大数据练习环境部署 - Hadoop集群部署
Posted OzupeSir
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据练习环境部署 - Hadoop集群部署相关的知识,希望对你有一定的参考价值。
目录
1. 环境配置
1.1 创建hadoop用户
装 Ubuntu 的时候如果不是用的 hadoop 用户,那么需要增加一个名为 hadoop 的用户。(因为后续需要频繁用到用户名)
首先按 ctrl+alt+t 打开终端窗口,
# 创建新用户
sudo adduser hadoop
# 为 hadoop 用户sudo操作权限
sudo usermod -aG sudo hadoop
# 在另外两台机器上做同样的用户创建
1.2 修改相关host
已在上个阶段完成
1.3 ssh免密登陆
这个操作是要让 master 节点可以无密码 SSH 登陆到各个 Slave 节点上。
# 登陆到hadoop用户
su hadoop
# 生成密钥
ssh-keygen -t rsa
# 一直回车即可
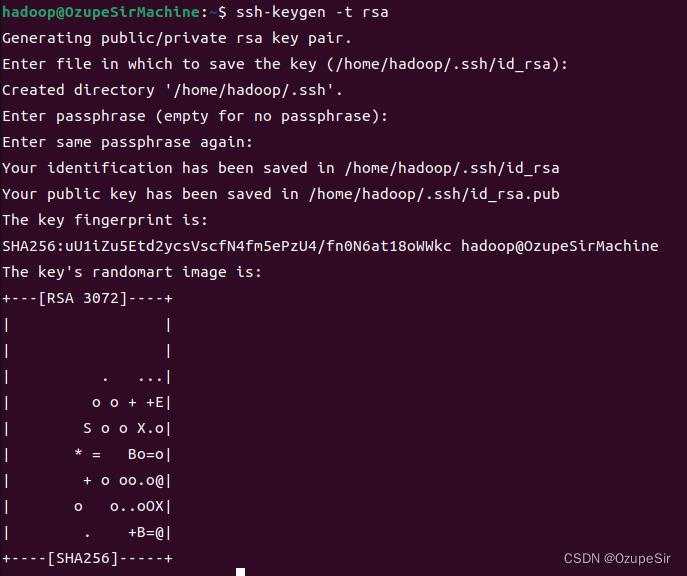
master 节点hadoop用户无密码 ssh 到slave机器上,在 master 节点上执行:
cd ~/.ssh
cat ./id_rsa.pub >> ./authorized_keys
# 完成后可执行 ssh master 验证一下(可能需要输入 yes,成功后执行 ctrl+d 返回原来的终端)。
ssh master
## 在远程机器上创建.ssh文件夹,并分发hadoop 用户 在 master节点上的公钥到slave1和slave2上,
scp ~/.ssh/id_rsa.pub hadoop@slave1:~/id_rsa.pub
ssh hadoop@slave1 'mkdir ~/.ssh;cat ~/id_rsa.pub >> ~/.ssh/authorized_keys;rm ~/id_rsa.pub;chmod 700 ~/.ssh;chmod 600 ~/.ssh/authorized_keys'
scp ~/.ssh/id_rsa.pub hadoop@slave2:~/id_rsa.pub
ssh hadoop@slave2 'mkdir ~/.ssh;cat ~/id_rsa.pub >> ~/.ssh/authorized_keys;rm ~/id_rsa.pub;chmod 700 ~/.ssh;chmod 600 ~/.ssh/authorized_keys'
2. JAVA安装
2.1 下载JDK1.8
下载地址:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
Q:以前疑惑的一个问题,java17 19 都出来了,为什么还要用1.8,版本之间有什么关系:
java从5开始就是Java5,java6,java7,java8这样命名,
java5之前都是java1,java1.2,java1.3,java1.4这样命名,
到了5,发行公司感觉有革命性的变化,就开始5,6,7,8这样命名,实际上java1.8也就是java8
根据CPU类型选择下载链接:
CPU判断Linux 中的i386,i486,i586,i686和AMD_64,X86,x86_64后缀的区别
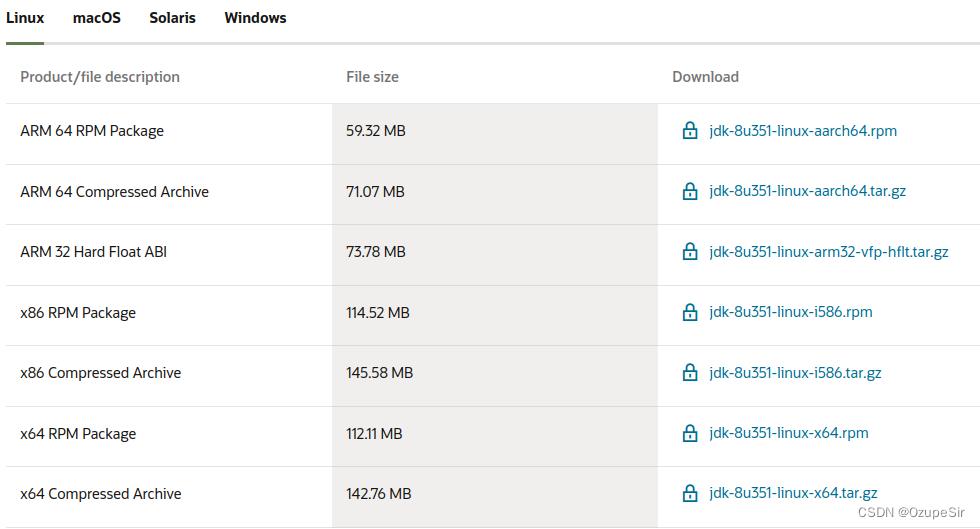 一般选
一般选tar.gz文件,另外,我的CPU是X64
2.2 解压安装java
# ctrl+d 退回原始用户安装,避免权限太高等问题
cd /opt/
mkdir java
tar -zxvf jdk-8u351-linux-x64.tar.gz -C ./java/
# 做个链接方便以后有时候更换
ln -s jdk1.8.0_351 jdk8
# 修改全局环境变量
sudo vim /etc/profile
# 对应添加如下内容
## # java
## export JAVA_HOME=/opt/java/jdk8
## export JRE_HOME=$JAVA_HOME/jre
## export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
## export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
# 退出后更新下环境变量
source /etc/profile
# java验证
java -version
# 如果能出现下面的信息,即表示完成
# java version "1.8.0_351"
# Java(TM) SE Runtime Environment (build 1.8.0_351-b10)
# Java HotSpot(TM) 64-Bit Server VM (build 25.351-b10, mixed mode)
2.3 分发到其他节点
xsync /opt/java
关于xsync,可以参考xsync同步脚本的创建及使用(以Debian10集群为例)
Tips:根据个人情况修改命令行中的主机名称
2.4 安装过程中遇到的问题
2.4.1 切换到其他用户验证时, PATH环境变量未生效
方法一 增加环境变量参数
登陆系统时shell读取的顺序应该是
/etc/profile ->/etc/environment --> ~/.profile --> ~/.env
所以有可能在/etc/profile中设置环境变量后,被/etc/environment中的环境变量覆盖了
# 查看/etc/environment,可看到
cat /etc/environment
# PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games"
# 将内容修改为:
PATH="$PATH/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games"
为什么/etc/profile 中的环境变量重启后失效了 https://blog.csdn.net/my_wings/article/details/102617631
方法二 注释环境变量
如果方法一对$PATH不生效,则需要 /etc/environment 中的内容注释掉
# PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games"
说明:以上两种情况都遇到过!
3. Hadoop安装
3.1 下载Hadoop
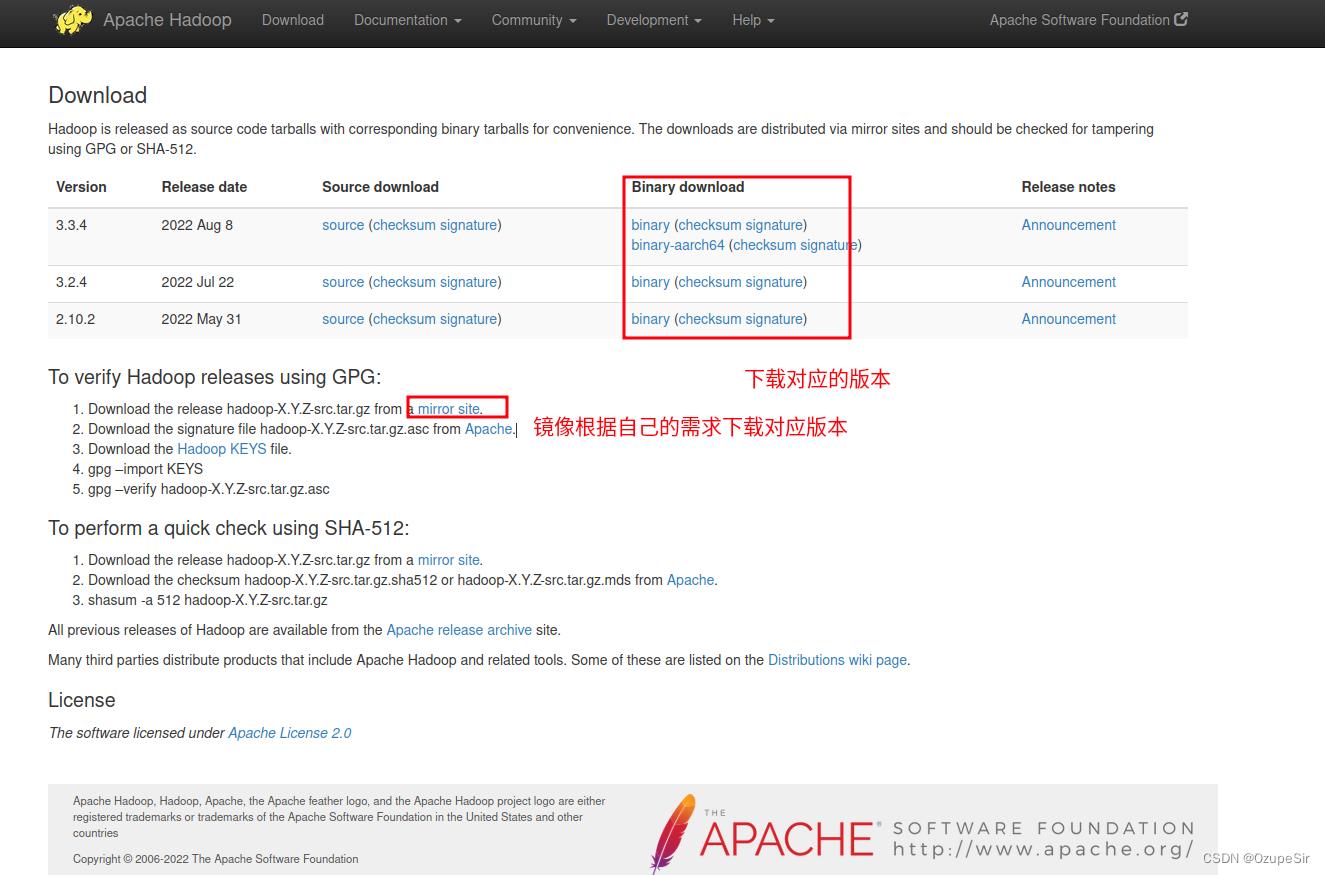
3.2 解压到合适的目录
# 我一般会把软件安装到opt下面
cd /opt
mkdir hadoop
# 解压到合适的路径
tar -zxvf hadoop-3.3.4.tar.gz -C ./hadoop/
# 创链接
cd hadoop
ln -s hadoop-3.3.4/ hadoop
# 删除安装报1
rm -f ../hadoop-3.3.4.tar.gz
# 为了方便操作,将hadoop文件夹的用户和组进行修改
sudo chown -R hadoop:hadoop ./hadoop/
# 可以验证解压情况
./hadoop/hadoop/bin/hadoop version
# Hadoop 3.3.4
# Source code repository https://github.com/apache/hadoop.git -ra585a73c3e02ac62350c136643a5e7f6095a3dbb
# Compiled by stevel on 2022-07-29T12:32Z
# Compiled with protoc 3.7.1
# From source with checksum fb9dd8918a7b8a5b430d61af858f6ec
# This command was run using /opt/hadoop/hadoop-3.3.4/share/hadoop/common/hadoop-common-3.3.4.jar
3.3 修改环境变量
sudo vim /etc/profile
# 增加下面的内容
# hadoop
export HADOOP_HOME=/opt/hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# source 下环境变量生效
source /etc/profile
3.4 修改配置文件
# 切换到hadoop用户开始修改配置文件
su hadoop
cd ./hadoop/hadoop/etc/hadoop
可以安装一个sublime(ubuntu software里面就有),通过sublime编辑器来配置环境变量会方便一些(SFTP/FTP)
3.4.1 修改hadoop-env.sh
vim hadoop-env.sh
# 增加下面的环境变量内容
export JAVA_HOME=/opt/java/jdk8
3.4.2 修改core-site.xml
vim core-sites.xml
<!-- 在配置信息中添加如下内容 -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop/tmp</value>
<!--临时文件保存路径。不需要我们提前建好文件夹,如果没有,格式化名称节点时会自动创建-->
</property>
</configuration>
3.4.3 修改hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<!--对于Hadoop的分布式文件系统HDFS而言,一般都是采用冗余存储,冗余因子通常为3,也就是说,一份数据保存三份副本-->
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/hadoop/tmp/dfs/name</value>
<!--不需要提前建好文件夹,如果没有,格式化名称节点时会自动创建-->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/hadoop/tmp/dfs/data</value>
<!--不需要提前建好文件夹,如果没有,格式化名称节点时会自动创建-->
</property>
<!-- <property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property> -->
</configuration>
3.4.4 修改mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
3.4.5 修改yarn-site.xml
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
<!-- yarn的可视化界面web地址-->
</property>
<!-- Site specific YARN configuration properties -->
</configuration>
3.4.6 workers
vim workers
slave1
slave2
3.5 分发到其他节点
xsync /opt/hadoop/
3.6 启动、验证、关闭
3.6.1 格式化
首次启动需要先在 master 节点执行 NameNode 的格式化:
hdfs namenode -format
3.6.2 启动
start-all.sh
## 10秒启动
# WARNING: Attempting to start all Apache Hadoop daemons as hadoop in 10 seconds.
# WARNING: This is not a recommended production deployment configuration.
# WARNING: Use CTRL-C to abort.
# Starting namenodes on [master]
# Starting datanodes
# Starting secondary namenodes [OzupeSirMachine]
# Starting resourcemanager
# Starting nodemanagers
3.6.3 验证
3.6.3.1 jps
通过jps命令可以查到各个节点启动的进程
# 在master节点上可以看到如下任务:
# Jps
30951 Jps
23128 SecondaryNameNode
22731 NameNode
23405 ResourceManager
# 在slave节点上可以看到如下任务:
1826 Jps
1734 NodeManager
1607 DataNode
3.6.3.2 通过hdfs命令查看
hdfs dfsadmin -report
# 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。
Configured Capacity: 39792705536 (37.06 GB)
Present Capacity: 19667972096 (18.32 GB)
DFS Remaining: 19667914752 (18.32 GB)
DFS Used: 57344 (56 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.245.129:9866 (slave1)
Hostname: slave1
Decommission Status : Normal
Configured Capacity: 19896352768 (18.53 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 9017446400 (8.40 GB)
DFS Remaining: 9842262016 (9.17 GB)
DFS Used%: 0.00%
DFS Remaining%: 49.47%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Thu Dec 22 09:50:00 UTC 2022
Last Block Report: Thu Dec 22 09:49:39 UTC 2022
Num of Blocks: 0
Name: 192.168.245.130:9866 (slave2)
Hostname: slave2
Decommission Status : Normal
Configured Capacity: 19896352768 (18.53 GB)
DFS Used: 32768 (32 KB)
Non DFS Used: 9034047488 (8.41 GB)
DFS Remaining: 9825652736 (9.15 GB)
DFS Used%: 0.00%
DFS Remaining%: 49.38%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Thu Dec 22 09:50:00 UTC 2022
Last Block Report: Thu Dec 22 09:49:39 UTC 2022
Num of Blocks: 0
3.6.3.3 web端验证
yarn web :http://master:8088
说明:通过修改 yarn-site.xml更改端口
hdfs web :http://master:9870
说明:通过修改 hdfs-site.xml更改端口
3.6.3.4WordCount测试
# 文件验证
cd /opt/hadoop/hadoop
# hdfs创建文件夹
hdfs dfs -mkdir -p /usr/hadoop/tmp/conf
# hdfs上传文件
hdfs dfs -put etc/hadoop/*-site.xml /user/hadoop/tmp/conf
3.6.4 关闭
stop-all.sh
以上是关于大数据练习环境部署 - Hadoop集群部署的主要内容,如果未能解决你的问题,请参考以下文章