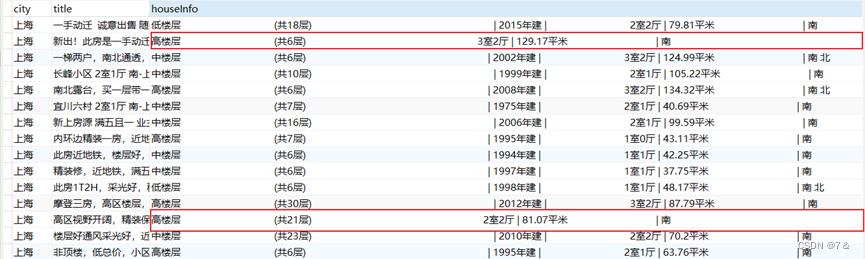
2.2.5 houseInf字段中的空字符处理
- 处理目的:
爬取的数据中houseInfo字段存在
空字符的情况,且每条数据均有此种情况,会导致在MapRedude和Hive数据分析时,造成该字段中信息较难处理以及获取对应子字段信息的后果。因此,此处先通过JDBC的方式处理掉该字段中的空字符。
- 具体处理过程:
处理前,houseInfo字段中的空字符数据展示,如下图所示:

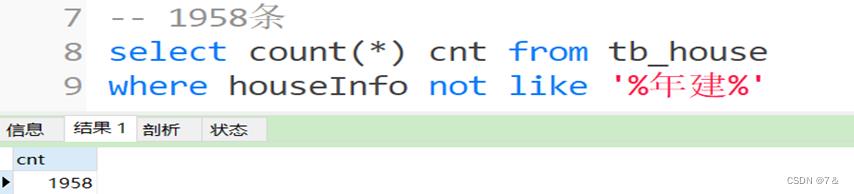
同时,对于该字段中不存在“建造年份”的信息
通过查询可以得知,一共有1958条数据的houseInfo字段中不存在“建造年份”信息,如下图所示:
对于这种情况,需要为这些数据填充未知的建造年份,此处均采用填充
「未透露年份建」的信息,当然也可以使用其他描述信息来填充建造年份,此处考虑到建造年份(如:1992年建)均为6个字符且以「建」字结尾,所以采用了「未透露年份建」来与之相对应填充。
处理完这个情况以及上述的空字符情况之后,需要将该字段以|作为分隔符来分隔houseInfo字段中的各个子信息。即该字段最终的值为「低楼层|共8层|2001年建|3室2厅|104.68平米|东南」。
- 处理结果:
处理后,houseInf字段有关的建造年份信息已经填充完毕且该字段均没有空字符的存在,如下图所示:

2.2.6 followInfo字段中的空字符处理
- 处理目的:
爬取的数据中的followInfo字段存在
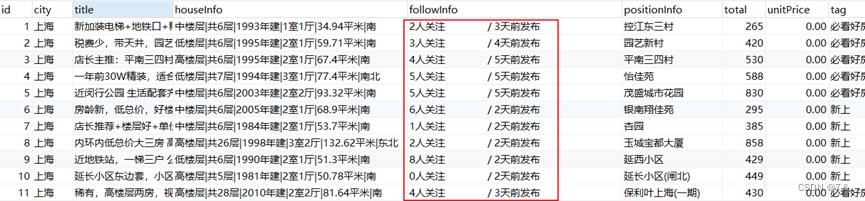
空字符的情况,且每条数据均有此种情况,会导致在MapRedude和Hive数据分析时,造成该字段中信息较难处理以及获取对应子字段信息的后果。因此,此处先通过JDBC的方式处理掉该字段中的空字符。该字段含有的空字符数据如下图所示:

- 具体处理过程:
处理前,houseInf字段中的空字符数据展示,如下图所示:
同样是通过JDBC的方式,先获取到该字段中的子信息(关注数和发布时间),再通过拼接更新该字段。
- 处理结果:如下图所示

2.2.7 title字段中的Tab字符处理
- 处理目的:
对于本项目的MapReduce统计分析阶段,预处理之后的数据是以tab作为每一行数据的分隔符,如若数据的某些字段存在tab字符,那就会影响到MapReduce统计分析中数据字段获取的正确性,从而导致MapReduce的Mapper端数据读取被终止,因此需要提前处理掉这些字段中含有的
tab字符。对于本项目数据预处理到当前阶段而言,只有title字段存在这种特殊情况。
- 具体处理过程:
处理前,title字段中的tab字符数据展示,此种情况如下图所示:

对于此字段的处理,由于这种特殊情况只涉及到id为10931的这一条数据,且title字段的各个子信息(大于1个子信息)之间均以逗号(英文)进行分隔,故可以选择直接在MySQL(Windows10环境下)使用SQL语句直接将tab字符替换成“,”字符,但是此种方式的SQL语句些许麻烦,所以本项目还是采用JDBC的方式进行处理。
- 处理结果:如下图所示


2.2.8 houseInfo字段中的换行符处理
- 处理目的:
由于个别houseInfo字段中存在
\\n字符,会导致在获取二手房面积大小这一信息时,出现错误的现象,因此需要提前这些回车字符。
- 具体处理过程:
处理前,houseInfo字段中存在“\\n”字符数据展示,此种情况如下图所示:
select id, houseinfo from tb_house where houseinfo like '%\\n%'

对于此字段的处理,由于这种特殊情况只涉及到两条数据,故可以选择直接在MySQL(Windows10环境下)使用SQL语句直接删除掉。
- 处理结果:如下图所示
说明:在MySQL中,CHAR(10)表示
换行符,CHAR(13)表示回车符,很明显,此次预处理就是删除掉换行符。
update tb_house set houseinfo = replace(houseInfo, CHAR(10), '')

再次查询,以确保换行符删除完全
select id from tb_house where houseinfo like '%\\n%'
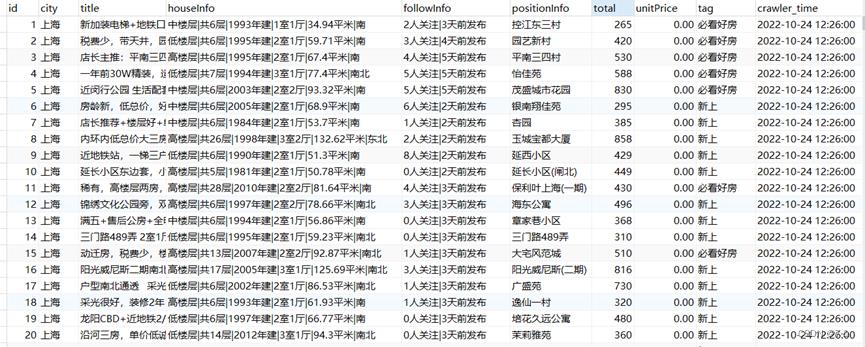
2.2.9 最终数据
3、数据上传
3.1 预处理后的数据上传至HDFS
zhangsan@node01:~ $ hadoop fs -mkdir /Ke_House
zhangsan@node01:~ $ hadoop fs -put ./tb_house.txt /Ke_House
zhangsan@node01:~ $ hadoop fs -ls /Ke_House
Found 1 items
-rw-r--r-- 1 zhangsan supergroup 3385429 2022-11-06 23:48 /Ke_House/tb_house.txt
3.2 数据集展示
最后五条数据

4、数据及源代码
5、总结
对于本项目,数据字段的处理是最繁琐的,字段处理完毕是统计分析的前提,数据如若杂乱、没有规整性,统计分析将毫无意义。通过MapReduce对最值、排序、TopN、自定义分区排序、二次排序、自定义类、占比等8个方面的统计分析,总体上难度不高;本项目的Hive统计分析案例一共有7个,HQL的正确编写是Hive统计分析的关键,尽管本项目的Hive底层查询引擎使用的MR,但是在正确的基础上编写出高效的查询语句是每一个大数据从业者应该追求的。在数据可视化方面,一共是有8张可视化展示图,通过MR和Hive的统计分析结果以及从MySQL的查询结果,一一展示。本项目是对于Hadoop生态课程学习的成果体现,总体上难度不高,收获较多。
结束!
以上是关于Hadoop综合项目——二手房统计分析(起始篇)的主要内容,如果未能解决你的问题,请参考以下文章